소개
이 문서에서는 Places Insights 데이터 세트, BigQuery의 공개 지리공간 데이터, 장소 세부정보 API를 결합하여 입지 선정 솔루션을 구축하는 방법을 설명합니다.
이 데모는 Google Cloud Next 2025에서 제공된 데모를 기반으로 하며, YouTube에서 시청할 수 있습니다. 문서에 설명된 프로세스의 코드가 포함된 예시 Colab 노트북도 제공됩니다.
비즈니스 과제
성공적인 커피숍 체인을 운영하고 있으며 네바다와 같이 진출하지 않은 새로운 주에 진출하려고 한다고 가정해 보겠습니다. 새 매장을 여는 것은 상당한 투자가 필요하며, 데이터 기반 결정을 내리는 것이 성공에 매우 중요합니다. 어디서부터 시작해야 하지?
이 가이드에서는 다층 분석을 통해 새 커피숍에 가장 적합한 위치를 파악하는 방법을 설명합니다. 주 전체 보기로 시작하여 특정 카운티와 상업 지역으로 검색 범위를 점진적으로 좁히고, 마지막으로 초지역 분석을 실행하여 개별 지역을 평가하고 경쟁업체를 매핑하여 시장 격차를 파악합니다.
솔루션 워크플로
이 프로세스는 광범위하게 시작하여 검색 영역을 구체화하고 최종 사이트 선택에 대한 신뢰도를 높이기 위해 점진적으로 더 세분화되는 논리적 유입경로를 따릅니다.
기본 요건 및 환경 설정
분석을 시작하기 전에 몇 가지 주요 기능이 있는 환경이 필요합니다. 이 가이드에서는 SQL과 Python을 사용하는 구현을 설명하지만 일반적인 원칙은 다른 기술 스택에도 적용할 수 있습니다.
전제 조건으로 환경에서 다음을 수행할 수 있어야 합니다.
- BigQuery에서 쿼리를 실행합니다.
- 장소 통계에 액세스합니다. 자세한 내용은 장소 통계 설정을 참고하세요.
bigquery-public-data및 미국 인구조사국 카운티 인구 합계의 공개 데이터 세트를 구독합니다.
또한 지도에서 지리정보 데이터를 시각화할 수 있어야 합니다. 이는 각 분석 단계의 결과를 해석하는 데 매우 중요합니다. 이를 달성하는 방법은 다양합니다. BigQuery에 직접 연결되는 Looker Studio와 같은 BI 도구를 사용하거나 Python과 같은 데이터 과학 언어를 사용할 수 있습니다.
주 수준 분석: 최적의 카운티 찾기
첫 번째 단계는 네바다에서 가장 유망한 카운티를 파악하기 위한 광범위한 분석입니다. 유망은 인구가 많고 기존 레스토랑의 밀도가 높아 강력한 식음료 문화를 나타내는 조합으로 정의됩니다.
BigQuery 쿼리는 Places Insights 데이터 세트 내에서 사용할 수 있는 기본 주소 구성요소를 활용하여 이를 달성합니다. 이 쿼리는 먼저 administrative_area_level_1_name 필드를 사용하여 네바다주 내의 장소만 포함하도록 데이터를 필터링하여 식당을 집계합니다. 그런 다음 유형 배열에 'restaurant'가 포함된 장소만 포함하도록 이 집합을 추가로 구체화합니다. 마지막으로, 이러한 결과를 군 이름(administrative_area_level_2_name)으로 그룹화하여 각 군의 개수를 생성합니다. 이 접근 방식은 데이터 세트의 내장된 사전 색인 주소 구조를 활용합니다.
다음 발췌문은 군 지오메트리를 Places Insights와 결합하고 특정 장소 유형(restaurant)을 필터링하는 방법을 보여줍니다.
SELECT WITH AGGREGATION_THRESHOLD
administrative_area_level_2_name,
COUNT(*) AS restaurant_count
FROM
`places_insights___us.places`
WHERE
-- Filter for the state of Nevada
administrative_area_level_1_name = 'Nevada'
-- Filter for places that are restaurants
AND 'restaurant' IN UNNEST(types)
-- Filter for operational places only
AND business_status = 'OPERATIONAL'
-- Exclude rows where the county name is null
AND administrative_area_level_2_name IS NOT NULL
GROUP BY
administrative_area_level_2_name
ORDER BY
restaurant_count DESC
식당의 단순 개수만으로는 충분하지 않습니다. 시장 포화도와 기회를 제대로 파악하려면 인구 데이터와 균형을 맞춰야 합니다. 미국 인구조사국 카운티 인구 합계의 인구 데이터를 사용합니다.
