Sau khi kiểm tra dữ liệu bằng các kỹ thuật thống kê và trực quan hoá, bạn nên chuyển đổi dữ liệu theo cách sẽ giúp mô hình của bạn huấn luyện hiệu quả hơn. Mục tiêu của việc chuẩn hoá là chuyển đổi các đối tượng thành một tỷ lệ tương tự. Ví dụ: hãy xem xét 2 tính năng sau:
- Đối tượng
Xcó phạm vi từ 154 đến 24.917.482. - Đặc điểm
Ytrải dài từ 5 đến 22.
Hai tính năng này có phạm vi rất khác nhau. Quá trình chuẩn hoá có thể thao tác X và Y để chúng trải rộng trên một dải tương tự, có thể là từ 0 đến 1.
Việc chuẩn hoá mang lại những lợi ích sau:
- Giúp các mô hình hội tụ nhanh hơn trong quá trình huấn luyện. Khi các đối tượng có nhiều phạm vi khác nhau, phương pháp hạ dốc có thể "bật" và làm chậm quá trình hội tụ. Tuy nhiên, các trình tối ưu hoá nâng cao hơn như Adagrad và Adam sẽ bảo vệ bạn khỏi vấn đề này bằng cách thay đổi tốc độ học tập hiệu quả theo thời gian.
- Giúp các mô hình suy luận để đưa ra dự đoán chính xác hơn. Khi các đối tượng có nhiều phạm vi khác nhau, mô hình kết quả có thể đưa ra những dự đoán ít hữu ích hơn.
- Giúp tránh "bẫy NaN" khi giá trị của đối tượng rất cao.
NaN là từ viết tắt của không phải là số. Khi một giá trị trong mô hình vượt quá giới hạn độ chính xác của số thực dấu phẩy động, hệ thống sẽ đặt giá trị thành
NaNthay vì một số. Khi một số trong mô hình trở thành NaN, các số khác trong mô hình cũng sẽ trở thành NaN. - Giúp mô hình tìm hiểu các trọng số phù hợp cho từng đối tượng. Nếu không có tính năng điều chỉnh tỷ lệ, mô hình sẽ chú ý quá nhiều đến các tính năng có phạm vi rộng và không đủ chú ý đến các tính năng có phạm vi hẹp.
Bạn nên chuẩn hoá các đặc điểm bằng số bao gồm các phạm vi khác nhau rõ rệt (ví dụ: độ tuổi và thu nhập).
Bạn cũng nên chuẩn hoá một đặc điểm số duy nhất bao gồm nhiều phạm vi, chẳng hạn như city population.
Hãy cân nhắc 2 tính năng sau:
- Giá trị thấp nhất của đối tượng
Alà -0,5 và giá trị cao nhất là +0,5. - Giá trị thấp nhất của đối tượng
Blà -5.0 và cao nhất là +5.0.
Đối tượng A và Đối tượng B có khoảng cách tương đối hẹp. Tuy nhiên, khoảng cách của Đối tượng B rộng gấp 10 lần khoảng cách của Đối tượng A. Vì thế:
- Khi bắt đầu huấn luyện, mô hình giả định rằng Đặc điểm
Bquan trọng hơn Đặc điểmAgấp 10 lần. - Quá trình huấn luyện sẽ mất nhiều thời gian hơn bình thường.
- Mô hình thu được có thể không tối ưu.
Nhìn chung, thiệt hại do không chuẩn hoá sẽ tương đối nhỏ; tuy nhiên, bạn vẫn nên chuẩn hoá Đặc điểm A và Đặc điểm B theo cùng một tỷ lệ, có thể là từ -1,0 đến +1,0.
Bây giờ, hãy xem xét 2 đối tượng có sự khác biệt lớn hơn về phạm vi:
- Giá trị thấp nhất của tính năng
Clà -1 và cao nhất là +1. - Giá trị thấp nhất của tính năng
Dlà +5000 và giá trị cao nhất là +1.000.000.000.
Nếu bạn không chuẩn hoá Đặc điểm C và Đặc điểm D, mô hình của bạn có thể sẽ không đạt hiệu quả tối ưu. Hơn nữa, quá trình huấn luyện sẽ mất nhiều thời gian hơn để hội tụ hoặc thậm chí không hội tụ hoàn toàn!
