یک فناوری جدیدتر، مدلهای زبانی بزرگ ( LLM ) هستند که یک توکن یا دنبالهای از توکنها را پیشبینی میکنند، گاهی اوقات چندین پاراگراف از توکنهای پیشبینیشده. به یاد داشته باشید که یک توکن میتواند یک کلمه، یک زیرکلمه (زیرمجموعهای از یک کلمه) یا حتی یک کاراکتر واحد باشد. LLMها پیشبینیهای بسیار بهتری نسبت به مدلهای زبانی N-gram یا شبکههای عصبی بازگشتی ارائه میدهند زیرا:
- مدلهای LLM پارامترهای بسیار بیشتری نسبت به مدلهای بازگشتی دارند.
- LLM ها اطلاعات بسیار بیشتری را جمعآوری میکنند.
این بخش موفقترین و پرکاربردترین معماری برای ساخت LLMها را معرفی میکند: Transformer.
ترانسفورماتور چیست؟
ترانسفورماتورها معماری پیشرفتهای برای طیف گستردهای از برنامههای مدل زبانی، مانند ترجمه، هستند:

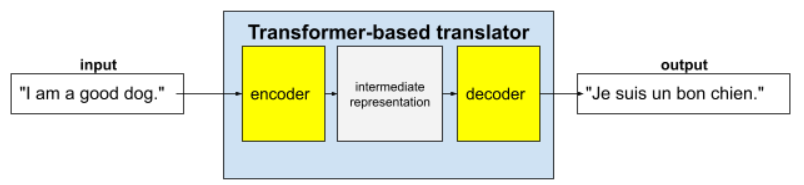
ترانسفورماتورهای کامل از یک رمزگذار و یک رمزگشا تشکیل شدهاند:
- یک رمزگذار متن ورودی را به یک نمایش میانی تبدیل میکند. رمزگذار یک شبکه عصبی عظیم است.
- یک رمزگشا آن نمایش میانی را به متن مفید تبدیل میکند. یک رمزگشا همچنین یک شبکه عصبی عظیم است.
برای مثال، در یک مترجم:
- رمزگذار متن ورودی (مثلاً یک جمله انگلیسی) را به نوعی نمایش میانی پردازش میکند.
- رمزگشا آن نمایش میانی را به متن خروجی (مثلاً جمله معادل فرانسوی) تبدیل میکند.
توجه به خود چیست؟
برای بهبود زمینه، ترنسفورمرز به شدت به مفهومی به نام خود-توجهی متکی است. در واقع، خود-توجهی به نمایندگی از هر نشانه ورودی، سوال زیر را میپرسد:
«هر نشانه ورودی چقدر بر تفسیر این نشانه تأثیر میگذارد؟»
«خود» در «توجه به خود» به توالی ورودی اشاره دارد. برخی از مکانیسمهای توجه، روابط توکنهای ورودی با توکنها در یک توالی خروجی مانند یک ترجمه یا با توکنها در توالی دیگری را میسنجند. اما توجه به خود فقط اهمیت روابط بین توکنها در توالی ورودی را میسنجد.
برای سادهتر کردن موضوع، فرض کنید هر توکن یک کلمه است و کل متن فقط یک جمله است. جمله زیر را در نظر بگیرید:
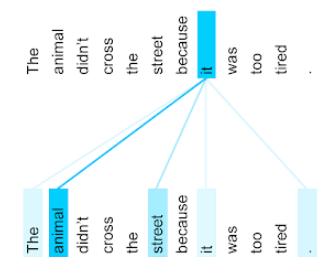
The animal didn't cross the street because it was too tired.