매우 다른 두 측정항목 (장소 수와 인구수)을 비교하기 위해 최소-최대 정규화를 사용합니다. 이 기법은 두 측정항목을 공통 범위 (0~1)로 조정합니다. 그런 다음 이를 하나의 normalized_score로 결합하여 균형 잡힌 비교를 위해 각 측정항목에 50% 의 가중치를 부여합니다.
이 발췌문에서는 점수 계산의 핵심 논리를 보여줍니다. 정규화된 인구수와 레스토랑 수를 결합합니다.
(
-- Normalize restaurant count (scales to a 0-1 value) and apply 50% weight
SAFE_DIVIDE(restaurant_count - min_restaurants, max_restaurants - min_restaurants) * 0.5
+
-- Normalize population (scales to a 0-1 value) and apply 50% weight
SAFE_DIVIDE(population_2023 - min_pop, max_pop - min_pop) * 0.5
) AS normalized_score
전체 쿼리를 실행하면 카운티, 레스토랑 수, 인구, 정규화된 점수의 목록이 반환됩니다. normalized_score
DESC로 정렬하면 클라크 카운티가 1위 후보로 추가 조사가 필요한 것으로 나타납니다.

이 스크린샷은 정규화된 점수가 가장 높은 상위 4개 카운티를 보여줍니다. 원시 인구수는 이 예에서 의도적으로 생략되었습니다.
군 수준 분석: 가장 번화한 상업 지구 찾기
이제 클라크 카운티를 확인했으므로 다음 단계는 상업 활동이 가장 활발한 우편번호를 찾기 위해 확대하는 것입니다. 기존 커피숍의 데이터를 기반으로 주요 브랜드가 밀집된 지역에 위치할 때 실적이 더 좋다는 것을 알 수 있으므로 이를 유동 인구의 대리 변수로 사용하겠습니다.
이 쿼리는 특정 브랜드에 관한 정보가 포함된 Places Insights 내의 brands 테이블을 사용합니다. 이 표를 쿼리하여 지원되는 브랜드 목록을 확인할 수 있습니다. 먼저 타겟 브랜드 목록을 정의한 다음 이 목록을 기본 장소 통계 데이터 세트와 결합하여 클라크 카운티의 각 우편번호에 속하는 특정 매장의 수를 집계합니다.
이를 달성하는 가장 효율적인 방법은 2단계 접근 방식을 사용하는 것입니다.
- 먼저 빠르고 비공간적 집계를 실행하여 각 우편번호 내의 브랜드를 계산합니다.
- 그런 다음 이러한 결과를 공개 데이터 세트에 조인하여 시각화를 위한 지도 경계를 가져옵니다.
postal_code_names 필드를 사용하여 브랜드 수 계산
이 첫 번째 쿼리는 핵심 집계 로직을 실행합니다. 클라크 카운티의 장소를 필터링한 다음 postal_code_names 배열을 중첩 해제하여 우편번호별로 브랜드 수를 그룹화합니다.
WITH brand_names AS (
-- First, select the chains we are interested in by name
SELECT
id,
name
FROM
`places_insights___us.brands`
WHERE
name IN ('7-Eleven', 'CVS', 'Walgreens', 'Subway Restaurants', "McDonald's")
)
SELECT WITH AGGREGATION_THRESHOLD
postal_code,
COUNT(*) AS total_brand_count
FROM
`places_insights___us.places` AS places_table,
-- Unnest the built-in postal code and brand ID arrays
UNNEST(places_table.postal_code_names) AS postal_code,
UNNEST(places_table.brand_ids) AS brand_id
JOIN
brand_names
ON brand_names.id = brand_id
WHERE
-- Filter directly on the administrative area fields in the places table
places_table.administrative_area_level_2_name = 'Clark County'
AND places_table.administrative_area_level_1_name = 'Nevada'
GROUP BY
postal_code
ORDER BY
total_brand_count DESC
출력은 우편번호와 해당 브랜드 수의 표입니다.

