পূর্ববর্তী বিভাগে, আমরা উভয় জনসংখ্যার গোষ্ঠীর জন্য সামগ্রিক গ্রহণযোগ্যতার হার তুলনা করে, জনসংখ্যাগত সমতা ব্যবহার করে ন্যায্যতার জন্য আমাদের ভর্তির মডেলের মূল্যায়ন করেছি।
বিকল্পভাবে, আমরা সংখ্যাগরিষ্ঠ গোষ্ঠী এবং সংখ্যালঘু গোষ্ঠীতে শুধুমাত্র যোগ্য প্রার্থীদের জন্য গ্রহণযোগ্যতার হার তুলনা করতে পারি। উভয় গোষ্ঠীতে যোগ্য ছাত্রদের গ্রহণযোগ্যতার হার সমান হলে, মডেলটি সুযোগের সমতা প্রদর্শন করে: আমাদের পছন্দের লেবেলযুক্ত ছাত্রদের ("ভর্তি হওয়ার জন্য যোগ্য") ভর্তি হওয়ার সমান সুযোগ রয়েছে, তারা যে জনসংখ্যার গোষ্ঠীর অন্তর্ভুক্ত হোক না কেন।
পূর্ববর্তী বিভাগ থেকে আমাদের প্রার্থী পুল পুনরায় দেখুন:
| সংখ্যাগরিষ্ঠ দল | সংখ্যালঘু গোষ্ঠী | |
|---|---|---|
| যোগ্য | 35 | 15 |
| অযোগ্য | 45 | 5 |
ধরুন, ভর্তির মডেলটি সংখ্যাগরিষ্ঠ গ্রুপ থেকে 14 জন এবং সংখ্যালঘু গোষ্ঠী থেকে 6 জন প্রার্থীকে গ্রহণ করে। মডেলের সিদ্ধান্তগুলি সুযোগের সমতাকে সন্তুষ্ট করে, কারণ যোগ্য সংখ্যাগরিষ্ঠ এবং যোগ্য সংখ্যালঘু উভয় প্রার্থীর গ্রহণযোগ্যতার হার 40%।
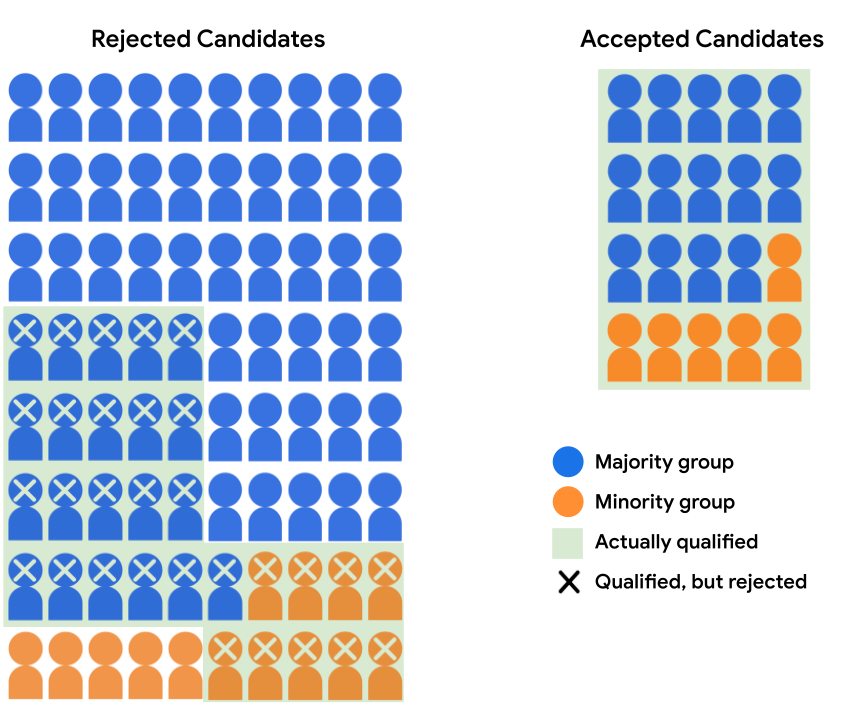
নিম্নলিখিত সারণীটি চিত্র 4-এ প্রত্যাখ্যাত এবং গৃহীত প্রার্থীদের সমর্থনকারী সংখ্যাগুলিকে পরিমাপ করে৷
| সংখ্যাগরিষ্ঠ দল | সংখ্যালঘু গোষ্ঠী | |||
|---|---|---|---|---|
| গৃহীত | প্রত্যাখ্যাত | গৃহীত | প্রত্যাখ্যাত | |
| যোগ্য | 14 | 21 | 6 | 9 |
| অযোগ্য | 0 | 45 | 0 | 5 |
সুবিধা এবং অসুবিধা
সুযোগের সমতার মূল সুবিধা হল যে এটি মডেলের ইতিবাচক থেকে নেতিবাচক ভবিষ্যদ্বাণীর অনুপাতকে জনসংখ্যাগত গোষ্ঠীগুলিতে পরিবর্তিত হতে দেয়, শর্ত থাকে যে মডেলটি উভয় গ্রুপের জন্য পছন্দের লেবেল ("ভর্তি করার জন্য যোগ্য") ভবিষ্যদ্বাণী করতে সমানভাবে সফল হয়৷
চিত্র 4-এর মডেলের ভবিষ্যদ্বাণীগুলি জনসংখ্যাগত সমতাকে সন্তুষ্ট করে না , কারণ সংখ্যাগরিষ্ঠ গোষ্ঠীর একজন ছাত্রের গৃহীত হওয়ার সম্ভাবনা 17.5%, এবং সংখ্যালঘু গোষ্ঠীর একজন ছাত্রের গৃহীত হওয়ার সম্ভাবনা 30%। যাইহোক, একজন যোগ্য শিক্ষার্থীর গৃহীত হওয়ার 40% সম্ভাবনা রয়েছে, তারা যে গোষ্ঠীরই হোক না কেন, যা যুক্তিযুক্তভাবে একটি ফলাফল যা এই নির্দিষ্ট মডেল ব্যবহারের ক্ষেত্রে আরও ন্যায্য।
