Nachdem Sie Ihre Daten mit statistischen und Visualisierungstechniken untersucht haben, sollten Sie sie so transformieren, dass Ihr Modell effektiver trainiert werden kann. Ziel der Normalisierung ist es, die Funktionen auf eine ähnliche Skala zu transformieren. Betrachten Sie beispielsweise die folgenden beiden Funktionen:
- Die Funktion
Xumfasst den Bereich von 154 bis 24.917.482. - Das Feature
Yumfasst den Bereich 5 bis 22.
Diese beiden Funktionen decken sehr unterschiedliche Bereiche ab. Bei der Normalisierung werden X und Y möglicherweise so angepasst, dass sie einen ähnlichen Bereich abdecken, z. B. 0 bis 1.
Die Normalisierung bietet folgende Vorteile:
- Trägt dazu bei, dass Modelle während des Trainings schneller konvergieren. Wenn verschiedene Features unterschiedliche Bereiche haben, kann der Gradientenabstieg „abprallen“ und die Konvergenz verlangsamen. Fortschrittlichere Optimierer wie Adagrad und Adam schützen vor diesem Problem, indem sie die effektive Lernrate im Laufe der Zeit ändern.
- So können Modelle bessere Vorhersagen ableiten. Wenn verschiedene Features unterschiedliche Bereiche haben, liefert das resultierende Modell möglicherweise weniger nützliche Vorhersagen.
- Hilft, die NaN-Falle zu vermeiden, wenn die Werte von Attributen sehr hoch sind.
NaN ist die Abkürzung für not a number (keine Zahl). Wenn ein Wert in einem Modell das Limit für die Gleitkommazahl-Genauigkeit überschreitet, wird der Wert vom System auf
NaNanstatt auf eine Zahl festgelegt. Wenn eine Zahl im Modell zu einem NaN wird, werden auch andere Zahlen im Modell schließlich zu einem NaN. - So kann das Modell geeignete Gewichte für jedes Feature lernen. Ohne die Skalierung von Features wird im Modell zu viel Wert auf Features mit großen Bereichen und zu wenig auf Features mit kleinen Bereichen gelegt.
Wir empfehlen, numerische Features zu normalisieren, die deutlich unterschiedliche Bereiche abdecken (z. B. Alter und Einkommen).
Wir empfehlen außerdem, ein einzelnes numerisches Feature zu normalisieren, das einen großen Bereich abdeckt, z. B. city population..
Betrachten Sie die folgenden beiden Funktionen:
- Der niedrigste Wert für die Funktion
Aist -0,5 und der höchste Wert ist +0,5. - Der niedrigste Wert für die Funktion
Bist -5,0 und der höchste Wert ist +5,0.
Feature A und Feature B haben relativ schmale Spannen. Die Spanne von Feature B ist jedoch zehnmal breiter als die von Feature A. Beispiele:
- Zu Beginn des Trainings geht das Modell davon aus, dass Merkmal
Bzehnmal „wichtiger“ ist als MerkmalA. - Das Training dauert länger als es sollte.
- Das resultierende Modell ist möglicherweise suboptimal.
Der Gesamtschaden durch die fehlende Normalisierung ist relativ gering. Wir empfehlen jedoch, Feature A und Feature B auf dieselbe Skala zu normalisieren, z. B. -1,0 bis +1,0.
Betrachten Sie nun zwei Features mit einer größeren Diskrepanz der Bereiche:
- Der niedrigste Wert für die Funktion
Cist -1 und der höchste +1. - Der niedrigste Wert für die Funktion
Dist +5.000 und der höchste +1.000.000.000.
Wenn Sie die Merkmale C und D nicht normalisieren, ist Ihr Modell wahrscheinlich suboptimal. Außerdem dauert das Training viel länger, bis es konvergiert, oder es konvergiert überhaupt nicht.
