
Die ML Kit Pose Detection API ist eine unkomplizierte, vielseitige Lösung für App-Entwickler, um die Pose eines Körpers in Echtzeit anhand eines kontinuierlichen Videos oder statischen Bildes zu erkennen. Eine Pose beschreibt die Position des Körpers zu einem bestimmten Zeitpunkt mit einer Reihe von skelettartigen Orientierungspunkten. Die Orientierungspunkte entsprechen verschiedenen Körperteilen wie Schultern und Hüften. Anhand der relativen Positionen von Orientierungspunkten können Posen voneinander unterschieden werden.
Die ML Kit-Posenerkennung erzeugt einen 33-Punkt-Skelett-Match am Ganzkörper, bei dem Gesichtspunkte (Ohren, Augen, Mund und Nase) sowie Punkte an Händen und Füßen sichtbar sind. In Abbildung 1 unten sind die Orientierungspunkte zu sehen, die durch die Kamera auf den Nutzer blicken. Es handelt sich also um ein Spiegelbild. Die rechte Seite des Nutzers erscheint links neben dem Bild:
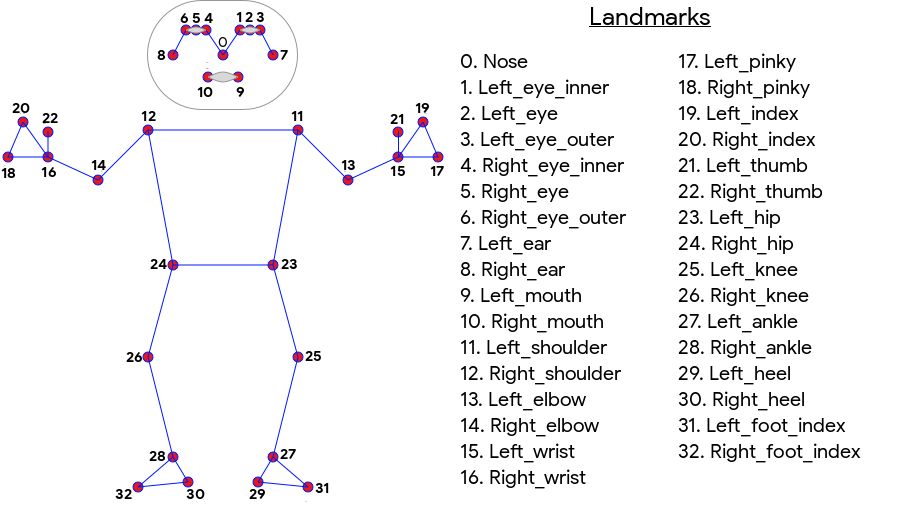
Für ML Kit-Positionserkennung sind keine speziellen Geräte oder ML-Kenntnisse erforderlich, um hervorragende Ergebnisse zu erzielen. Mit dieser Technologie können Entwickler mit nur wenigen Codezeilen einzigartige Erfahrungen für ihre Nutzer erstellen.
Das Gesicht des Nutzers muss sichtbar sein, um eine Pose zu erkennen. Die Posenerkennung funktioniert am besten, wenn der gesamte Körper der Person im Bild zu sehen ist, aber auch eine teilweise Körperhaltung erkannt wird. In diesem Fall werden den nicht erkannten Orientierungspunkten Koordinaten außerhalb des Bildes zugewiesen.
Hauptmerkmale
- Plattformübergreifende Unterstützung: Die Funktionen sind auf Android- und iOS-Geräten verfügbar.
- Ganzkörper-Tracking: Das Modell gibt 33 wichtige skelettale Orientierungspunkte zurück, einschließlich der Positionen der Hände und Füße.
- InFrameLikelihood-Wert Für jede Sehenswürdigkeit eine Kennzahl, die die Wahrscheinlichkeit angibt, dass sich die Markierung innerhalb des Bildframes befindet. Der Wert liegt zwischen 0,0 und 1,0, wobei 1,0 für eine hohe Konfidenz steht.