Phần này đề cập đến 3 phương pháp chuẩn hoá phổ biến:
- thang đo tuyến tính
- Chuyển đổi tỷ lệ điểm Z
- chia tỷ lệ nhật ký
Phần này cũng đề cập đến việc cắt. Mặc dù không phải là một kỹ thuật chuẩn hoá thực sự, nhưng việc cắt bớt sẽ giúp kiểm soát các đặc điểm số không theo quy tắc thành các phạm vi tạo ra mô hình tốt hơn.
Chia độ tuyến tính
Điều chỉnh tỷ lệ tuyến tính (thường được rút gọn thành điều chỉnh tỷ lệ) có nghĩa là chuyển đổi các giá trị dấu phẩy động từ phạm vi tự nhiên của chúng thành một phạm vi tiêu chuẩn – thường là từ 0 đến 1 hoặc từ -1 đến +1.
Bạn nên chọn phương pháp mở rộng tuyến tính khi đáp ứng tất cả các điều kiện sau:
- Giới hạn dưới và giới hạn trên của dữ liệu không thay đổi nhiều theo thời gian.
- Đối tượng này có ít hoặc không có giá trị ngoại lệ và những giá trị ngoại lệ đó không phải là giá trị cực đoan.
- Đối tượng có phân bố gần như đồng đều trong phạm vi của đối tượng. Tức là biểu đồ tần suất sẽ cho thấy các thanh gần như bằng nhau cho hầu hết các giá trị.
Giả sử age của con người là một đặc điểm. Điều chỉnh tỷ lệ tuyến tính là một kỹ thuật chuẩn hoá tốt cho age vì:
- Giới hạn dưới và giới hạn trên gần đúng là từ 0 đến 100.
agechứa một tỷ lệ tương đối nhỏ các giá trị ngoại lệ. Chỉ khoảng 0,3% dân số là trên 100 tuổi.- Mặc dù một số độ tuổi được thể hiện rõ ràng hơn những độ tuổi khác, nhưng một tập dữ liệu lớn phải chứa đủ ví dụ về tất cả các độ tuổi.
Bài tập: Kiểm tra mức độ hiểu biết của bạn
Giả sử mô hình của bạn có một tính năng tên lànet_worth, chứa giá trị tài sản ròng của nhiều người. Liệu việc điều chỉnh tỷ lệ tuyến tính có phải là một kỹ thuật chuẩn hoá phù hợp cho net_worth không? Tại sao (hoặc tại sao lại không)?
Chuyển đổi tỷ lệ điểm Z
Điểm Z là số độ lệch chuẩn của một giá trị so với giá trị trung bình. Ví dụ: một giá trị lớn hơn giá trị trung bình 2 độ lệch chuẩn có điểm Z là +2.0. Giá trị nhỏ hơn giá trị trung bình 1,5 độ lệch chuẩn có điểm Z là -1,5.
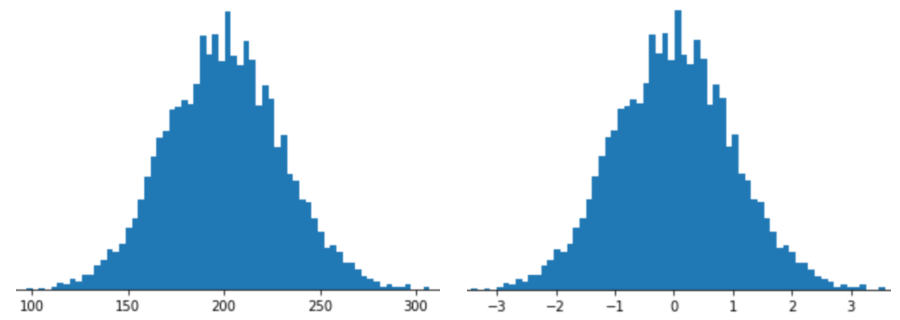
Việc biểu thị một đối tượng bằng thang đo điểm Z có nghĩa là lưu trữ điểm Z của đối tượng đó trong vectơ đối tượng. Ví dụ: hình sau đây cho thấy 2 biểu đồ tần suất:
- Ở bên trái, một hàm phân phối chuẩn cổ điển.
- Ở bên phải, cùng một hàm phân phối được chuẩn hoá bằng cách chia tỷ lệ điểm Z.
Việc điều chỉnh theo điểm Z cũng là một lựa chọn phù hợp cho dữ liệu như trong hình sau, chỉ có phân phối gần như bình thường.
