После изучения данных с помощью статистических и визуализирующих методов, вам следует преобразовать данные способами, которые помогут вашей модели обучаться более эффективно. Цель нормализации — преобразовать признаки так, чтобы они находились в схожем масштабе. Например, рассмотрим следующие два признака:
- Характеристика
Xохватывает диапазон от 154 до 24 917 482. - Характеристика
Yохватывает диапазон от 5 до 22.
Эти две функции охватывают очень разные диапазоны. Нормализация может манипулировать X и Y так, чтобы они охватывали похожий диапазон, возможно, от 0 до 1.
Нормализация обеспечивает следующие преимущества:
- Помогает моделям сходиться быстрее во время обучения. Когда разные признаки имеют разные диапазоны, градиентный спуск может «отскакивать» и замедлять сходимость. Тем не менее, более продвинутые оптимизаторы, такие как Adagrad и Adam, защищают от этой проблемы, изменяя эффективную скорость обучения с течением времени.
- Помогает моделям делать более точные прогнозы . Когда разные характеристики имеют разные диапазоны, результирующая модель может делать несколько менее полезные прогнозы.
- Помогает избежать «ловушки NaN» , когда значения признаков очень высоки. NaN — это аббревиатура для not a number (не число) . Когда значение в модели превышает предел точности с плавающей точкой, система устанавливает значение
NaNвместо числа. Когда одно число в модели становится NaN, другие числа в модели также в конечном итоге становятся NaN. - Помогает модели выучить соответствующие веса для каждого признака. Без масштабирования признаков модель уделяет слишком много внимания признакам с широкими диапазонами и недостаточно внимания признакам с узкими диапазонами.
Мы рекомендуем нормализовать числовые характеристики, охватывающие совершенно разные диапазоны (например, возраст и доход). Мы также рекомендуем нормализовать одну числовую характеристику, охватывающую широкий диапазон, например, city population.
Рассмотрим следующие две особенности:
- Наименьшее значение признака
Aравно -0,5, а наибольшее — +0,5. - Наименьшее значение признака
Bравно -5,0, а наибольшее — +5,0.
Feature A и Feature B имеют относительно узкие пролеты. Однако пролет Feature B в 10 раз шире пролета Feature A Поэтому:
- В начале обучения модель предполагает, что признак
Bв десять раз «важнее», чем признакA - Обучение займет больше времени, чем следовало бы.
- Полученная модель может оказаться неоптимальной.
Общий ущерб из-за отсутствия нормализации будет относительно небольшим; однако мы все равно рекомендуем нормализовать функцию A и функцию B до одинакового масштаба, возможно, от -1,0 до +1,0.
Теперь рассмотрим две характеристики с большим разбросом диапазонов:
- Наименьшее значение признака
Cравно -1, а наибольшее — +1. - Наименьшее значение признака
Dсоставляет +5000, а наибольшее — +1 000 000 000.
Если вы не нормализуете Feature C и Feature D , ваша модель, скорее всего, будет неоптимальной. Более того, обучение займет гораздо больше времени, чтобы сойтись, или даже не сойтись полностью!
В этом разделе рассматриваются три популярных метода нормализации:
- линейное масштабирование
- Масштабирование Z-оценки
- логарифмическое масштабирование
В этом разделе дополнительно рассматривается отсечение . Хотя это и не истинный метод нормализации, отсечение укрощает неуправляемые числовые признаки в диапазоны, которые создают лучшие модели.
Линейное масштабирование
Линейное масштабирование (чаще сокращается до просто масштабирования ) означает преобразование значений с плавающей точкой из их естественного диапазона в стандартный диапазон — обычно от 0 до 1 или от -1 до +1.
Линейное масштабирование является хорошим выбором, когда выполняются все следующие условия:
- Нижние и верхние границы ваших данных не сильно меняются со временем.
- Функция содержит мало или совсем не содержит выбросов, и эти выбросы не являются экстремальными.
- Функция приблизительно равномерно распределена по всему диапазону. То есть гистограмма будет показывать примерно ровные столбцы для большинства значений.
Предположим, что age человека — это признак. Линейное масштабирование — хороший метод нормализации age , потому что:
- Приблизительные нижняя и верхняя границы составляют от 0 до 100.