جملهی قبلی شامل یازده کلمه است. هر یک از یازده کلمه به ده کلمهی دیگر توجه دارد و به این فکر میکند که هر یک از آن ده کلمه چقدر برای خودش اهمیت دارد. برای مثال، توجه کنید که جمله حاوی ضمیر it است . ضمایر اغلب مبهم هستند. ضمیر it معمولاً به یک اسم یا عبارت اسمی اخیر اشاره دارد، اما در جملهی مثال، به کدام اسم اخیر اشاره دارد - حیوان یا خیابان؟
مکانیسم خود-توجهی، ارتباط هر کلمه نزدیک به ضمیر it را تعیین میکند. شکل ۳ نتایج را نشان میدهد - هرچه خط آبیتر باشد، آن کلمه برای ضمیر it مهمتر است. یعنی، کلمه animal نسبت به کلمه street برای ضمیر it مهمتر است.
برعکس، فرض کنید کلمه آخر جمله به صورت زیر تغییر کند:
The animal didn't cross the street because it was too wide.
در این جملهی اصلاحشده، امید است که با توجه به خود، کلمهی street نسبت به animal برای ضمیر it مرتبطتر ارزیابی شود.
برخی از مکانیسمهای خودتوجهی دوطرفه هستند، به این معنی که آنها امتیازهای مربوط به توکنهای قبل و بعد از کلمهای که به آن توجه میشود را محاسبه میکنند. به عنوان مثال، در شکل 3، توجه کنید که کلمات در هر دو طرف آن بررسی میشوند. بنابراین، یک مکانیسم خودتوجهی دوطرفه میتواند زمینه را از کلمات در دو طرف کلمهای که به آن توجه میشود جمعآوری کند. در مقابل، یک مکانیسم خودتوجهی یکطرفه فقط میتواند زمینه را از کلمات در یک طرف کلمهای که به آن توجه میشود جمعآوری کند. خودتوجهی دوطرفه به ویژه برای تولید نمایشهای کل توالیها مفید است، در حالی که برنامههایی که توالیها را به صورت توکن به توکن تولید میکنند، نیاز به خودتوجهی یکطرفه دارند. به همین دلیل، رمزگذارها از خودتوجهی دوطرفه استفاده میکنند، در حالی که رمزگشاها از خودتوجهی یکطرفه استفاده میکنند.
توجه به خود چند لایه چند سر چیست؟
هر لایه خود-توجه معمولاً از چندین سر خود-توجه تشکیل شده است. خروجی یک لایه، یک عملیات ریاضی (مثلاً میانگین وزنی یا ضرب نقطهای) از خروجی سرهای مختلف است.
از آنجایی که پارامترهای هر سر با مقادیر تصادفی مقداردهی اولیه میشوند، سرهای مختلف میتوانند روابط متفاوتی بین هر کلمهای که به آن توجه میشود و کلمات مجاور آن را یاد بگیرند. به عنوان مثال، سر خود-توجه که در بخش قبلی توضیح داده شد، بر تعیین اینکه به کدام اسم ضمیر اشاره دارد، تمرکز داشت. با این حال، سرهای خود-توجه دیگر در همان لایه ممکن است ارتباط دستوری هر کلمه با هر کلمه دیگر یا تعاملات دیگر را یاد بگیرند.
یک مدل کامل تبدیل شونده، چندین لایه خود-توجه را روی هم قرار میدهد. خروجی لایه قبلی، ورودی لایه بعدی میشود. این انباشتگی به مدل اجازه میدهد تا به تدریج درکهای پیچیدهتر و انتزاعیتری از متن ایجاد کند. در حالی که لایههای اولیه ممکن است بر نحو پایه تمرکز کنند، لایههای عمیقتر میتوانند آن اطلاعات را ادغام کنند تا مفاهیم ظریفتری مانند احساسات، زمینه و پیوندهای موضوعی را در کل ورودی درک کنند.
چرا ترانسفورماتورها اینقدر بزرگ هستند؟
ترانسفورماتورها حاوی صدها میلیارد یا حتی تریلیونها پارامتر هستند. این دوره آموزشی عموماً ساخت مدلهایی با تعداد پارامترهای کمتر را نسبت به مدلهایی با تعداد پارامترهای بیشتر توصیه کرده است. از این گذشته، مدلی با تعداد پارامترهای کمتر، منابع کمتری را برای پیشبینی نسبت به مدلی با تعداد پارامترهای بیشتر استفاده میکند. با این حال، تحقیقات نشان میدهد که ترانسفورماتورهایی با پارامترهای بیشتر، به طور مداوم از ترانسفورماتورهایی با پارامترهای کمتر بهتر عمل میکنند.