매핑을 위해 우편번호 지오메트리 첨부
이제 개수를 파악했으므로 시각화에 필요한 다각형 모양을 가져올 수 있습니다. 두 번째 쿼리는 첫 번째 쿼리를 가져와 brand_counts_by_zip라는 공통 테이블 표현식 (CTE)으로 래핑하고 결과를 공개 geo_us_boundaries.zip_codes table에 조인합니다. 이렇게 하면 미리 계산된 개수에 지오메트리가 효율적으로 연결됩니다.
WITH brand_counts_by_zip AS (
-- This will be the entire query from the previous step, without the final ORDER BY (excluded for brevity).
. . .
)
-- Now, join the aggregated results to the boundaries table
SELECT
counts.postal_code,
counts.total_brand_count,
-- Simplify the geometry for faster rendering in maps
ST_SIMPLIFY(zip_boundaries.zip_code_geom, 100) AS geography
FROM
brand_counts_by_zip AS counts
JOIN
`bigquery-public-data.geo_us_boundaries.zip_codes` AS zip_boundaries
ON counts.postal_code = zip_boundaries.zip_code
ORDER BY
counts.total_brand_count DESC
출력은 우편번호, 해당 브랜드 수, 우편번호 지오메트리 테이블입니다.

이 데이터를 히트맵으로 시각화할 수 있습니다. 진한 빨간색 영역은 타겟 브랜드의 집중도가 높음을 나타내며, 라스베이거스에서 상업적으로 가장 밀집된 지역을 가리킵니다.

초지역 분석: 개별 그리드 영역 점수 매기기
라스베이거스의 대략적인 위치를 파악했으므로 이제 세부적인 분석을 할 차례입니다. 여기에 Google의 구체적인 비즈니스 지식을 더합니다. Google은 오전 늦은 시간과 점심시간과 같이 피크 시간대에 바쁜 다른 비즈니스 근처에 있는 커피숍이 번성한다는 것을 알고 있습니다.
다음 쿼리는 매우 구체적입니다. 표준 H3 지리 공간 색인 (해상도 8)을 사용하여 라스베이거스 대도시 지역에 미세한 육각형 그리드를 만들어 마이크로 수준에서 지역을 분석합니다. 이 쿼리는 먼저 피크 시간대 (월요일, 오전 10시~오후 2시)에 영업하는 모든 보완 비즈니스를 식별합니다.
그런 다음 각 장소 유형에 가중 점수를 적용합니다. 인근 음식점은 편의점보다 더 가치가 있으므로 승수가 더 높습니다. 이렇게 하면 각 작은 영역에 맞게 맞춤설정된 suitability_score가 제공됩니다.
이 발췌문에서는 영업시간 확인을 위해 미리 계산된 플래그 (is_open_monday_window)를 참조하는 가중치 부여 점수 매기기 로직을 강조합니다.
. . .
(
COUNTIF('restaurant' IN UNNEST(types) AND is_open_monday_window) * 8 +
COUNTIF('convenience_store' IN UNNEST(types) AND is_open_monday_window) * 3 +
COUNTIF('bar' IN UNNEST(types) AND is_open_monday_window) * 7 +
COUNTIF('tourist_attraction' IN UNNEST(types) AND is_open_monday_window) * 6 +
COUNTIF('casino' IN UNNEST(types) AND is_open_monday_window) * 7
) AS suitability_score
. . .