-
ageсодержит относительно небольшой процент выбросов. Только около 0,3% населения старше 100 лет. - Хотя некоторые возрастные группы представлены лучше, чем другие, большой набор данных должен содержать достаточно примеров всех возрастов.
Упражнение: проверьте свое понимание
Предположим, что в вашей модели есть признакnet_worth , который содержит чистую стоимость разных людей. Будет ли линейное масштабирование хорошим методом нормализации для net_worth ? Почему или почему нет? Масштабирование Z-оценки
Z-оценка — это количество стандартных отклонений значения от среднего. Например, значение, которое на 2 стандартных отклонения больше среднего, имеет Z-оценку +2,0. Значение, которое на 1,5 стандартных отклонения меньше среднего, имеет Z-оценку -1,5.
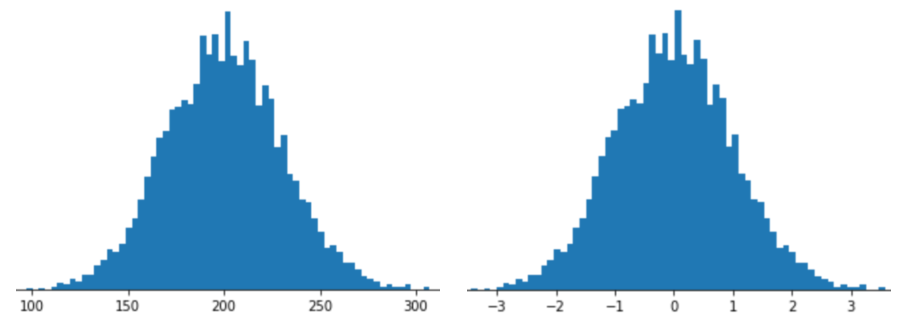
Представление функции с масштабированием Z-оценки означает сохранение Z-оценки этой функции в векторе функций. Например, на следующем рисунке показаны две гистограммы:
- Слева — классическое нормальное распределение.
- Справа — то же распределение, нормализованное по шкале Z-оценки.
Шкалирование Z-оценки также является хорошим выбором для данных, подобных показанным на следующем рисунке, которые имеют лишь приблизительно нормальное распределение.
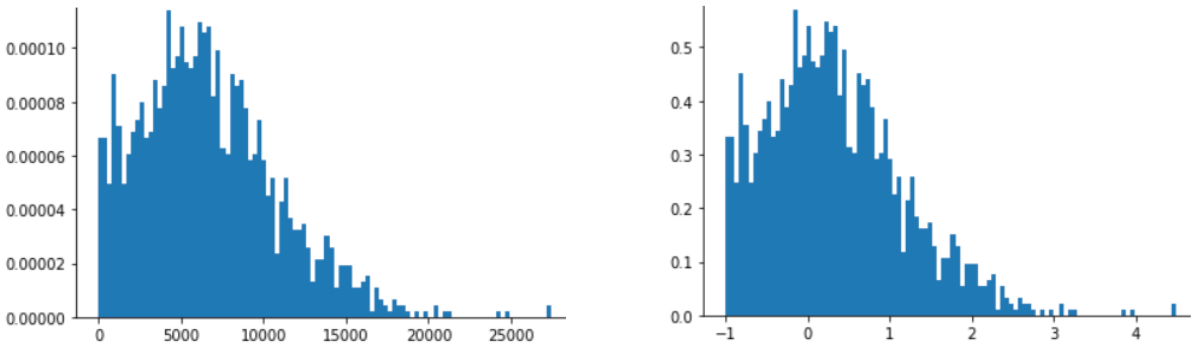
Z-оценка является хорошим выбором, когда данные подчиняются нормальному распределению или распределению, несколько похожему на нормальное распределение.
Обратите внимание, что некоторые распределения могут быть нормальными в пределах своего диапазона, но все равно содержать экстремальные выбросы. Например, почти все точки в функции net_worth могут аккуратно вписываться в 3 стандартных отклонения, но несколько примеров этой функции могут находиться в сотнях стандартных отклонений от среднего значения. В таких ситуациях вы можете объединить масштабирование Z-оценки с другой формой нормализации (обычно с отсечением), чтобы справиться с этой ситуацией.
