You saw in the previous exercise that just adding hidden layers to our network wasn't sufficient to represent nonlinearities. Linear operations performed on linear operations are still linear.
How can you configure a neural network to learn nonlinear relationships between values? We need some way to insert nonlinear mathematical operations into a model.
If this seems somewhat familiar, that's because we've actually applied nonlinear mathematical operations to the output of a linear model earlier in the course. In the Logistic Regression module, we adapted a linear regression model to output a continuous value from 0 to 1 (representing a probability) by passing the model's output through a sigmoid function.
We can apply the same principle to our neural network. Let's revisit our model from Exercise 2 earlier, but this time, before outputting the value of each node, we'll first apply the sigmoid function:
Try stepping through the calculations of each node by clicking the >| button (to the right of the play button). Review the mathematical operations performed to calculate each node value in the Calculations panel below the graph. Note that each node's output is now a sigmoid transform of the linear combination of the nodes in the previous layer, and the output values are all squished between 0 and 1.
Here, the sigmoid serves as an activation function for the neural network, a nonlinear transform of a neuron's output value before the value is passed as input to the calculations of the next layer of the neural network.
Now that we've added an activation function, adding layers has more impact. Stacking nonlinearities on nonlinearities lets us model very complicated relationships between the inputs and the predicted outputs. In brief, each layer is effectively learning a more complex, higher-level function over the raw inputs. If you'd like to develop more intuition on how this works, see Chris Olah's excellent blog post.
Common activation functions
Three mathematical functions that are commonly used as activation functions are sigmoid, tanh, and ReLU.
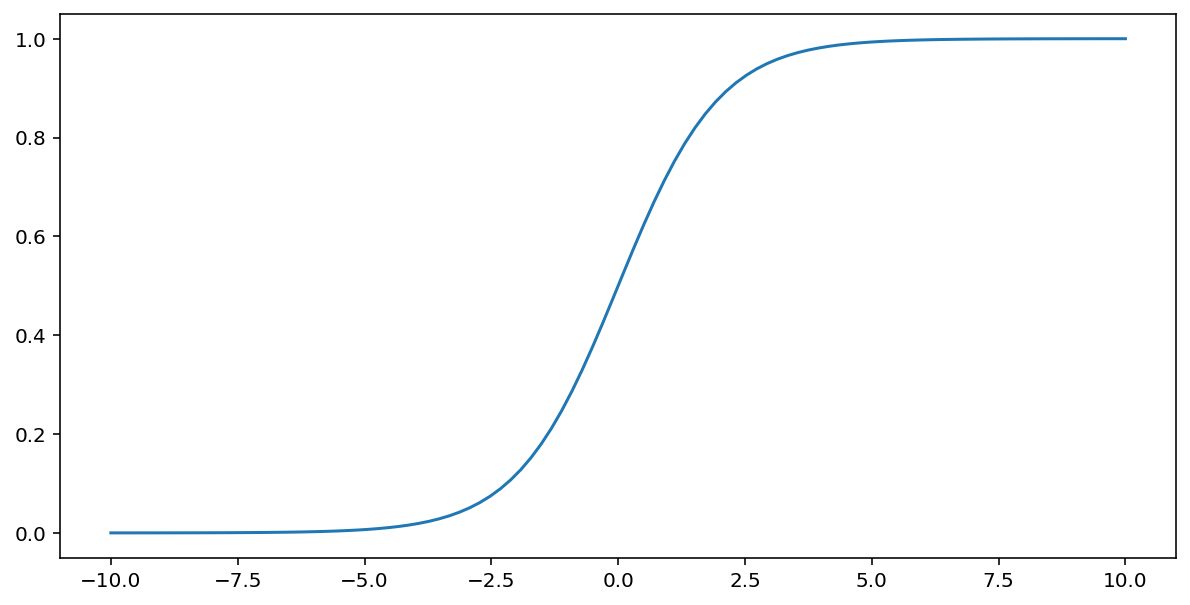