اما یک LLM چگونه متن تولید میکند ؟
شما دیدهاید که چگونه محققان LLMها را برای پیشبینی یک یا دو کلمهی جا افتاده آموزش میدهند، و ممکن است تحت تأثیر قرار نگرفته باشید. به هر حال، پیشبینی یک یا دو کلمه اساساً ویژگی تکمیل خودکار است که در نرمافزارهای مختلف متن، ایمیل و نویسندگی تعبیه شده است. ممکن است از خود بپرسید که چگونه LLMها میتوانند جملات یا پاراگرافها یا هایکوهایی در مورد آربیتراژ تولید کنند.
در واقع، LLMها اساساً مکانیسمهای تکمیل خودکار هستند که میتوانند هزاران توکن را به طور خودکار پیشبینی (تکمیل) کنند. برای مثال، جملهای را در نظر بگیرید که به دنبال آن یک جمله ماسکشده قرار دارد:
My dog, Max, knows how to perform many traditional dog tricks. ___ (masked sentence)
یک LLM میتواند احتمالاتی را برای جمله ماسکشده تولید کند، از جمله:
| احتمال | کلمه(ها) |
|---|---|
| ۳.۱٪ | برای مثال، او میتواند بنشیند، بایستد و غلت بزند. |
| ۲.۹٪ | برای مثال، او میداند چگونه بنشیند، بماند و غلت بزند. |
یک LLM به اندازه کافی بزرگ میتواند احتمالاتی را برای پاراگرافها و کل مقالهها تولید کند. میتوانید سوالات یک کاربر از یک LLM را به عنوان جمله "داده شده" و به دنبال آن یک ماسک خیالی در نظر بگیرید. برای مثال:
User's question: What is the easiest trick to teach a dog? LLM's response: ___
LLM احتمالاتی را برای پاسخهای مختلف ممکن تولید میکند.
به عنوان مثالی دیگر، یک LLM که بر روی تعداد زیادی از «مسائل کلامی» ریاضی آموزش دیده است، میتواند ظاهری شبیه به انجام استدلال ریاضی پیچیده از خود نشان دهد. با این حال، این LLMها اساساً فقط یک سوال مسئله کلامی را به طور خودکار تکمیل میکنند.
مزایای دورههای LLM
LLMها میتوانند متنهای واضح و قابل فهمی را برای طیف وسیعی از مخاطبان هدف تولید کنند. LLMها میتوانند در مورد وظایفی که به صراحت برای آنها آموزش دیدهاند، پیشبینیهایی انجام دهند. برخی از محققان ادعا میکنند که LLMها همچنین میتوانند در مورد ورودیهایی که به صراحت برای آنها آموزش ندیدهاند ، پیشبینیهایی انجام دهند، اما محققان دیگر این ادعا را رد کردهاند.
مشکلات مربوط به LLM
آموزش یک LLM مشکلات زیادی را به همراه دارد، از جمله:
- جمعآوری یک مجموعه آموزشی عظیم.
- مصرف چندین ماه و منابع محاسباتی و برق عظیم.
- حل چالشهای موازیسازی
استفاده از LLMها برای استنتاج پیشبینیها باعث مشکلات زیر میشود:
- LLM ها دچار توهم میشوند ، به این معنی که پیشبینیهای آنها اغلب حاوی اشتباهاتی است.
- LLMها منابع محاسباتی و برق بسیار زیادی مصرف میکنند. آموزش LLMها روی مجموعه دادههای بزرگتر معمولاً میزان منابع مورد نیاز برای استنتاج را کاهش میدهد، اگرچه مجموعههای آموزشی بزرگتر منابع آموزشی بیشتری را میطلبند.
- مانند تمام مدلهای یادگیری ماشین، LLMها میتوانند انواع سوگیریها را از خود نشان دهند.