In diesem Abschnitt werden drei gängige Normalisierungsmethoden behandelt:
- lineare Skalierung
- Z-Score-Skalierung
- Logarithmische Skalierung
In diesem Abschnitt wird außerdem das Clipping behandelt. Obwohl Clipping keine echte Normalisierungstechnik ist, werden unregelmäßige numerische Features in Bereiche eingegrenzt, die bessere Modelle ergeben.
Lineare Skalierung
Lineare Skalierung (häufig nur Skalierung genannt) bedeutet, Gleitkommawerte aus ihrem natürlichen Bereich in einen Standardbereich zu konvertieren, in der Regel 0 bis 1 oder -1 bis +1.
Die lineare Skalierung ist eine gute Wahl, wenn alle folgenden Bedingungen erfüllt sind:
- Die Unter- und Obergrenzen Ihrer Daten ändern sich im Laufe der Zeit nicht wesentlich.
- Das Feature enthält wenige oder keine Ausreißer und diese sind nicht extrem.
- Die Funktion ist über ihren Bereich hinweg ungefähr gleichmäßig verteilt. Das bedeutet, dass in einem Histogramm für die meisten Werte ungefähr gleich hohe Balken zu sehen wären.
Angenommen, die menschliche age ist eine Funktion. Die lineare Skalierung ist eine gute Normalisierungstechnik für age, weil:
- Die ungefähren Unter- und Obergrenzen liegen zwischen 0 und 100.
ageenthält einen relativ geringen Prozentsatz von Ausreißern. Nur etwa 0,3% der Bevölkerung sind über 100 Jahre alt.- Obwohl bestimmte Altersgruppen etwas besser vertreten sind als andere, sollte ein großer Datensatz genügend Beispiele für alle Altersgruppen enthalten.
Übung: Wissen testen
Angenommen, Ihr Modell hat ein Feature namensnet_worth, das das Nettovermögen verschiedener Personen enthält. Wäre die lineare Skalierung eine gute Normalisierungstechnik für net_worth? Warum bzw. warum nicht?
Z-Score-Skalierung
Ein Z-Score gibt an, wie viele Standardabweichungen ein Wert vom Mittelwert entfernt ist. Ein Wert, der beispielsweise 2 Standardabweichungen über dem Mittelwert liegt, hat einen Z-Score von +2,0. Ein Wert, der 1,5 Standardabweichungen unter dem Mittelwert liegt, hat einen Z-Score von -1,5.
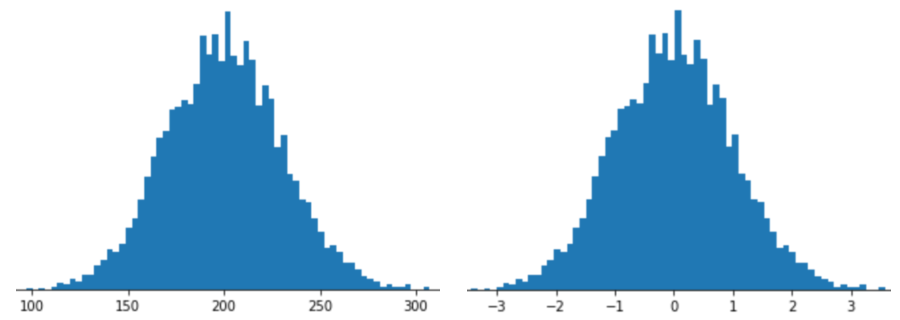
Wenn Sie ein Feature mit Z-Score-Skalierung darstellen, wird der Z-Score dieses Features im Feature-Vektor gespeichert. Die folgende Abbildung zeigt beispielsweise zwei Histogramme:
- Links sehen Sie eine klassische Normalverteilung.
- Rechts ist dieselbe Verteilung zu sehen, die durch die Z-Score-Skalierung normalisiert wurde.
Die Z-Score-Skalierung ist auch eine gute Wahl für Daten wie in der folgenden Abbildung, die nur eine vage Normalverteilung aufweisen.
