पिछले सेक्शन में, हमने निष्पक्षता के लिए एडमिशन मॉडल का आकलन किया है. इसके लिए दोनों के लिए, स्वीकार किए जाने की कुल दरों की तुलना करके डेमोग्राफ़िक समानता डेमोग्राफ़िक (उम्र, लिंग, आय, शिक्षा वगैरह) ग्रुप.
इसके अलावा, हम सिर्फ़ स्वीकार किए जाने वाले संगठनों के लिए, स्वीकार किए जाने की दर की तुलना कर सकते हैं बहुमत समूह और अल्पसंख्यक समूह के उम्मीदवार हैं. अगर स्वीकार किए जाने की दर दोनों ग्रुप में क्वालिफ़ाई करने वाले छात्र-छात्राओं के लिए, एक जैसी सभी को समान अवसर: जिन छात्र-छात्राओं के पसंदीदा लेबल ("प्रोग्राम में शामिल होने की ज़रूरी शर्तें पूरी करते हैं") के पास उनके डेमोग्राफ़िक (उम्र, लिंग, आय, शिक्षा वगैरह) ग्रुप से जुड़े होने की परवाह किए बिना से.
चलिए, पिछले सेक्शन में दिए गए कैंडिडेट पूल पर दोबारा नज़र डालते हैं:
| ज़्यादातर लोगों का ग्रुप | अल्पसंख्यक समूह | |
|---|---|---|
| क्वालिफ़ाइड | 35 | 15 |
| अमान्य | 45 | 5 |
मान लीजिए कि एडमिशन मॉडल, बहुमत समूह के 14 उम्मीदवारों को स्वीकार करता है और अल्पसंख्यक समूह के छह उम्मीदवार हैं. मॉडल के फ़ैसले अवसर की समानता, क्योंकि दोनों क्वालीफ़ाइड बहुमत को स्वीकार करने की दर और अल्पसंख्यक उम्मीदवारों के लिए आवेदन करना 40% होता है.
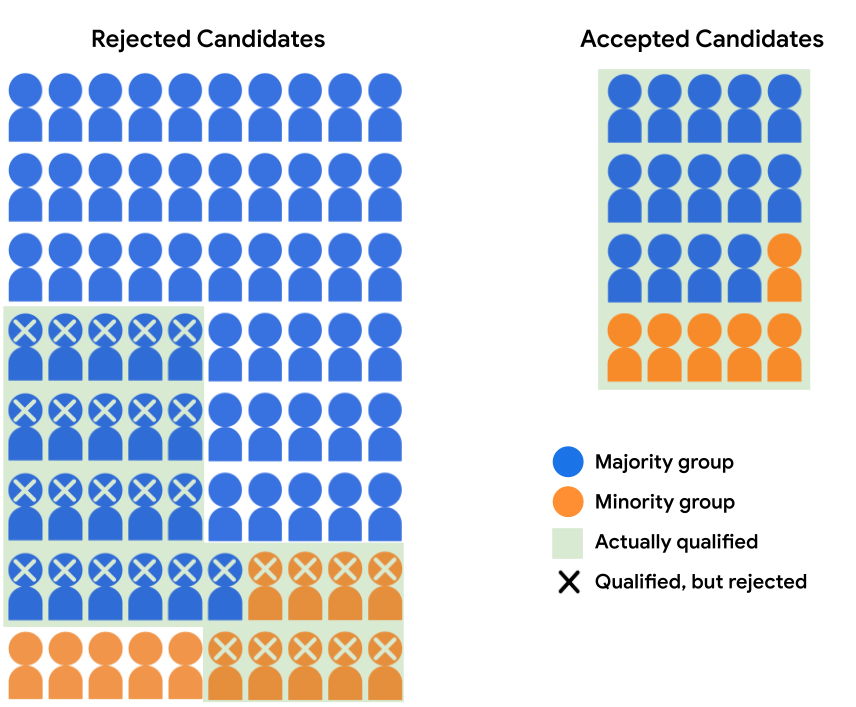
नीचे दी गई टेबल में, अस्वीकार किए गए और स्वीकार किए गए ग्राहकों की संख्या दिखाई गई है इमेज 4 में दिए गए उम्मीदवार.
| ज़्यादातर लोगों का ग्रुप | अल्पसंख्यक समूह | |||
|---|---|---|---|---|
| स्वीकृत | अस्वीकार किया गया | स्वीकृत | अस्वीकार किया गया | |
| क्वालिफ़ाइड | 14 | 21 | 6 | 9 |
| अमान्य | 0 | 45 | 0 | 5 |
फ़ायदे और कमियां
अवसर की समानता का मुख्य लाभ यह है कि इससे मॉडल का डेमोग्राफ़िक (उम्र, लिंग, आय, शिक्षा वगैरह) ग्रुप के हिसाब से, पॉज़िटिव और नेगेटिव अनुमानों का अनुपात अलग-अलग हो सकता है. यह मुमकिन है कि वह मॉडल, पसंदीदा लेबल का अनुमान लगाने में बराबर सफल हो ("इवेंट में शामिल होने की ज़रूरी शर्तें पूरी नहीं करता") कर सकते हैं.