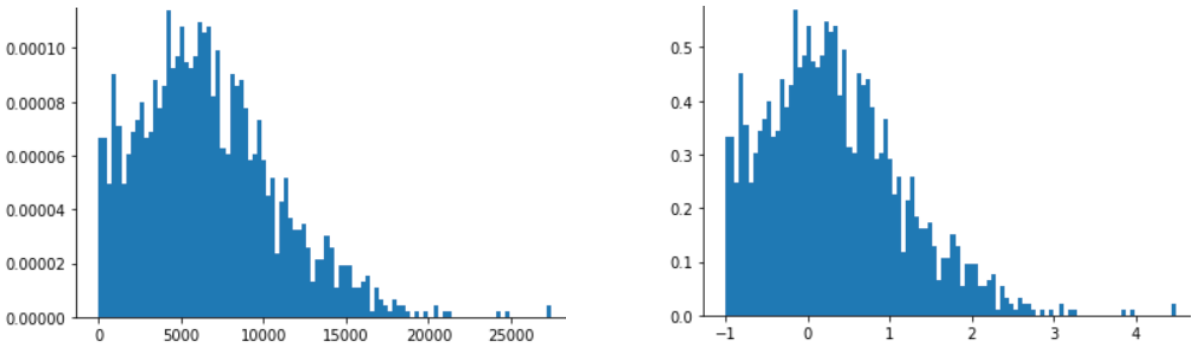
Điểm Z là lựa chọn phù hợp khi dữ liệu tuân theo phân phối chuẩn hoặc phân phối tương tự như phân phối chuẩn.
Xin lưu ý rằng một số phân phối có thể bình thường trong phần lớn phạm vi của chúng, nhưng vẫn chứa các giá trị ngoại lệ cực đoan. Ví dụ: hầu hết các điểm trong một đối tượng net_worth có thể nằm gọn trong 3 độ lệch chuẩn, nhưng một vài ví dụ về đối tượng này có thể cách xa giá trị trung bình hàng trăm độ lệch chuẩn. Trong những trường hợp này, bạn có thể kết hợp việc điều chỉnh điểm Z với một hình thức chuẩn hoá khác (thường là cắt bớt) để xử lý tình huống này.
Bài tập: Kiểm tra mức độ hiểu biết của bạn
Giả sử mô hình của bạn huấn luyện trên một đối tượng có tên làheight, chứa chiều cao của 10 triệu phụ nữ trưởng thành. Liệu việc điều chỉnh điểm Z có phải là một kỹ thuật chuẩn hoá phù hợp cho height không? Tại sao (hoặc tại sao lại không)?
Chia tỷ lệ nhật ký
Thang đo lôgarit tính toán lôgarit của giá trị thô. Về lý thuyết, lôgarit có thể là bất kỳ cơ số nào; trên thực tế, việc chia tỷ lệ theo logarit thường tính toán lôgarit tự nhiên (ln).
Việc điều chỉnh tỷ lệ theo hàm log sẽ hữu ích khi dữ liệu tuân theo phân phối quy luật lũy thừa. Nói một cách thông thường, hàm phân phối theo quy luật lũy thừa có dạng như sau:
- Giá trị thấp của
Xcó giá trị rất cao củaY. - Khi giá trị của
Xtăng lên, giá trị củaYsẽ giảm nhanh chóng. Do đó, các giá trị cao củaXcó các giá trị rất thấp củaY.
Mức phân loại phim là một ví dụ điển hình về phân phối theo quy luật lũy thừa. Trong hình sau, hãy lưu ý:
- Một số bộ phim có nhiều điểm xếp hạng của người dùng. (Giá trị
Xthấp thì giá trịYcao.) - Hầu hết các bộ phim đều có rất ít lượt đánh giá của người dùng. (Giá trị
Xcao có giá trịYthấp.)
Việc điều chỉnh tỷ lệ nhật ký sẽ thay đổi phân phối, giúp huấn luyện một mô hình đưa ra dự đoán chính xác hơn.

Ví dụ thứ hai, doanh số bán sách tuân theo quy luật phân phối lũy thừa vì:
- Hầu hết các cuốn sách đã xuất bản chỉ bán được một số lượng rất nhỏ, có thể là một hoặc hai trăm bản.
- Một số cuốn sách bán được số lượng vừa phải, khoảng vài nghìn bản.