전체 쿼리 펼치기
-- This query calculates a custom 'suitability score' for different areas in the Las Vegas -- metropolitan area to identify prime commercial zones. It uses a weighted model based -- on the density of specific business types that are open during a target time window. -- Step 1: Pre-filter the dataset to only include relevant places. -- This CTE finds all places in our target localities (Las Vegas, Spring Valley, etc.) and -- adds a boolean flag 'is_open_monday_window' for those open during the target time. WITH PlacesInTargetAreaWithOpenFlag AS ( SELECT point, types, EXISTS( SELECT 1 FROM UNNEST(regular_opening_hours.monday) AS monday_hours WHERE monday_hours.start_time <= TIME '10:00:00' AND monday_hours.end_time >= TIME '14:00:00' ) AS is_open_monday_window FROM `places_insights___us.places` WHERE EXISTS ( SELECT 1 FROM UNNEST(locality_names) AS locality WHERE locality IN ('Las Vegas', 'Spring Valley', 'Paradise', 'North Las Vegas', 'Winchester') ) AND administrative_area_level_1_name = 'Nevada' ), -- Step 2: Aggregate the filtered places into H3 cells and calculate the suitability score. -- Each place's location is converted to an H3 index (at resolution 8). The query then -- calculates a weighted 'suitability_score' and individual counts for each business type -- within that cell. TileScores AS ( SELECT WITH AGGREGATION_THRESHOLD -- Convert each place's geographic point into an H3 cell index. `carto-os.carto.H3_FROMGEOGPOINT`(point, 8) AS h3_index, -- Calculate the weighted score based on the count of places of each type -- that are open during the target window. ( COUNTIF('restaurant' IN UNNEST(types) AND is_open_monday_window) * 8 + COUNTIF('convenience_store' IN UNNEST(types) AND is_open_monday_window) * 3 + COUNTIF('bar' IN UNNEST(types) AND is_open_monday_window) * 7 + COUNTIF('tourist_attraction' IN UNNEST(types) AND is_open_monday_window) * 6 + COUNTIF('casino' IN UNNEST(types) AND is_open_monday_window) * 7 ) AS suitability_score, -- Also return the individual counts for each category for detailed analysis. COUNTIF('restaurant' IN UNNEST(types) AND is_open_monday_window) AS restaurant_count, COUNTIF('convenience_store' IN UNNEST(types) AND is_open_monday_window) AS convenience_store_count, COUNTIF('bar' IN UNNEST(types) AND is_open_monday_window) AS bar_count, COUNTIF('tourist_attraction' IN