Упражнение: проверьте свое понимание
Предположим, что ваша модель тренируется на признаке с именемheight , который содержит рост взрослых десяти миллионов женщин. Будет ли масштабирование Z-оценки хорошим методом нормализации для height ? Почему или почему нет? Логарифмическое масштабирование
Логарифмическое масштабирование вычисляет логарифм исходного значения. Теоретически логарифм может иметь любое основание; на практике логарифмическое масштабирование обычно вычисляет натуральный логарифм (ln).
Логарифмическое масштабирование полезно, когда данные соответствуют распределению степенного закона . Грубо говоря, распределение степенного закона выглядит следующим образом:
- Низкие значения
Xимеют очень высокие значенияY - По мере увеличения значений
XзначенияYбыстро уменьшаются. Следовательно, высокие значенияXимеют очень низкие значенияY
Рейтинги фильмов являются хорошим примером распределения степенного закона. Обратите внимание на следующий рисунок:
- Некоторые фильмы имеют много оценок пользователей. (Низкие значения
Xимеют высокие значенияY) - Большинство фильмов имеют очень мало оценок пользователей. (Высокие значения
Xимеют низкие значенияY)
Логарифмическое масштабирование изменяет распределение, что помогает обучить модель, которая будет делать более точные прогнозы.

В качестве второго примера, продажи книг подчиняются степенному закону распределения, потому что:
- Большинство изданных книг продаются тиражом в одну-две сотни экземпляров.
- Тираж некоторых книг составляет несколько тысяч экземпляров.
- Лишь немногие бестселлеры разойдутся тиражом более миллиона экземпляров.
Предположим, вы обучаете линейную модель, чтобы найти связь, скажем, между обложками книг и продажами книг. Линейная модель, обучаемая на сырых значениях, должна была бы найти что-то об обложках книг, которые продаются миллионным тиражом, что в 10 000 раз мощнее, чем обложки книг, которые продаются всего 100 экземплярами. Однако логарифмическое масштабирование всех показателей продаж делает задачу гораздо более выполнимой. Например, логарифм 100 равен:
~4.6 = ln(100)
в то время как логарифм числа 1 000 000 равен:
~13.8 = ln(1,000,000)
Итак, логарифм 1 000 000 всего лишь в три раза больше логарифма 100. Вы, вероятно, можете себе представить, что обложка бестселлера примерно в три раза более влиятельна (в каком-то смысле), чем обложка малораспродаваемой книги.
Вырезка
Отсечение — это метод минимизации влияния экстремальных выбросов. Вкратце, отсечение обычно ограничивает (снижает) значение выбросов до определенного максимального значения. Отсечение — странная идея, и тем не менее, оно может быть очень эффективным.
Например, представьте набор данных, содержащий признак с именем roomsPerPerson , который представляет собой количество комнат (общее количество комнат, деленное на количество жильцов) для различных домов. Следующий график показывает, что более 99% значений признака соответствуют нормальному распределению (примерно, среднее значение 1,8 и стандартное отклонение 0,7). Однако признак содержит несколько выбросов, некоторые из которых экстремальны:
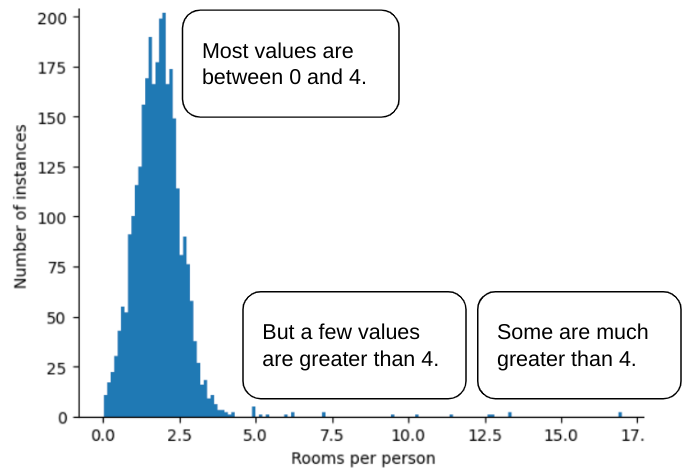
Как можно минимизировать влияние этих экстремальных выбросов? Ну, гистограмма не является равномерным распределением, нормальным распределением или распределением по степенному закону. Что, если вы просто ограничите или обрежете максимальное значение roomsPerPerson произвольным значением, скажем, 4.0?
