これまでの公平性指標の説明では、公平性に関するトレーニング テストの例には、ユーザー属性の包括的な サブグループです。しかし、そうではないこともあります。
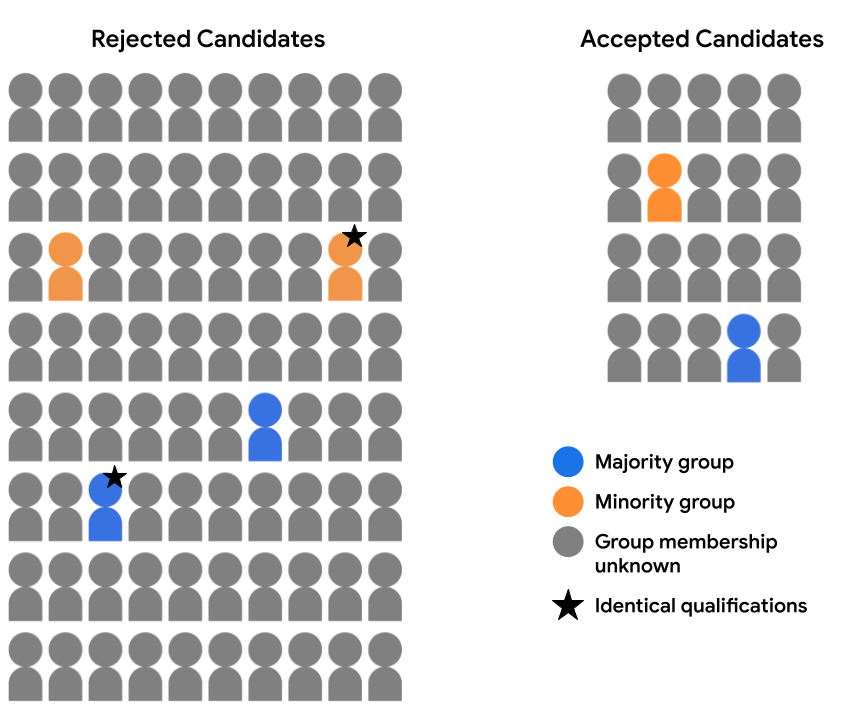
入学に関するデータセットに完全な人口統計データが含まれていないとします。 ユーザー属性グループのメンバーシップはごく一部で記録される たとえば、自分が担当するグループを自己特定することを選択した 属していました。この例では、候補プールを承認された候補 拒否された生徒は次のようになります。
グループでは、1 人の生徒アイコンが色合いが青く、もう 1 つは
灰色がかったオレンジ色です。](https://developers.google.cn/static/machine-learning/crash-course/fairness/images/fairness_metrics_counterfactual_candidate_pool.png?authuser=2&hl=ja)
いずれかのユーザー属性に対するモデルの予測を評価することは不可能 機会の平等または平等(ユーザー属性データがない) 94% でしたただし、単語を含むサンプルの 6% では、 個々の予測のペアを比較することもできます。 (多数派候補者とマイノリティ候補者の比較)を行い、候補者が 公平に扱われます
たとえば、特徴データを完全にレビューし、 2 人(多数派と少数派)の候補者に (下の画像のスターで注釈が付けられたグループ)であることがわかりました。 すべての点で入場資格が同じになります。モデルによって 両方の候補に対して同じ予測を行う(つまり、いずれかが両方とも拒否する) 両方の候補を受け入れる、または両方の候補を受け入れる)は、反事実的条件 公平性を理解する必要があります。反事実的公平性では 機密属性を除き、すべての点で同一のサンプル (ここでは、ユーザー属性グループ メンバーシップ)は、同じモデルになります。 できます。
メリットとデメリット
前述のように 反事実的公平性の主な利点の一つは 予測の公平性を評価するために使用できます。 他の指標は利用できませんデータセットにすべてのデータセットが含まれていなくても、 考慮されている関連グループ属性の特徴値については、 人口統計の同等性または平等性を使用して公平性を評価 学びます。ただし、これらのグループ属性が一部のサービスで使用できる場合は、 同等のサンプルペアを特定することは 実務者は反事実的公平性を使用して を指標として使用し、予測における潜在的なバイアスの有無を確認します。
