Setelah memeriksa data melalui teknik statistik dan visualisasi, Anda harus mengubah data dengan cara yang akan membantu model Anda berlatih lebih efektif. Tujuan normalisasi adalah mengubah fitur agar berada pada skala yang sama. Misalnya, pertimbangkan dua fitur berikut:
- Fitur
Xmencakup rentang 154 hingga 24.917.482. - Fitur
Ymencakup rentang 5 hingga 22.
Kedua fitur ini mencakup rentang yang sangat berbeda. Normalisasi dapat memanipulasi
X dan Y sehingga mencakup rentang yang serupa, mungkin 0 hingga 1.
Normalisasi memberikan manfaat berikut:
- Membantu model menyatu lebih cepat selama pelatihan. Jika rentang fitur berbeda, penurunan gradien dapat "memantul" dan memperlambat konvergensi. Namun, pengoptimal yang lebih canggih seperti Adagrad dan Adam melindungi dari masalah ini dengan mengubah laju pembelajaran efektif dari waktu ke waktu.
- Membantu model menyimpulkan prediksi yang lebih baik. Jika rentang fitur berbeda-beda, model yang dihasilkan mungkin membuat prediksi yang kurang berguna.
- Membantu menghindari "perangkap NaN" saat nilai fitur sangat tinggi.
NaN adalah singkatan dari
not a number (bukan angka). Jika nilai dalam model melebihi batas presisi floating point, sistem akan menetapkan nilai ke
NaN, bukan angka. Saat satu angka dalam model menjadi NaN, angka lain dalam model juga akan menjadi NaN. - Membantu model mempelajari bobot yang sesuai untuk setiap fitur. Tanpa penskalaan fitur, model akan terlalu memperhatikan fitur dengan rentang yang luas dan tidak cukup memperhatikan fitur dengan rentang yang sempit.
Sebaiknya lakukan normalisasi fitur numerik yang mencakup rentang yang sangat berbeda (misalnya, usia dan pendapatan).
Sebaiknya juga lakukan normalisasi pada satu fitur numerik yang mencakup rentang luas, seperti city population.
Pertimbangkan dua fitur berikut:
- Nilai terendah fitur
Aadalah -0,5 dan nilai tertinggi adalah +0,5. - Nilai terendah fitur
Badalah -5,0 dan nilai tertinggi adalah +5,0.
Rentang Fitur A dan Fitur B relatif sempit. Namun, rentang Fitur B 10 kali lebih lebar daripada rentang Fitur A. Jadi:
- Di awal pelatihan, model mengasumsikan bahwa Fitur
Bsepuluh kali lebih "penting" daripada FiturA. - Pelatihan akan memakan waktu lebih lama dari yang seharusnya.
- Model yang dihasilkan mungkin kurang optimal.
Kerusakan keseluruhan karena tidak menormalisasi akan relatif kecil; namun, kami tetap merekomendasikan untuk menormalisasi Fitur A dan Fitur B ke skala yang sama, mungkin -1,0 hingga +1,0.
Sekarang pertimbangkan dua fitur dengan perbedaan rentang yang lebih besar:
- Nilai terendah fitur
Cadalah -1 dan nilai tertinggi adalah +1. - Nilai terendah fitur
Dadalah +5.000 dan nilai tertinggi adalah +1.000.000.000.
Jika Anda tidak menormalisasi Fitur C dan Fitur D, model Anda kemungkinan akan
menjadi tidak optimal. Selain itu, pelatihan akan memerlukan waktu yang lebih lama untuk
berkonvergensi atau bahkan gagal berkonvergensi sama sekali.
Bagian ini membahas tiga metode normalisasi populer:
- penskalaan linear
- Penskalaan skor Z
- penskalaan log
Bagian ini juga membahas kliping. Meskipun bukan teknik normalisasi yang sebenarnya, pembatasan dapat mengendalikan fitur numerik yang tidak teratur ke dalam rentang yang menghasilkan model yang lebih baik.
Skala linier
Penskalaan linear (lebih umum disingkat menjadi penskalaan) berarti mengonversi nilai floating point dari rentang alaminya ke dalam rentang standar—biasanya 0 hingga 1 atau -1 hingga +1.
Penskalaan linear adalah pilihan yang baik jika semua kondisi berikut terpenuhi:
- Batas bawah dan atas data Anda tidak banyak berubah dari waktu ke waktu.
- Fitur berisi sedikit atau tidak ada pencilan, dan pencilan tersebut tidak ekstrem.
- Fitur ini didistribusikan secara seragam di seluruh rentangnya. Artinya, histogram akan menampilkan batang yang hampir sama untuk sebagian besar nilai.