The sigmoid function (discussed above) performs the following transform on input $x$, producing an output value between 0 and 1:
\[F(x)=\frac{1} {1+e^{-x}}\]
Here's a plot of this function:
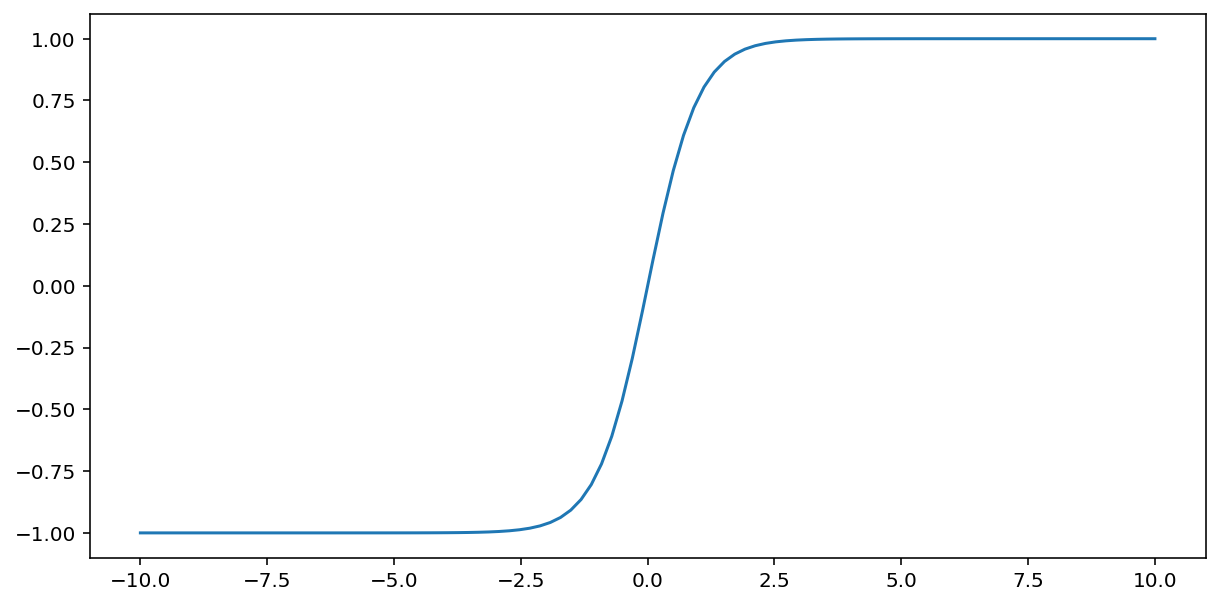
The tanh (short for "hyperbolic tangent") function transforms input $x$ to produce an output value between –1 and 1:
\[F(x)=tanh(x)\]
Here's a plot of this function:
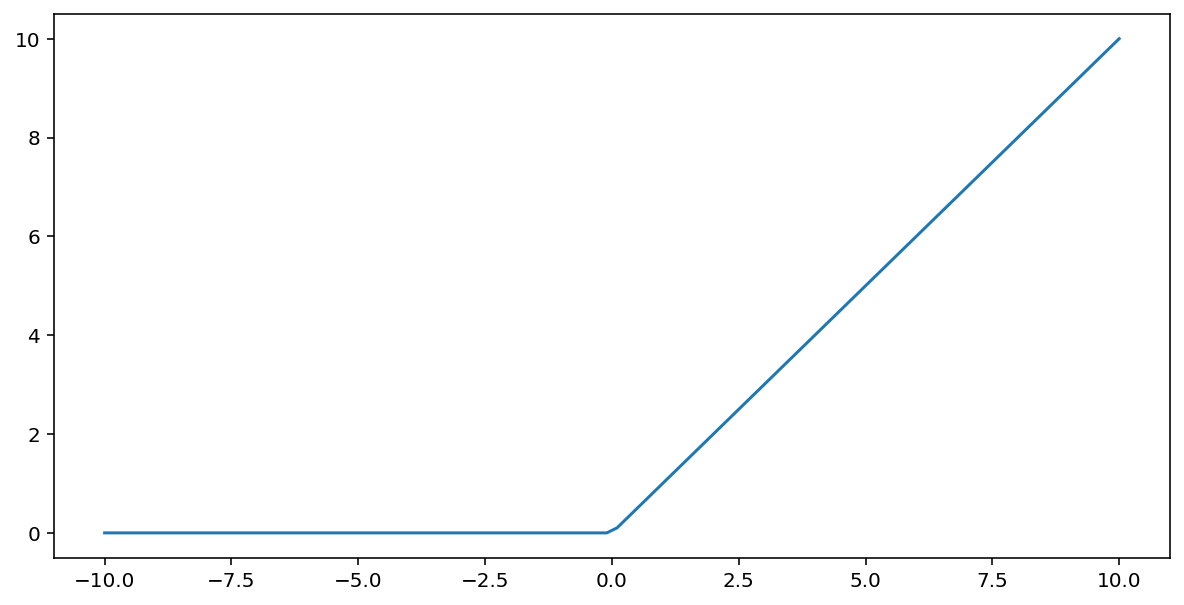
The rectified linear unit activation function (or ReLU, for short) transforms output using the following algorithm:
- If the input value $x$ is less than 0, return 0.
- If the input value $x$ is greater than or equal to 0, return the input value.
ReLU can be represented mathematically using the max() function:
Here's a plot of this function:
ReLU often works a little better as an activation function than a smooth function like sigmoid or tanh, because it is less susceptible to the vanishing gradient problem during neural network training. ReLU is also significantly easier to compute than these functions.
Other activation functions
In practice, any mathematical function can serve as an activation function. Suppose that \(\sigma\) represents our activation function. The value of a node in the network is given by the following formula:
Keras provides out-of-the-box support for many activation functions. That said, we still recommend starting with ReLU.
Summary
The following video provides a recap of everything you've learned thus far about how neural networks are constructed:
Now our model has all the standard components of what people usually mean when they refer to a neural network:
- A set of nodes, analogous to neurons, organized in layers.
- A set of learned weights and biases representing the connections between each neural network layer and the layer beneath it. The layer beneath may be another neural network layer, or some other kind of layer.
- An activation function that transforms the output of each node in a layer. Different layers may have different activation functions.
A caveat: neural networks aren't necessarily always better than feature crosses, but neural networks do offer a flexible alternative that works well in many cases.