UNNEST(types) AND is_open_monday_window) AS tourist_attraction_count, COUNTIF('casino' IN UNNEST(types) AND is_open_monday_window) AS casino_count FROM -- CHANGED: This now references the CTE with the expanded area. PlacesInTargetAreaWithOpenFlag -- Group by the H3 index to ensure all calculations are per-cell. GROUP BY h3_index ), -- Step 3: Find the maximum suitability score across all cells. -- This value is used in the next step to normalize the scores to a consistent scale (e.g., 0-10). MaxScore AS ( SELECT MAX(suitability_score) AS max_score FROM TileScores ) -- Step 4: Assemble the final results. -- This joins the scored tiles with the max score, calculates the normalized score, -- generates the H3 cell's polygon geometry for mapping, and orders the results. SELECT ts.h3_index, -- Generate the hexagonal polygon for the H3 cell for visualization. `carto-os.carto.H3_BOUNDARY`(ts.h3_index) AS h3_geography, ts.restaurant_count, ts.convenience_store_count, ts.bar_count, ts.tourist_attraction_count, ts.casino_count, ts.suitability_score, -- Normalize the score to a 0-10 scale for easier interpretation. ROUND( CASE WHEN ms.max_score = 0 THEN 0 ELSE (ts.suitability_score / ms.max_score) * 10 END, 2 ) AS normalized_suitability_score FROM -- A cross join is efficient here as MaxScore contains only one row. TileScores ts, MaxScore ms -- Display the highest-scoring locations first. ORDER BY normalized_suitability_score DESC;
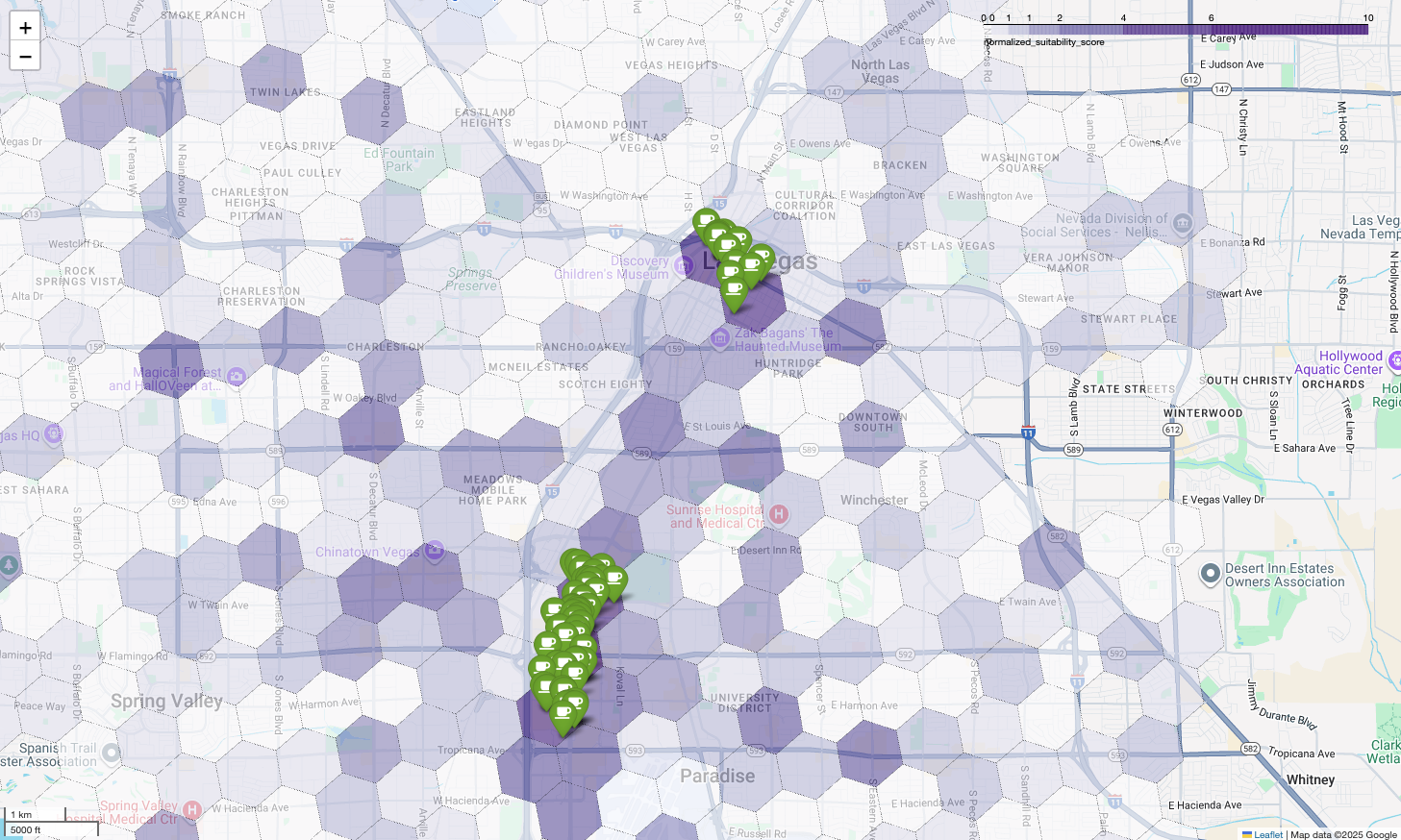
지도에 이러한 점수를 시각화하면 명확한 승리 위치가 표시됩니다. 라스베이거스 스트립과 다운타운 근처에 주로 있는 가장 어두운 보라색 타일은 새로운 커피숍의 잠재력이 가장 높은 지역입니다.

경쟁업체 분석: 기존 커피숍 식별
Google의 적합성 모델은 가장 유망한 지역을 성공적으로 식별했지만, 점수가 높다고 해서 성공이 보장되는 것은 아닙니다. 이제 이 데이터를 경쟁업체 데이터와 오버레이해야 합니다. 명확한 시장 격차를 찾고 있으므로 기존 커피숍의 밀도가 낮은 잠재력이 높은 지역이 이상적인 위치입니다.
이를 위해 PLACES_COUNT_PER_H3 함수를 사용합니다. 이 함수는 지정된 지리 내의 장소 수를 H3 셀별로 효율적으로 반환하도록 설계되었습니다.
먼저 라스베이거스 전체 광역권의 지리를 동적으로 정의합니다.
단일 지역에 의존하는 대신 공개 Overture Maps 데이터 세트를 쿼리하여 라스베이거스와 주요 주변 지역의 경계를 가져와 ST_UNION_AGG로 단일 다각형으로 병합합니다. 그런 다음 이 영역을 함수에 전달하여 운영 중인 모든 커피숍을 계산하도록 요청합니다.
이 쿼리는 대도시권을 정의하고 함수를 호출하여 H3 셀의 커피숍 수를 가져옵니다.
-- Define a variable to hold the combined geography for the Las Vegas metro area.
DECLARE las_vegas_metro_area GEOGRAPHY;
-- Set the variable by fetching the shapes for the five localities from Overture Maps
-- and merging them into a single polygon using ST_UNION_AGG.