Misalkan age manusia adalah sebuah fitur. Penskalaan linear adalah teknik normalisasi yang baik untuk age karena:
- Batas bawah dan atas perkiraan adalah 0 hingga 100.
ageberisi persentase pencilan yang relatif kecil. Hanya sekitar 0,3% populasi yang berusia di atas 100 tahun.- Meskipun usia tertentu lebih terwakili daripada usia lainnya, set data yang besar harus berisi contoh yang cukup dari semua usia.
Latihan: Periksa pemahaman Anda
Misalkan model Anda memiliki fitur bernamanet_worth yang menyimpan kekayaan bersih orang yang berbeda. Apakah penskalaan linear akan menjadi teknik normalisasi yang baik untuk net_worth? Mengapa atau mengapa tidak?
Penskalaan skor Z
Skor Z adalah jumlah simpangan baku suatu nilai dari rata-rata. Misalnya, nilai yang memiliki 2 standar deviasi lebih besar daripada rata-rata memiliki skor Z +2,0. Nilai yang 1,5 standar deviasi lebih kecil daripada rata-rata memiliki skor Z -1,5.
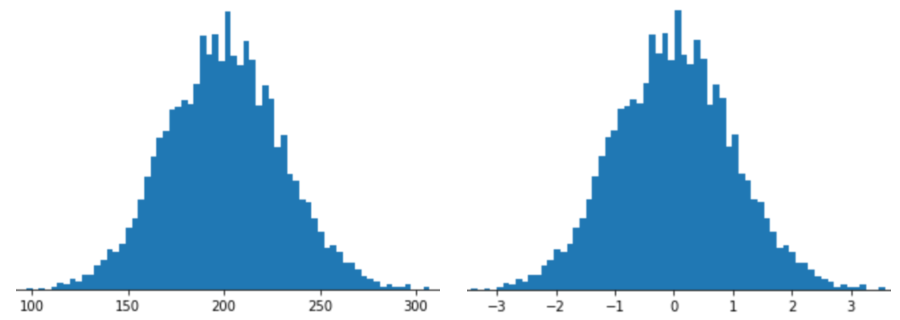
Merepresentasikan fitur dengan penskalaan skor Z berarti menyimpan skor Z fitur tersebut dalam vektor fitur. Misalnya, gambar berikut menunjukkan dua histogram:
- Di sebelah kiri, distribusi normal klasik.
- Di sebelah kanan, distribusi yang sama dinormalisasi dengan penskalaan skor Z.
Penskalaan skor Z juga merupakan pilihan yang baik untuk data seperti yang ditunjukkan pada gambar berikut, yang hanya memiliki distribusi normal yang tidak jelas.
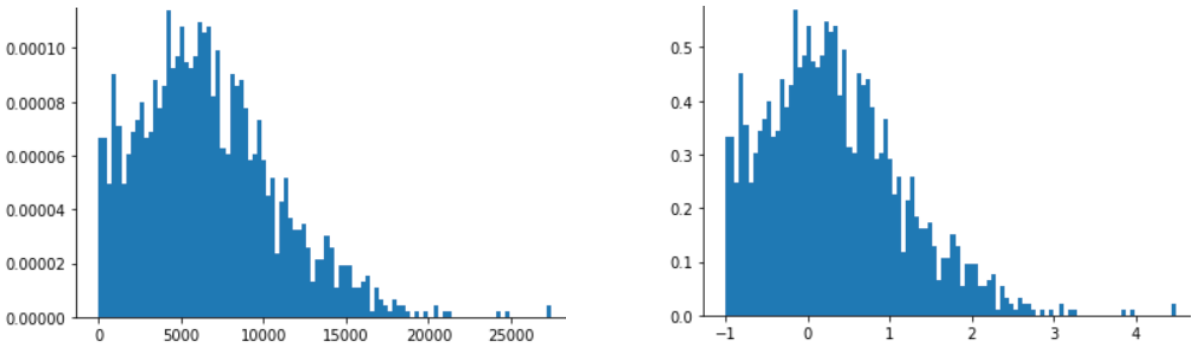
Skor Z adalah pilihan yang baik jika data mengikuti distribusi normal atau distribusi yang agak mirip dengan distribusi normal.
Perhatikan bahwa beberapa distribusi mungkin normal dalam sebagian besar rentangnya, tetapi masih berisi pencilan ekstrem. Misalnya, hampir semua titik dalam fitur net_worth mungkin cocok dengan 3 simpangan baku, tetapi beberapa contoh fitur ini bisa beratus-ratus simpangan baku dari rata-rata. Dalam situasi ini, Anda dapat menggabungkan penskalaan skor Z dengan bentuk normalisasi lain (biasanya pemangkasan) untuk menangani situasi ini.