সুযোগের সমতার একটি ত্রুটি হল যে এটি এমন ক্ষেত্রে ডিজাইন করা হয়েছে যেখানে একটি পরিষ্কার-কাট পছন্দের লেবেল রয়েছে। যদি এটি সমানভাবে গুরুত্বপূর্ণ হয় যে মডেলটি সমস্ত জনসংখ্যার গোষ্ঠীর জন্য ইতিবাচক শ্রেণী ("ভর্তি করার জন্য যোগ্য") এবং নেতিবাচক শ্রেণী ("ভর্তি করার জন্য যোগ্য নয়") উভয়েরই পূর্বাভাস দেয়, তাহলে এটির পরিবর্তে মেট্রিক সমতুল্য প্রতিকূলতা ব্যবহার করা বোধগম্য হতে পারে, যা সমান প্রয়োগ করে উভয় লেবেলের জন্য সাফল্যের হার।
সুযোগের সমতার আরেকটি ত্রুটি হল যে এটি জনসংখ্যাগত গোষ্ঠীগুলির জন্য সামগ্রিকভাবে ত্রুটির হার তুলনা করে ন্যায্যতার মূল্যায়ন করে, যা সবসময় সম্ভব নাও হতে পারে। উদাহরণস্বরূপ, যদি আমাদের ভর্তির মডেলের ডেটাসেটে demographic_group বৈশিষ্ট্য না থাকে, তাহলে যোগ্য সংখ্যাগরিষ্ঠ এবং সংখ্যালঘু প্রার্থীদের জন্য গ্রহণযোগ্যতার হার বের করা এবং সুযোগের সমতা সন্তুষ্ট কিনা তা দেখার জন্য তাদের তুলনা করা সম্ভব হবে না।
পরবর্তী বিভাগে, আমরা অন্য একটি ন্যায্যতা মেট্রিক, কাউন্টারফ্যাকচুয়াল ন্যায্যতা দেখব, যা এমন পরিস্থিতিতে ব্যবহার করা যেতে পারে যেখানে সমস্ত উদাহরণের জন্য জনসংখ্যার ডেটা বিদ্যমান নেই।
অনুশীলন: আপনার বোঝার পরীক্ষা করুন
একটি মডেলের ভবিষ্যদ্বাণীর পক্ষে জনসংখ্যাগত সমতা এবং সুযোগের সমতা উভয়কেই সন্তুষ্ট করা সম্ভব।
উদাহরণ স্বরূপ, ধরা যাক একটি বাইনারি ক্লাসিফায়ার (যার পছন্দের লেবেল হল ইতিবাচক শ্রেণী) 100টি উদাহরণের ভিত্তিতে মূল্যায়ন করা হয়েছে, ফলাফলগুলি নিম্নলিখিত বিভ্রান্তি ম্যাট্রিক্সে দেখানো হয়েছে, জনসংখ্যাগত গোষ্ঠী (সংখ্যাগরিষ্ঠ এবং সংখ্যালঘু) দ্বারা বিভক্ত:
| সংখ্যাগরিষ্ঠ দল | সংখ্যালঘু গোষ্ঠী | |||
|---|---|---|---|---|
| ইতিবাচক ভবিষ্যদ্বাণী | পূর্বাভাস নেতিবাচক | ইতিবাচক ভবিষ্যদ্বাণী | পূর্বাভাস নেতিবাচক | |
| প্রকৃত ইতিবাচক | 6 | 12 | 3 | 6 |
| প্রকৃত নেতিবাচক | 10 | 36 | 6 | 21 |
\(\text{Positive Rate} = \frac{6+10}{6+10+12+36} = \frac{16}{64} = \text{25%}\) \(\text{True Positive Rate} = \frac{6}{6+12} = \frac{6}{18} = \text{33%}\) | \(\text{Positive Rate} = \frac{3+6}{3+6+6+21} = \frac{9}{36} = \text{25%}\) \(\text{True Positive Rate} = \frac{3}{3+6} = \frac{3}{9} = \text{33%}\) | |||
সংখ্যাগরিষ্ঠ এবং সংখ্যালঘু উভয় গোষ্ঠীরই ইতিবাচক পূর্বাভাসের হার 25%, সন্তোষজনক জনসংখ্যাগত সমতা, এবং একটি সত্য ইতিবাচক হার (পছন্দের লেবেল সহ উদাহরণগুলির শতাংশ যা সঠিকভাবে শ্রেণীবদ্ধ করা হয়েছে) 33%, সুযোগের সন্তোষজনক সমতা।