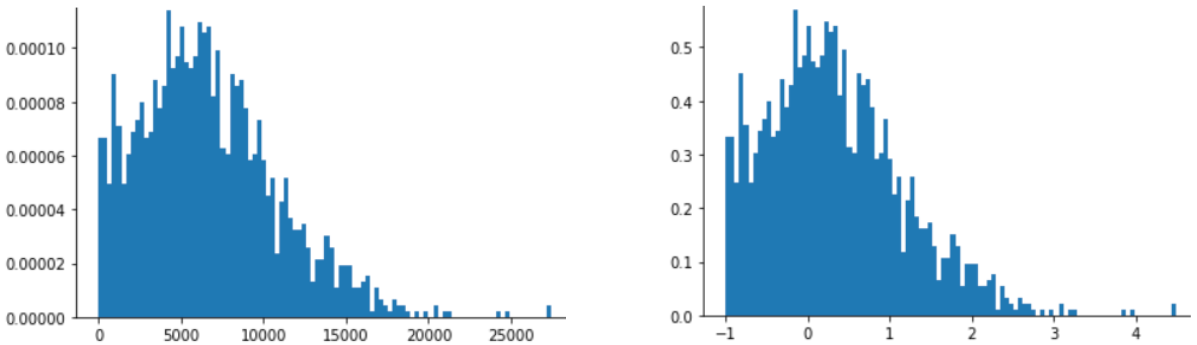
Der Z-Score ist eine gute Wahl, wenn die Daten einer Normalverteilung oder einer Verteilung ähneln, die einer Normalverteilung ähnelt.
Einige Verteilungen sind möglicherweise im Großteil ihres Bereichs normal, enthalten aber dennoch extreme Ausreißer. Beispielsweise passen fast alle Punkte eines net_worth-Features gut in 3 Standardabweichungen, aber einige Beispiele für dieses Feature könnten Hunderte von Standardabweichungen vom Mittelwert entfernt sein. In solchen Fällen können Sie die Z-Score-Skalierung mit einer anderen Form der Normalisierung (in der Regel Clipping) kombinieren, um dieses Problem zu beheben.
Übung: Wissen testen
Angenommen, Ihr Modell wird anhand eines Features namensheight trainiert, das die Körpergrößen von zehn Millionen Frauen im Erwachsenenalter enthält. Wäre die Z-Score-Skalierung eine gute Normalisierungstechnik für height? Warum bzw. warum nicht?
Logarithmische Skalierung
Bei der logarithmischen Skalierung wird der Logarithmus des Rohwerts berechnet. Theoretisch könnte der Logarithmus eine beliebige Basis haben. In der Praxis wird bei der logarithmischen Skalierung jedoch in der Regel der natürliche Logarithmus (ln) berechnet.
Die logarithmische Skalierung ist hilfreich, wenn die Daten einer Potenzgesetzverteilung entsprechen. Eine Potenzgesetzverteilung sieht so aus:
- Niedrige Werte von
Xhaben sehr hohe Werte vonY. - Wenn die Werte von
Xsteigen, sinken die Werte vonYschnell. Folglich haben hohe Werte vonXsehr niedrige Werte vonY.
Filmbewertungen sind ein gutes Beispiel für eine Potenzgesetzverteilung. Beachten Sie in der folgenden Abbildung:
- Einige Filme haben viele Nutzerbewertungen. Bei niedrigen Werten für
Xsind die Werte fürYhoch. - Die meisten Filme haben nur sehr wenige Nutzerbewertungen. (Hohe Werte für
Xhaben niedrige Werte fürY.)
Durch die logarithmische Skalierung wird die Verteilung geändert, was dazu beiträgt, ein Modell zu trainieren, das bessere Vorhersagen trifft.

Ein zweites Beispiel: Buchverkäufe folgen einer Potenzgesetzverteilung, weil:
- Die meisten veröffentlichten Bücher verkaufen sich nur in geringer Stückzahl, vielleicht ein- oder zweihundert Mal.
- Einige Bücher verkaufen sich in mittlerer Anzahl, also in Tausenderhöhe.
- Nur wenige Bestseller werden mehr als eine Million Mal verkauft.