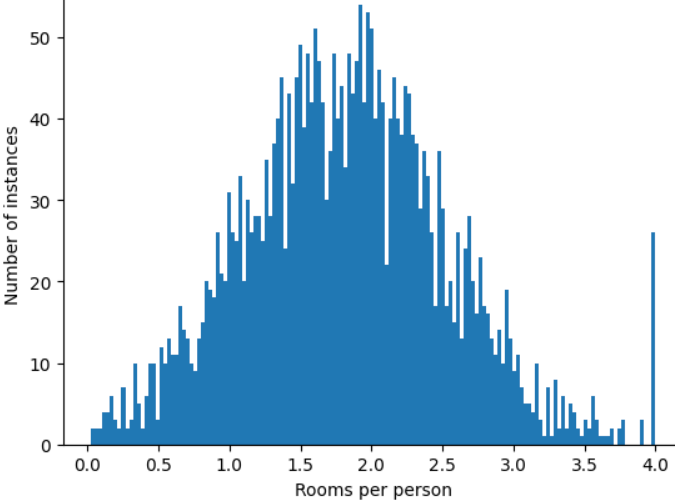
Отсечение значения признака на уровне 4,0 не означает, что ваша модель игнорирует все значения больше 4,0. Скорее, это означает, что все значения, которые были больше 4,0, теперь становятся 4,0. Это объясняет странный холм на уровне 4,0. Несмотря на этот холм, масштабированный набор признаков теперь более полезен, чем исходные данные.
Подождите секунду! Можно ли действительно уменьшить каждое значение выброса до некоторого произвольного верхнего порога? При обучении модели — да.
Вы также можете обрезать значения после применения других форм нормализации. Например, предположим, что вы используете масштабирование Z-оценки, но несколько выбросов имеют абсолютные значения, намного превышающие 3. В этом случае вы можете:
- Обрежьте Z-оценки больше 3, чтобы они стали ровно 3.
- Обрежьте Z-оценки менее -3 до значения ровно -3.
Отсечение предотвращает переиндексацию вашей модели на неважных данных. Однако некоторые выбросы на самом деле важны, поэтому отсечение значений следует выполнять осторожно.
Краткое изложение методов нормализации
| Метод нормализации | Формула | Когда использовать |
|---|---|---|
| Линейное масштабирование | $$ x' = \frac{x - x_{min}}{x_{max} - x_{min}} $$ | Когда признак в основном равномерно распределен по всему диапазону. |
| Масштабирование Z-оценки | $$ x' = \frac{x - μ}{σ}$$ | Когда признак распределен нормально (пик близок к среднему значению). Колоколообразный |
| Логарифмическое масштабирование | $$ x' = log(x)$$ | Когда распределение признаков сильно перекошено по крайней мере с обеих сторон хвоста. Тяжелый хвост в форме |
| Вырезка | Если $x > max$, устанавливаем $x' = max$ Если $x < min$, устанавливаем $x' = min$ | Когда признак содержит экстремальные выбросы. |
Упражнение: проверьте свои знания

Предположим, вы разрабатываете модель, которая прогнозирует производительность центра обработки данных на основе температуры, измеренной внутри центра обработки данных. Почти все значения temperature в вашем наборе данных находятся в диапазоне от 15 до 30 (по Цельсию), за исключением следующих:
- Один или два раза в год в особенно жаркие дни регистрируются несколько значений
temperatureот 31 до 45 градусов. - Каждая тысячная точка
temperatureпринимается за 1000, а не за фактическую температуру.
Какой метод нормализации temperature будет разумным?
Значения 1000 являются ошибками и должны быть удалены, а не обрезаны.
Значения между 31 и 45 являются допустимыми точками данных. Отсечение, вероятно, будет хорошей идеей для этих значений, предполагая, что набор данных не содержит достаточно примеров в этом диапазоне температур для обучения модели делать хорошие прогнозы. Однако во время вывода обратите внимание, что отсеченная модель, следовательно, сделает тот же прогноз для температуры 45, что и для температуры 35.