SET las_vegas_metro_area = (
SELECT
ST_UNION_AGG(geometry)
FROM
`bigquery-public-data.overture_maps.division_area`
WHERE
country = 'US'
AND region = 'US-NV'
AND names.primary IN ('Las Vegas', 'Spring Valley', 'Paradise', 'North Las Vegas', 'Winchester')
);
-- Call the PLACES_COUNT_PER_H3 function with our defined area and parameters.
SELECT
*
FROM
`places_insights___us.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
-- Use the metro area geography we just created.
'geography', las_vegas_metro_area,
-- Specify 'coffee_shop' as the place type to count.
'types', ["coffee_shop"],
-- Best practice: Only count places that are currently operational.
'business_status', ['OPERATIONAL'],
-- Set the H3 grid resolution to 8.
'h3_resolution', 8
)
);
이 함수는 H3 셀 색인, 기하학적 구조, 총 커피숍 수, 커피숍의 장소 ID 샘플을 포함하는 표를 반환합니다.

집계된 수치도 유용하지만 실제 경쟁업체를 확인하는 것이 중요합니다.
여기에서 Places Insights 데이터 세트에서 Places API로 전환합니다. 정규화된 적합성 점수가 가장 높은 셀에서 sample_place_ids를 추출하면 장소 세부정보 API를 호출하여 이름, 주소, 평점, 위치와 같은 각 경쟁업체의 풍부한 세부정보를 가져올 수 있습니다.
이를 위해서는 적합성 점수가 생성된 이전 쿼리와 PLACES_COUNT_PER_H3 쿼리의 결과를 비교해야 합니다. H3 셀 색인을 사용하여 정규화된 적합성 점수가 가장 높은 셀에서 커피숍 수와 ID를 가져올 수 있습니다.
이 Python 코드는 이러한 비교를 수행하는 방법을 보여줍니다.
# Isolate the Top 5 Most Suitable H3 Cells
top_suitability_cells = gdf_suitability.head(5)
# Extract the 'h3_index' values from these top 5 cells into a list.
top_h3_indexes = top_suitability_cells['h3_index'].tolist()
print(f"The top 5 H3 indexes are: {top_h3_indexes}")
# Now, we find the rows in our DataFrame where the
# 'h3_cell_index' matches one of the indexes from our top 5 list.
coffee_counts_in_top_zones = gdf_coffee_shops[
gdf_coffee_shops['h3_cell_index'].isin(top_h3_indexes)
]
이제 적합성 점수가 가장 높은 H3 셀 내에 이미 있는 커피숍의 장소 ID 목록이 있으므로 각 장소에 관한 자세한 내용을 요청할 수 있습니다.
각 장소 ID에 대해 장소 세부정보 API에 직접 요청을 보내거나 클라이언트 라이브러리를 사용하여 호출을 실행하면 됩니다. 필요한 데이터만 요청하도록 FieldMask 매개변수를 설정해야 합니다.
마지막으로 모든 것을 결합하여 강력한 시각화를 만듭니다. 보라색 적합성 단계 구분도를 기본 레이어로 표시한 다음 Places API에서 가져온 각 개별 커피숍의 핀을 추가합니다. 이 최종 지도는 전체 분석을 종합한 한눈에 보기 뷰를 제공합니다. 어두운 보라색 영역은 잠재력을 보여주고 녹색 핀은 현재 시장의 현실을 보여줍니다.

핀이 거의 없거나 전혀 없는 진한 보라색 셀을 찾으면 새로운 위치에 가장 적합한 영역을 정확하게 파악할 수 있습니다.