Angenommen, Sie trainieren ein lineares Modell, um die Beziehung zwischen beispielsweise Buchcovern und Buchverkäufen zu ermitteln. Bei einem linearen Modell, das auf Rohwerten trainiert wird, müsste etwas an den Buchcovern von Büchern, die eine Million Mal verkauft werden, 10.000-mal wichtiger sein als bei Buchcovern von Büchern, die nur 100-mal verkauft werden. Wenn Sie jedoch alle Umsatzzahlen logarithmisch skalieren, wird die Aufgabe viel einfacher. Der Logarithmus von 100 ist beispielsweise:
~4.6 = ln(100)
Der Logarithmus von 1.000.000 ist:
~13.8 = ln(1,000,000)
Der Logarithmus von 1.000.000 ist also nur etwa dreimal so groß wie der Logarithmus von 100. Sie können sich wahrscheinlich vorstellen, dass ein Bestseller-Buchcover in gewisser Weise etwa dreimal so wirkungsvoll ist wie ein Buchcover, das sich nur wenig verkauft.
Clipping
Clipping ist eine Technik, um den Einfluss extremer Ausreißer zu minimieren. Kurz gesagt: Beim Clipping wird der Wert von Ausreißern in der Regel auf einen bestimmten Höchstwert begrenzt (reduziert). Das Clipping ist eine seltsame Idee, kann aber sehr effektiv sein.
Angenommen, Sie haben ein Dataset mit einem Feature namens roomsPerPerson, das die Anzahl der Zimmer (Gesamtzahl der Zimmer geteilt durch die Anzahl der Bewohner) für verschiedene Häuser darstellt. Das folgende Diagramm zeigt, dass über 99% der Funktionswerte einer Normalverteilung entsprechen (ungefähr ein Mittelwert von 1,8 und eine Standardabweichung von 0,7). Die Funktion enthält jedoch einige Ausreißer, darunter auch extreme:
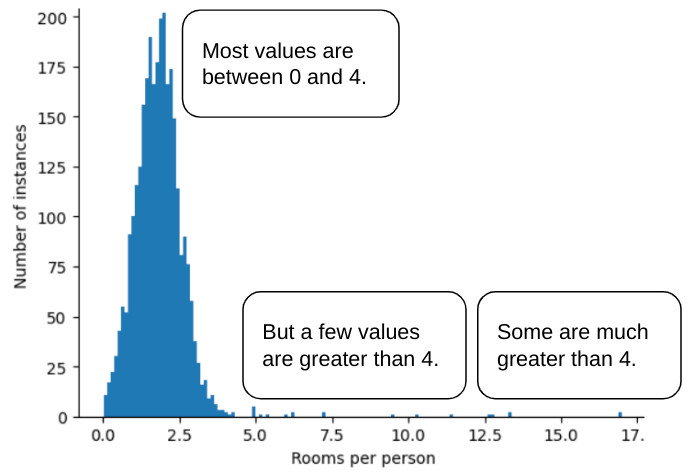
Wie können Sie den Einfluss dieser extremen Ausreißer minimieren? Das Histogramm ist keine gleichmäßige Verteilung, keine Normalverteilung und keine Potenzgesetzverteilung. Was wäre, wenn Sie den Höchstwert von roomsPerPerson einfach auf einen beliebigen Wert, z. B. 4,0, begrenzen oder beschneiden?
