
ML Kit Pose Detection API 是一个轻量级的多功能解决方案,可供应用开发者从连续视频或静态图片中实时检测对象身体的姿势。姿势通过一组骨骼特征点来描述身体在某个时刻的位置。这些特征点对应不同的身体部位,例如肩部和臀部。地标的相对位置可用于区分不同的姿势。
机器学习套件姿势检测可以生成 33 点式全身骨架匹配,其中包括面部特征点(耳朵、眼睛、嘴巴和鼻子)以及手脚上的点。下面的图 1 显示了通过镜头朝向用户的地标,因此这是镜像图像。用户的右侧显示在图片左侧:
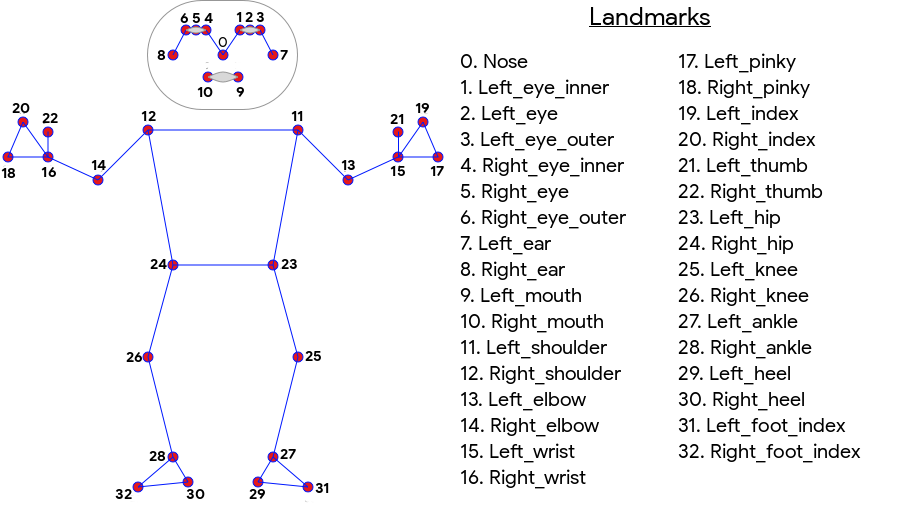
机器学习套件姿势检测不需要专业的设备或机器学习专业知识,也可以实现出色的结果。借助这种技术,开发者只需几行代码即可为其用户打造独特的体验。
为了检测姿势,用户的脸部必须出现。当拍摄对象的整个身体都在帧中可见时,姿势检测的效果最佳,但也可以检测到身体的局部姿势。在这种情况下,系统会为无法识别的地标分配图片外的坐标。
主要功能
- 跨平台支持:在 Android 和 iOS 上获享相同的体验。
- 全身跟踪:该模型会返回 33 个关键骨骼特征点,包括手脚的位置。
- InFrameLikelihood 得分:对于每个地标,这是一个度量方式,用于指示地标位于图片帧中的概率。得分介于 0.0 到 1.0 之间,其中 1.0 表示高置信度。
- 两个经过优化的 SDK:基础 SDK 可在 Pixel 4 和 iPhone X 等现代手机上实时运行。它分别以约 30 fps 和约 45 fps 的速率返回结果。不过,地标坐标的精确度可能会有所不同。准确的 SDK 以较慢的帧速率返回结果,但会生成更准确的坐标值。
- 用于深度分析的 Z 坐标:此值有助于确定用户身体的各个部位是在用户臀部前方还是后方。如需了解详情,请参阅下面的 Z 坐标部分。
Pose Detection API 与 Facial Recognition API 类似,因为它会返回一组地标及其位置。不过,虽然人脸检测还会尝试识别微笑的嘴巴或睁开的眼睛等特征,但姿势检测不会给某个姿势或姿势本身的地标附加任何含义。您可以创建自己的算法来解释姿势。有关某些示例,请参阅姿势分类提示。
姿势检测功能只能检测图片中的一人。如果图片中有两个人,模型将为检测到最高置信度的人分配地标。
Z 坐标
Z 坐标是为每个地标计算的实验性值。它以“图像像素”为单位(如 X 和 Y 坐标),但它不是真正的 3D 值。Z 轴垂直于镜头,穿过对象的臀部。Z 轴的原点大约是两个臀部之间的中心点(相对于镜头的左/右和前/后)。Z 负值表示镜头朝向;正值表示远离镜头。Z 坐标没有上限或下限。
示例结果
下表显示了右侧姿势中几个地标的坐标和 InFrameLikelihood。请注意,用户左手的 Z 坐标为负值,因为它们位于拍摄对象的臀部中心前方并朝向镜头。

| 地标 | 类型 | 位置 | InFrameLikelihood |
|---|---|---|---|
| 11 | LEFT_SHOULDER | (734.9671、550.7924、-118.11934) | 0.9999038 |
| 12 | RIGHT_SHOULDER | (391.27032、583.2485、-321.15836) | 0.9999894 |
| 13 | LEFT_ELBOW | (903.83704、754.676、-219.67009) | 0.9836427 |
| 14 | RIGHT_ELBOW | (322.18152、842.5973、-179.28519) | 0.99970156 |
| 15 | LEFT_WRIST | (1073.8956、654.9725、-820.93463) | 0.9737737 |
| 16 | RIGHT_WRIST | (218.27956、1015.70435、-683.6567) | 0.995568 |
| 17 | LEFT_PINKY | (1146.1635、609.6432、-956.9976) | 0.95273364 |
| 18 | RIGHT_PINKY | (176.17755、1065.838、-776.5006) | 0.9785348 |
深入了解
如需详细了解此 API 的底层机器学习模型的实现详情,请参阅我们的 Google AI 博文。
如需详细了解我们的机器学习公平性做法以及模型训练方式,请参阅我们的模型卡片