इमेज 4 में दिखाए गए मॉडल के अनुमान, डेमोग्राफ़िक (उम्र, लिंग, आय, शिक्षा वगैरह) के बराबर, ज़्यादातर ग्रुप में शामिल छात्र/छात्रा के तौर पर मंज़ूरी मिलने की संभावना 17.5% होती है. साथ ही, अल्पसंख्यक समूह के किसी छात्र/छात्रा के स्वीकार किए जाने की संभावना 30% है. हालांकि, मंज़ूरी पाने वाले छात्र/छात्रा के पास होने की संभावना 40% होती है, भले ही जिनमें वे शामिल होते हैं. यह नतीजा है कि इस मामले में इस्तेमाल का उदाहरण.
अवसर की समानता की एक कमी यह है कि उसे सिर्फ़ ऐसे मामले जहां पसंदीदा लेबल साफ़ तौर पर दिया गया हो. अगर यह ज़रूरी है कि कि मॉडल, दोनों पॉज़िटिव क्लास का अनुमान लगाता है ("डाले जाने की शर्तें पूरी करता है") और सभी डेमोग्राफ़िक (उम्र, लिंग, आय, शिक्षा वगैरह) ग्रुप के लिए, नेगेटिव क्लास ("शामिल नहीं किया जा सकता"), तो इसके बजाय मेट्रिक का इस्तेमाल करना सही रहेगा. समान ऑड्स, जिससे लागू होता है दोनों लेबल की सफलता की दर एक जैसी हो.
अवसर की समानता की एक और कमी यह है कि इसमें निष्पक्षता का आकलन किया जाता है
इसके लिए गड़बड़ी की दरों की तुलना डेमोग्राफ़िक (उम्र, लिंग, आय, शिक्षा वगैरह) ग्रुप से की जाती है.
हमेशा संभव नहीं होता है. उदाहरण के लिए, अगर हमारे एडमिशन मॉडल का डेटासेट
में demographic_group की सुविधा नहीं थी, तो संभव नहीं है कि
योग्य बहुमत और अल्पसंख्यक उम्मीदवारों के लिए, मंज़ूरी मिलने की दर के बारे में जानकारी
और तुलना करके देखा जा सकता है कि सबको समान अवसर मिलते हैं या नहीं.
अगले सेक्शन में, हम निष्पक्षता से जुड़ी एक और मेट्रिक, काउंटरफ़ैक्चुअल इसे उन स्थितियों में इस्तेमाल किया जा सकता है जहां डेमोग्राफ़िक (उम्र, लिंग, आय, शिक्षा वगैरह) डेटा सभी उदाहरणों के लिए मौजूद हैं.
व्यायाम: अपनी समझ की जांच करें
किसी मॉडल के अनुमान की मदद से, हो सकता है कि दोनों डेमोग्राफ़िक (उम्र, लिंग, आय, शिक्षा वगैरह) के हिसाब से जानकारी हासिल की जाए अवसर की समानता और समानता.
उदाहरण के लिए, मान लें कि एक बाइनरी क्लासिफ़ायर (जिसका पसंदीदा लेबल का आकलन होता है) का आकलन 100 उदाहरणों के आधार पर किया जाता है. इसके नतीजे नीचे दी गई भ्रमित आव्यूहों में दिखाया गया है. डेमोग्राफ़िक (उम्र, लिंग, आय, शिक्षा वगैरह) ग्रुप (ज़्यादा संख्या और अल्पसंख्यक):
| ज़्यादातर लोगों का ग्रुप | अल्पसंख्यक समूह | |||
|---|---|---|---|---|
| अनुमानित पॉज़िटिव | अनुमानित नेगेटिव | अनुमानित पॉज़िटिव | अनुमानित नेगेटिव | |
| असल पॉज़िटिव | 6 | 12 | 3 | 6 |
| असल नेगेटिव | 10 | 36 | 6 | 21 |
|
\(\text{Positive Rate} = \frac{6+10}{6+10+12+36} = \frac{16}{64} = \text{25%}\) \(\text{True Positive Rate} = \frac{6}{6+12} = \frac{6}{18} = \text{33%}\) |
\(\text{Positive Rate} = \frac{3+6}{3+6+6+21} = \frac{9}{36} = \text{25%}\) \(\text{True Positive Rate} = \frac{3}{3+6} = \frac{3}{9} = \text{33%}\) |
|||
बहुमत और अल्पसंख्यक समूह, दोनों की अनुमान दर सकारात्मक होती है 25% की बढ़ोतरी, डेमोग्राफ़िक समानता और सही मायनों में पॉज़िटिव दर (पसंदीदा लेबल वाले उदाहरणों का प्रतिशत, उन्हें सही कैटगरी में बांटा गया है) 33% है, जिससे उन्हें समान अवसर मिलते हैं.