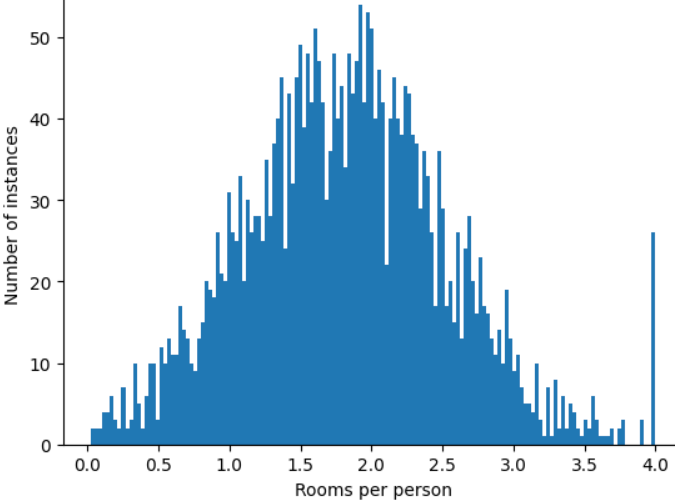
Wenn Sie den Feature-Wert auf 4,0 begrenzen, bedeutet das nicht, dass Ihr Modell alle Werte über 4,0 ignoriert. Stattdessen bedeutet es, dass alle Werte, die größer als 4,0 waren, jetzt 4,0 sind. Das erklärt den ungewöhnlichen Anstieg bei 4,0. Trotz dieses Hügels ist der skalierte Funktionsumfang jetzt nützlicher als die Originaldaten.
Warte mal! Kann man wirklich jeden Ausreißerwert auf einen beliebigen oberen Schwellenwert reduzieren? Ja, beim Trainieren eines Modells.
Sie können Werte auch nach der Anwendung anderer Formen der Normalisierung begrenzen. Angenommen, Sie verwenden die Z-Score-Skalierung, aber einige Ausreißer haben absolute Werte, die viel größer als 3 sind. In diesem Fall haben Sie folgende Möglichkeiten:
- Z-Werte für Clips, die größer als 3 sind, werden auf genau 3 begrenzt.
- Z-Scores für Clips, die kleiner als -3 sind, werden auf genau -3 gesetzt.
Durch das Beschneiden wird verhindert, dass Ihr Modell unwichtige Daten zu stark gewichtet. Einige Ausreißer sind jedoch wichtig. Daher sollten Sie Werte sorgfältig begrenzen.
Zusammenfassung der Normalisierungstechniken
| Normalisierungstechnik | Formel | Anwendung |
|---|---|---|
| Lineare Skalierung | $$ x' = \frac{x - x_{min}}{x_{max} - x_{min}} $$ | Wenn die Funktion über den Bereich hinweg weitgehend gleichmäßig verteilt ist. Flach |
| Z-Score-Skalierung | $$ x' = \frac{x - μ}{σ}$$ | Wenn das Feature normalverteilt ist (Spitze in der Nähe des Mittelwerts). Glockenförmig |
| Logarithmische Skalierung | $$ x' = log(x)$$ | Wenn die Feature-Verteilung auf mindestens einer Seite des Tails stark verzerrt ist. Heavy Tail-förmig |
| Clipping | Wenn $x > max$, setze $x' = max$ Wenn $x < min$, setze $x' = min$ |
Wenn das Feature extreme Ausreißer enthält. |
Übung: Wissen testen

Angenommen, Sie entwickeln ein Modell, das die Produktivität eines Rechenzentrums auf Grundlage der im Rechenzentrum gemessenen Temperatur vorhersagt.
Fast alle temperature-Werte in Ihrem Dataset liegen zwischen 15 und 30 °C. Die folgenden Ausnahmen sind jedoch zu beachten:
- Ein- bis zweimal pro Jahr werden an extrem heißen Tagen in
temperatureeinige Werte zwischen 31 und 45 aufgezeichnet. - Jeder 1.000. Punkt in
temperaturewird auf 1.000 anstatt auf die tatsächliche Temperatur gesetzt.
Welche Normalisierungstechnik wäre für temperature angemessen?
Die Werte von 1.000 sind Fehler und sollten gelöscht statt gekürzt werden.
Die Werte zwischen 31 und 45 sind zulässige Datenpunkte. Das Beschneiden dieser Werte wäre wahrscheinlich eine gute Idee, sofern das Dataset nicht genügend Beispiele in diesem Temperaturbereich enthält, um das Modell so zu trainieren, dass es gute Vorhersagen treffen kann. Bei der Inferenz würde das gekürzte Modell jedoch für eine Temperatur von 45 °C dieselbe Vorhersage treffen wie für eine Temperatur von 35 °C.