Latihan: Periksa pemahaman Anda
Misalkan model Anda dilatih pada fitur bernamaheight yang menyimpan tinggi badan orang dewasa dari sepuluh juta perempuan. Apakah penskalaan skor Z merupakan teknik normalisasi yang baik untuk height? Mengapa atau mengapa tidak?
Penskalaan log
Penskalaan log menghitung logaritma nilai mentah. Secara teori, logaritma dapat berupa basis apa pun; dalam praktiknya, penskalaan log biasanya menghitung logaritma natural (ln).
Penskalaan log berguna saat data sesuai dengan distribusi hukum pangkat. Secara umum, distribusi hukum pangkat terlihat sebagai berikut:
- Nilai
Xyang rendah memiliki nilaiYyang sangat tinggi. - Seiring meningkatnya nilai
X, nilaiYakan menurun dengan cepat. Akibatnya, nilaiXyang tinggi memiliki nilaiYyang sangat rendah.
Rating film adalah contoh yang baik dari distribusi hukum pangkat. Pada gambar berikut, perhatikan:
- Beberapa film memiliki banyak rating pengguna. (Nilai
Xyang rendah memiliki nilaiYyang tinggi.) - Sebagian besar film memiliki rating pengguna yang sangat sedikit. (Nilai
Xyang tinggi memiliki nilaiYyang rendah.)
Penskalaan log mengubah distribusi, yang membantu melatih model yang akan membuat prediksi yang lebih baik.

Sebagai contoh kedua, penjualan buku sesuai dengan distribusi hukum pangkat karena:
- Sebagian besar buku yang diterbitkan hanya terjual dalam jumlah kecil, mungkin seratus atau dua ratus eksemplar.
- Beberapa buku menjual sejumlah salinan sedang, dalam ribuan.
- Hanya beberapa buku terlaris yang akan terjual lebih dari satu juta eksemplar.
Misalnya, Anda melatih model linear untuk menemukan hubungan antara, misalnya, sampul buku dengan penjualan buku. Model linear yang dilatih pada nilai mentah harus menemukan sesuatu tentang sampul buku pada buku yang terjual satu juta eksemplar yang 10.000 kali lebih efektif daripada sampul buku yang hanya terjual 100 eksemplar. Namun, penskalaan log semua angka penjualan membuat tugas ini jauh lebih memungkinkan. Misalnya, log 100 adalah:
~4.6 = ln(100)
sedangkan log 1.000.000 adalah:
~13.8 = ln(1,000,000)
Jadi, log 1.000.000 hanya sekitar tiga kali lebih besar daripada log 100. Anda mungkin dapat membayangkan sampul buku terlaris sekitar tiga kali lebih efektif (dalam beberapa hal) daripada sampul buku yang tidak laku.
Kliping
Penyesuaian nilai adalah teknik untuk meminimalkan pengaruh pencilan ekstrem. Singkatnya, clipping biasanya membatasi (mengurangi) nilai pencilan ke nilai maksimum tertentu. Kliping adalah ide yang aneh, tetapi bisa sangat efektif.
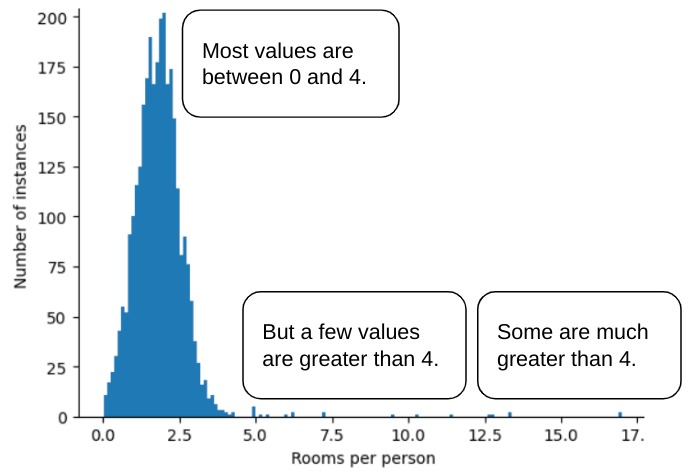
Misalnya, bayangkan set data yang berisi fitur bernama roomsPerPerson, yang merepresentasikan jumlah kamar (total kamar dibagi dengan jumlah penghuni) untuk berbagai rumah. Plot berikut menunjukkan bahwa lebih dari
99% nilai fitur sesuai dengan distribusi normal (kira-kira, rata-rata
1,8 dan simpangan baku 0,7). Namun, fitur ini berisi
beberapa pencilan, beberapa di antaranya ekstrem:
Bagaimana cara meminimalkan pengaruh pencilan ekstrem tersebut? Nah, histogramnya bukan distribusi merata, distribusi normal, atau distribusi hukum pangkat. Bagaimana jika Anda hanya membatasi atau memangkas nilai maksimum
roomsPerPerson pada nilai arbitrer, misalnya 4,0?