さらに ユーザー層の平等性や 社会的信用の平等といった グループ全体を評価する際に、影響を与えるバイアスの問題が 個別の予測レベルでモデルを評価します。このレベルは 対事実的公平性を使って評価します。たとえば、入学試験と モデルは、マジョリティ グループとマイノリティ グループから有望な候補者を受け入れます。 グループに属するものの、最も有望な少数派候補者は 最も適格な多数派候補の候補者は却下されましたが 受け入れられます。反事実的公平性分析は 対処できるようにする必要があります
反対に 反事実的公平性の主な欠点は モデル予測におけるバイアスの全体像を提供します。特定し、 いくつかの例のペアでいくつかの不公平を修復するだけでは、不十分な場合があります。 例のサブグループ全体に影響する系統的なバイアスの問題に対処できます。
可能な場合、実務担当者は集計と 公平性分析(人口統計の同等性や平等性などの指標を使用) 反事実的公平性分析を組み合わせて、 修復が必要な潜在的なバイアスの問題に関する幅広い分析情報を提供します。
演習:理解度をチェックする
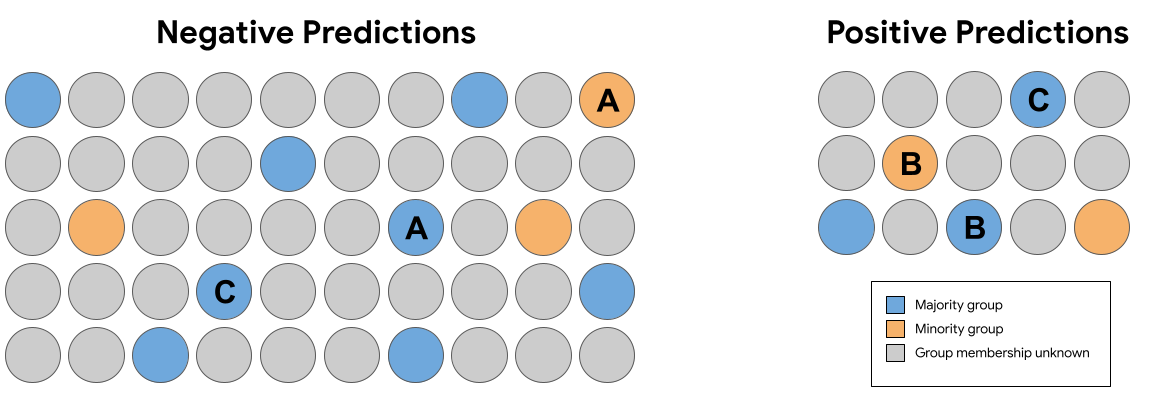 <ph type="x-smartling-placeholder">
<ph type="x-smartling-placeholder">上の図 7 の予測群のうち、 次の同一のペア(グループ メンバーシップを除く) 反事実的公平性に違反する予測を受け取った例
概要
ユーザー属性の同等性 機会の平等 対事実的公平性が示すように、さまざまな数学的定義が 公平性についても学びました。これら 3 つは 公平性を定量化する方法です。公平性の定義の中には、お互いに 非対応 つまり 1 対 1 で 1 対 1 で同時に 適用できます。
では、どうすれば「適切」なユースケースを公平性指標は何でしょうか。必要なこと どのようなコンテキストでデータが使用されるのか そしてお客様の包括的な目標を 示していますたとえば、公平な表現を実現することが目標です。 (この場合は、ユーザー属性の同等性が最適な指標となる可能性があります)か、それとも 機会の平等を実現する(機会の平等が ?
ML の公平性について詳細を確認し、これらの問題を詳しく調べるには、このモジュールの Fairness and Machine Learning: Limitations and Opportunities(Soron Barocas、Moriz Hardt、Arvind Narayanan 著)