כשבוחנים מודל, המדדים מחושבים ביחס לכל הבדיקה או האימות לא תמיד מספקות תמונה מדויקת של מידת ההוגן של המודל. ביצועים טובים של המודל באופן כללי עבור רוב הדוגמאות עלולים להסוות את הנתונים הגרועים את הביצועים של קבוצת משנה של מיעוט דוגמאות, דבר שעלול להוביל של החיזויים. שימוש במדדי ביצועים מצטברים כמו precision, recall, הדיוק לא בהכרח ישפיע כדי לחשוף את הבעיות האלה.
אנחנו יכולים לחזור אל מודל הקבלה שלנו ולחקור כמה שיטות חדשות לגבי הערכת החיזויים שלה בנוגע להטיה, תוך התחשבות בהגינות.
נניח שמודל הסיווג של הקבלות בוחר 20 תלמידים שמאשרים אוניברסיטה מתוך מאגר של 100 מועמדים, השייכים לשתי קבוצות דמוגרפיות: קבוצת הרוב (כחול, 80 תלמידים) וקבוצת המיעוט (כתום, 20 תלמידים).
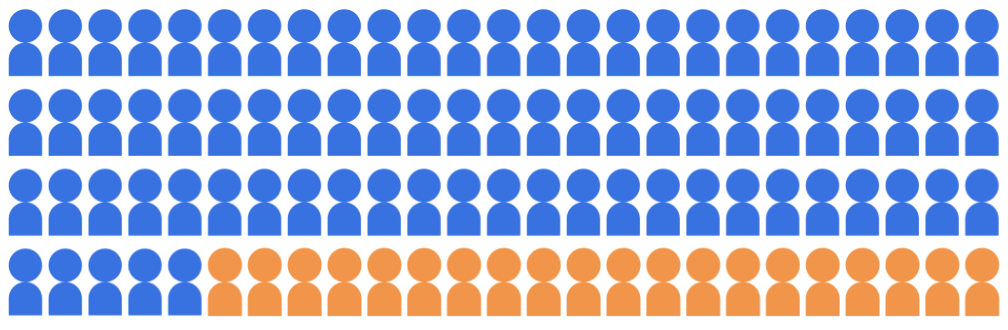
המודל חייב לאשר לתלמידים שעומדים בדרישות באופן ההוגן כלפי מועמדים בשתי הקבוצות הדמוגרפיות.
איך אנחנו צריכים להעריך את הוגנות החיזוי של המודל? יש מגוון של מדדים שאפשר לבחון, שכל אחד מהם מספק שיטה מתמטית שונה את ההגדרה של 'הוגנות'. בחלקים הבאים נסביר על שלושה את מדדי ההוגנות האלה לעומק: שוויון דמוגרפי, שוויון הזדמנויות, והוגן בניגוד לעובדות.