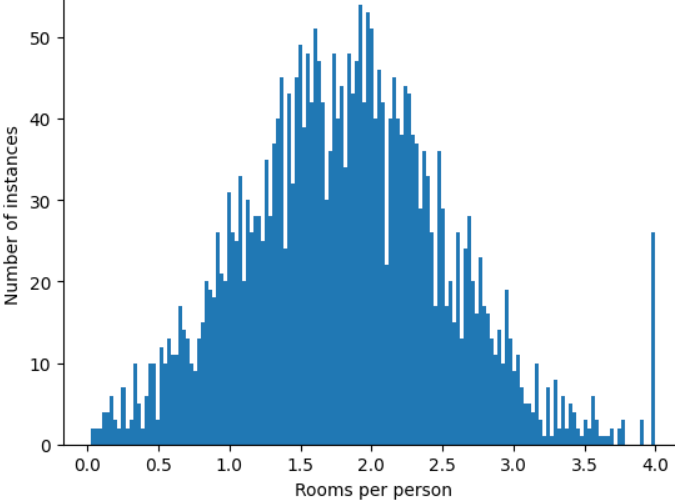
Memangkas nilai fitur pada 4,0 tidak berarti model Anda mengabaikan semua nilai yang lebih besar dari 4,0. Sebaliknya, semua nilai yang lebih besar dari 4,0 kini menjadi 4,0. Hal ini menjelaskan bukit aneh di 4.0. Meskipun ada bukit tersebut, set fitur yang diskalakan kini lebih berguna daripada data asli.
Tunggu sebentar! Dapatkah Anda benar-benar mengurangi setiap nilai pencilan ke batas atas arbitrer? Ya, saat melatih model.
Anda juga dapat memangkas nilai setelah menerapkan bentuk normalisasi lainnya. Misalnya, anggap Anda menggunakan penskalaan skor Z, tetapi beberapa pencilan memiliki nilai absolut yang jauh lebih besar dari 3. Dalam hal ini, Anda dapat:
- Klip skor Z yang lebih besar dari 3 menjadi tepat 3.
- Skor Z klip kurang dari -3 menjadi tepat -3.
Kliping mencegah model Anda melakukan pengindeksan berlebih pada data yang tidak penting. Namun, beberapa pencilan sebenarnya penting, jadi klip nilai dengan hati-hati.
Ringkasan teknik normalisasi
| Teknik normalisasi | Formula | Kapan digunakan |
|---|---|---|
| Skala linier | $$ x' = \frac{x - x_{min}}{x_{max} - x_{min}} $$ | Saat fitur didistribusikan sebagian besar secara seragam di seluruh rentang. Berbentuk datar |
| Penskalaan skor Z | $$ x' = \frac{x - μ}{σ}$$ | Jika fitur terdistribusi secara normal (puncak mendekati mean). Berbentuk lonceng |
| Penskalaan log | $$ x' = log(x)$$ | Jika distribusi fitur sangat miring di setidaknya salah satu sisi ekor. Berbentuk Ekor Berat |
| Kliping | Jika $x > max$, tetapkan $x' = max$ Jika $x < min$, tetapkan $x' = min$ |
Jika fitur berisi pencilan ekstrem. |
Latihan: Uji pengetahuan Anda

Misalnya, Anda sedang mengembangkan model yang memprediksi produktivitas pusat data berdasarkan suhu yang diukur di dalam pusat data.
Hampir semua nilai temperature dalam set data Anda berada
antara 15 dan 30 (Celsius), dengan pengecualian berikut:
- Satu atau dua kali per tahun, pada hari yang sangat panas, beberapa nilai antara
31 dan 45 tercatat di
temperature. - Setiap titik ke-1.000 di
temperaturedisetel ke 1.000 bukan suhu sebenarnya.
Teknik normalisasi mana yang wajar untuk
temperature?
Nilai 1.000 adalah kesalahan,dan harus dihapus, bukan dipangkas.
Nilai antara 31 dan 45 adalah titik data yang sah. Mungkin sebaiknya lakukan pemangkasan untuk nilai-nilai ini, dengan asumsi set data tidak berisi cukup banyak contoh dalam rentang suhu ini untuk melatih model membuat prediksi yang baik. Namun, selama inferensi, perhatikan bahwa model yang diklip akan membuat prediksi yang sama untuk suhu 45 seperti untuk suhu 35.