- Zwei optimierte SDKs: Das Basis-SDK wird auf modernen Smartphones wie dem Pixel 4 und iPhone X in Echtzeit ausgeführt. Sie gibt Ergebnisse mit einer Rate von ~30 bzw. ~45 fps zurück. Die Genauigkeit der Koordinaten des Orientierungspunkts kann jedoch variieren. Das korrekte SDK gibt Ergebnisse mit einer niedrigeren Framerate zurück, erzeugt jedoch genauere Koordinatenwerte.
- Z-Koordinate für Tiefenanalyse Mit diesem Wert kann bestimmt werden, ob sich Teile des Körpers des Nutzers vor oder hinter der Hüfte befinden. Weitere Informationen finden Sie unten im Abschnitt Z-Koordinate.
Die Pose Detection API ähnelt der Gacial Recognition API insofern, als sie eine Reihe von Sehenswürdigkeiten und deren Standort zurückgibt. Während die Gesichtserkennung auch versucht, Merkmale wie einen lächelnden Mund oder offene Augen zu erkennen, gibt die Positionserkennung den Sehenswürdigkeiten in einer Pose oder der Pose selbst keine Bedeutung. Sie können Ihre eigenen Algorithmen erstellen, um Posen zu interpretieren. Einige Beispiele finden Sie in den Tipps zur Paketklassifizierung.
Die Posenerkennung kann nur eine Person auf einem Bild erkennen. Wenn sich zwei Personen auf dem Bild befinden, weist das Modell der erkannten Person mit der höchsten Zuverlässigkeit Orientierungspunkte zu.
Z-Koordinate
Die Z-Koordinate ist ein experimenteller Wert, der für jede Sehenswürdigkeit berechnet wird. Sie wird wie die X- und Y-Koordinaten in "Bildpixeln" gemessen, ist aber kein echter 3D-Wert. Die Z-Achse ist senkrecht zur Kamera und verläuft zwischen den Hüften der Person. Der Ursprung der Z-Achse ist ungefähr der Mittelpunkt zwischen den Hüften (links/rechts und vorne/hinten relativ zur Kamera). Negative Z-Werte zeigen in Richtung der Kamera, positive Werte von ihr weg. Die Z-Koordinate hat keine Ober- oder Untergrenze.
Beispielergebnisse
In der folgenden Tabelle sehen Sie die Koordinaten und InFrameLikelihood für einige Sehenswürdigkeiten in der Pose rechts. Beachten Sie, dass die Z-Koordinaten für die linke Hand des Nutzers negativ sind, da sie sich vor der Hüftmitte der Person und in Richtung der Kamera befinden.

| Sehenswürdigkeit | Typ | Position | InFrameLikelihood |
|---|---|---|---|
| 11 | LEFT_SHOULDER | (734.9671, 550.7924, -118.11934) | 0,9999038 |
| 12 | RIGHT_SHOULDER | (391.27032, 583.2485, -321.15836) | 0,9999894 |
| 13 | LEFT_ELBOW | (903.83704, 754.676, -219.67009) | 0,9836427 |
| 14 | RIGHT_ELBOW | (322.18152, 842.5973, -179.28519) | 0,99970156 |
| 15 | LEFT_WRIST | (1073,8956, 654,9725, -820,93463) | 0,9737737 |
| 16 | RIGHT_WRIST | (218.27956, 1015.70435, -683.6567) | 0,995568 |
| 17 | LEFT_PINKY | (1146.1635, 609.6432, -956.9976) | 0,95273364 |
| 18 | RIGHT_PINKY | (176.17755, 1065.838, -776.5006) | 0,9785348 |
Details
Weitere Implementierungsdetails zu den zugrunde liegenden ML-Modellen für diese API finden Sie in unserem Google AI-Blogpost.
Weitere Informationen zu unseren ML-Fairness-Praktiken und zum Trainieren der Modelle finden Sie auf unserer Modellkarte.