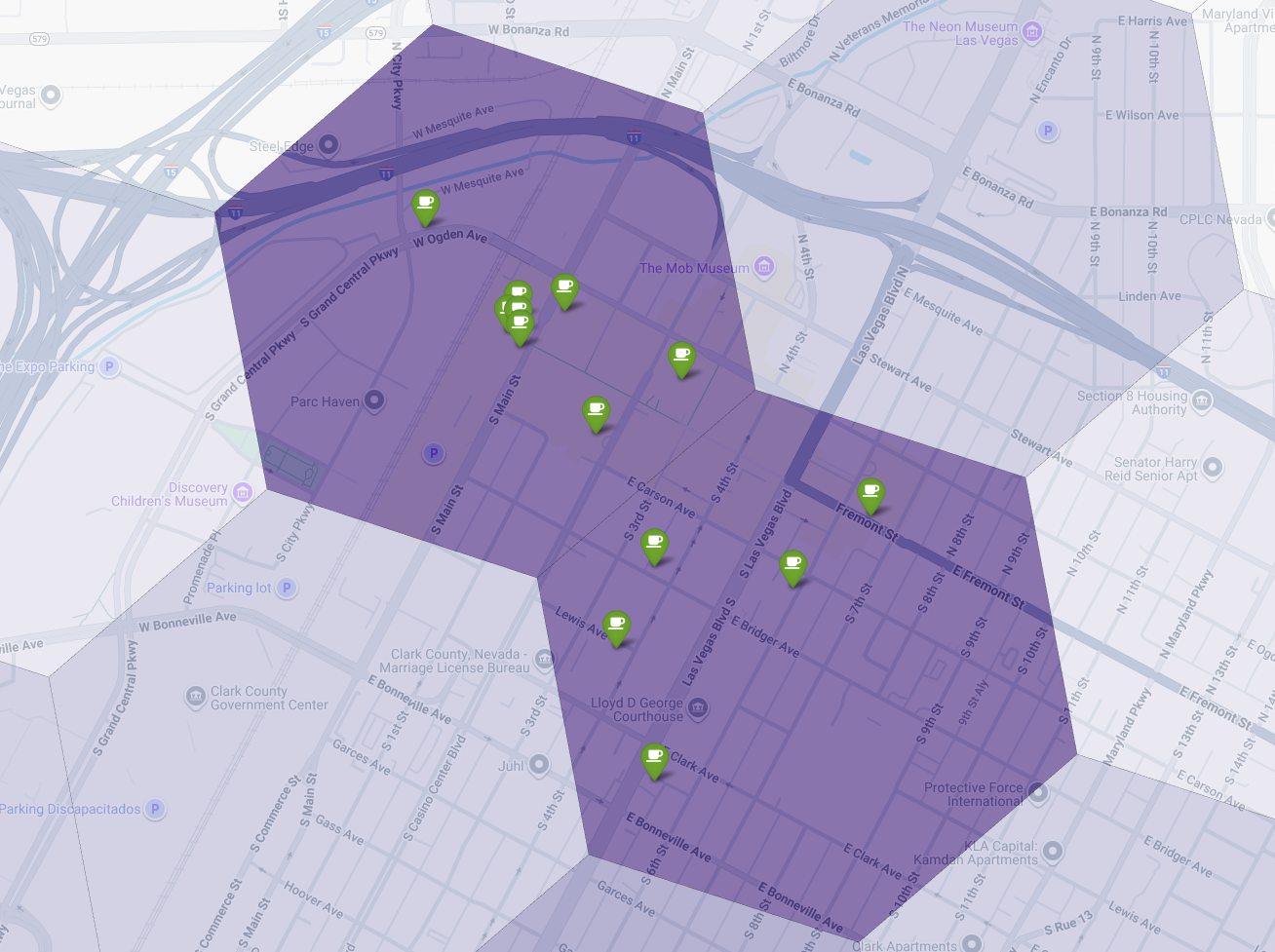
위의 두 셀은 적합성 점수가 높지만 새로운 커피숍의 잠재적 위치가 될 수 있는 명확한 격차가 있습니다.
결론
이 문서에서는 어디로 확장해야 할까?라는 주 전체 질문에서 데이터 기반의 지역 답변으로 이동했습니다. 다양한 데이터 세트를 레이어링하고 맞춤 비즈니스 로직을 적용하면 주요 비즈니스 결정과 관련된 위험을 체계적으로 줄일 수 있습니다. BigQuery의 확장성, Places Insights의 풍부한 정보, Places API의 실시간 세부정보를 결합한 이 워크플로는 위치 인텔리전스를 사용하여 전략적 성장을 도모하려는 모든 조직에 강력한 템플릿을 제공합니다.
다음 단계
- 자체 비즈니스 로직, 타겟 지역, 독점 데이터 세트를 사용하여 이 워크플로를 조정하세요.
- 리뷰 수, 가격 수준, 사용자 평점과 같은 Places Insights 데이터 세트의 다른 데이터 필드를 탐색하여 모델을 더욱 풍부하게 만드세요.
- 이 프로세스를 자동화하여 새 시장을 동적으로 평가하는 데 사용할 수 있는 내부 사이트 선택 대시보드를 만드세요.
문서 자세히 알아보기:
참여자
헨리크 밸브 | DevX 엔지니어