- Chỉ một vài cuốn sách bán chạy nhất sẽ bán được hơn một triệu bản.
Giả sử bạn đang huấn luyện một mô hình tuyến tính để tìm mối quan hệ giữa, chẳng hạn như bìa sách với doanh số bán sách. Một mô hình tuyến tính được huấn luyện trên các giá trị thô sẽ phải tìm ra điều gì đó về bìa sách của những cuốn sách bán được một triệu bản mạnh hơn 10.000 lần so với bìa sách chỉ bán được 100 bản. Tuy nhiên, việc chia tỷ lệ tất cả số liệu bán hàng sẽ giúp nhiệm vụ này trở nên khả thi hơn nhiều. Ví dụ: logarit của 100 là:
~4.6 = ln(100)
trong khi log của 1.000.000 là:
~13.8 = ln(1,000,000)
Vì vậy, log của 1.000.000 chỉ lớn hơn khoảng 3 lần so với log của 100. Có lẽ bạn có thể tưởng tượng rằng một bìa sách bán chạy sẽ mạnh hơn khoảng 3 lần (theo một cách nào đó) so với một bìa sách bán rất ít.
Cắt
Cắt bớt là một kỹ thuật giúp giảm thiểu ảnh hưởng của các giá trị ngoại lệ cực đoan. Nói tóm lại, việc cắt thường giới hạn (giảm) giá trị của các giá trị ngoại lệ xuống một giá trị tối đa cụ thể. Cắt là một ý tưởng kỳ lạ, nhưng nó có thể rất hiệu quả.
Ví dụ: hãy tưởng tượng một tập dữ liệu chứa một đối tượng có tên là roomsPerPerson, đại diện cho số phòng (tổng số phòng chia cho số người cư trú) của nhiều ngôi nhà. Biểu đồ sau đây cho thấy hơn 99% giá trị của tính năng tuân theo phân phối chuẩn (xấp xỉ giá trị trung bình là 1,8 và độ lệch chuẩn là 0,7). Tuy nhiên, tính năng này có một số giá trị ngoại lệ, trong đó có một số giá trị cực đoan:
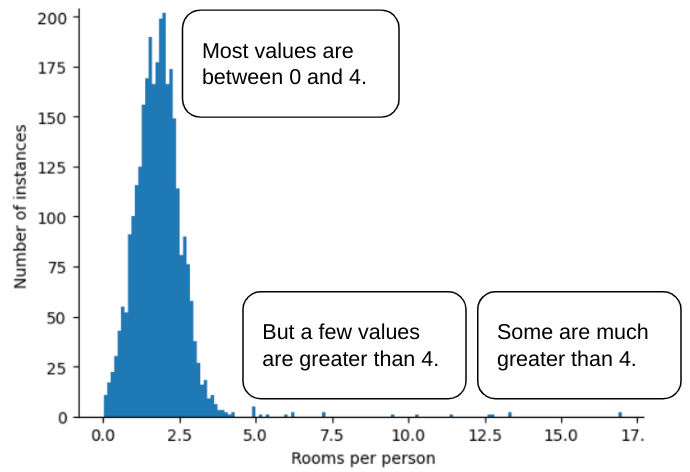
Làm cách nào để giảm thiểu ảnh hưởng của những giá trị ngoại lệ cực đoan đó? Biểu đồ này không phải là một phân phối đồng đều, phân phối chuẩn hay phân phối theo quy luật lũy thừa. Điều gì sẽ xảy ra nếu bạn chỉ cần giới hạn hoặc cắt giá trị tối đa của roomsPerPerson ở một giá trị tuỳ ý, chẳng hạn như 4,0?
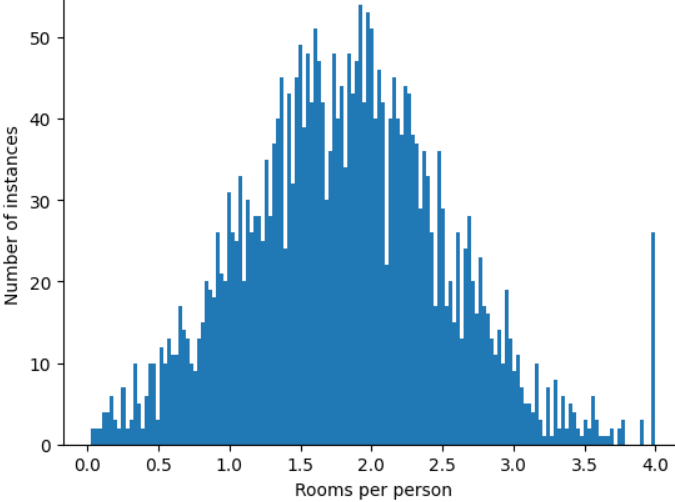
Việc cắt giá trị của đặc điểm ở mức 4.0 không có nghĩa là mô hình của bạn bỏ qua tất cả các giá trị lớn hơn 4.0. Thay vào đó, điều này có nghĩa là tất cả các giá trị lớn hơn 4.0 giờ đây sẽ trở thành 4.0. Điều này giải thích cho ngọn đồi đặc biệt ở 4.0. Mặc dù có sự khác biệt đó, nhưng hiện tại, tập hợp các đối tượng được mở rộng hữu ích hơn dữ liệu ban đầu.
Đợi một chút! Bạn có thực sự giảm mọi giá trị ngoại lệ xuống một ngưỡng trên tuỳ ý nào đó không? Có, khi huấn luyện mô hình.
Bạn cũng có thể cắt các giá trị sau khi áp dụng các hình thức chuẩn hoá khác. Ví dụ: giả sử bạn sử dụng phương pháp chia tỷ lệ điểm Z, nhưng một số giá trị ngoại lệ có giá trị tuyệt đối lớn hơn 3. Trong trường hợp này, bạn có thể:
- Cắt các điểm Z lớn hơn 3 thành đúng 3.
- Cắt các điểm Z nhỏ hơn -3 thành chính xác -3.
Tính năng cắt bớt giúp mô hình của bạn không bị lập chỉ mục quá mức đối với dữ liệu không quan trọng. Tuy nhiên, một số giá trị ngoại lệ thực sự quan trọng, vì vậy, hãy cắt các giá trị một cách cẩn thận.
Tóm tắt các kỹ thuật chuẩn hoá
| Kỹ thuật chuẩn hoá | Công thức | Trường hợp sử dụng |
|---|---|---|
| Chia độ tuyến tính | $$ x' = \frac{x - x_{min}}{x_{max} - x_{min}} $$ | Khi đối tượng được phân phối đồng đều trong phạm vi. Dạng phẳng |
| Chuyển đổi tỷ lệ điểm Z | $$ x' = \frac{x - μ}{σ}$$ | Khi đối tượng được phân phối chuẩn (đỉnh gần với giá trị trung bình). Hình chuông |
| Chia tỷ lệ nhật ký | $$ x' = log(x)$$ | Khi phân phối tính năng bị lệch nhiều ở ít nhất một trong hai phía của phần đuôi. Đuôi nặng |
| Cắt | Nếu $x > max$, hãy đặt $x' = max$ Nếu $x < min$, hãy đặt $x' = min$ |
Khi đối tượng có giá trị ngoại lệ cực đoan. |
Bài tập: Kiểm tra kiến thức

Giả sử bạn đang phát triển một mô hình dự đoán năng suất của một trung tâm dữ liệu dựa trên nhiệt độ đo được bên trong trung tâm dữ liệu.
Hầu hết các giá trị temperature trong tập dữ liệu của bạn đều nằm trong khoảng từ 15 đến 30 (độ C), ngoại trừ những giá trị sau:
- Một hoặc hai lần mỗi năm, vào những ngày cực kỳ nóng, một số giá trị từ 31 đến 45 được ghi nhận ở
temperature. - Cứ 1.000 điểm trong
temperaturesẽ được đặt thành 1.000 thay vì nhiệt độ thực tế.
Đâu là kỹ thuật chuẩn hoá hợp lý cho temperature?
Giá trị 1.000 là sai và cần được xoá thay vì bị cắt.
Các giá trị từ 31 đến 45 là các điểm dữ liệu hợp lệ. Việc cắt có lẽ là một ý tưởng hay cho những giá trị này, giả sử tập dữ liệu không chứa đủ ví dụ trong phạm vi nhiệt độ này để huấn luyện mô hình đưa ra dự đoán chính xác. Tuy nhiên, trong quá trình suy luận, lưu ý rằng mô hình bị cắt do đó sẽ đưa ra cùng một dự đoán cho nhiệt độ 45 như cho nhiệt độ 35.