新しいテクノロジーである大規模言語モデル(LLM)は、トークンまたはトークン シーケンスを予測します。予測されるトークンは、場合によっては複数の段落に相当することもあります。トークンは単語、サブワード(単語のサブセット)、または 1 文字にすることもできます。LLM は、N グラム言語モデルや再帰型ニューラル ネットワークよりもはるかに優れた予測を行います。その理由は次のとおりです。
- LLM には、再帰モデルよりもはるかに多くのパラメータが含まれています。
- LLM ははるかに多くのコンテキストを収集します。
このセクションでは、LLM の構築に最も成功し、広く使用されているアーキテクチャである Transformer について説明します。
Transformer とは
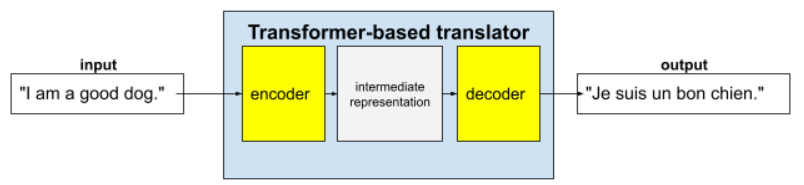
Transformer は、翻訳など、さまざまな言語モデル アプリケーションの最先端のアーキテクチャです。

完全な Transformer はエンコーダとデコーダで構成されます。
たとえば、翻訳ツールでは次のようになります。
- エンコーダは、入力テキスト(英語の文など)を中間表現に変換します。
- デコーダは、その中間表現を出力テキスト(たとえば、同等のフランス語の文)に変換します。
セルフアテンションとは
コンテキストを強化するために、Transformer はセルフ アテンションと呼ばれるコンセプトに大きく依存しています。実際には、入力の各トークンに対して、セルフ アテンションは次の質問をします。
「入力の他のトークンは、このトークンの解釈にどの程度影響しますか?」
「自己注意」の「自己」は入力シーケンスを指します。一部の注意機構では、入力トークンと出力シーケンス(翻訳など)のトークン、または他のシーケンスのトークンとの関係を重み付けします。ただし、セルフ アテンションは入力シーケンス内のトークン間の関係の重要度のみを重み付けします。
説明を簡単にするため、各トークンは単語であり、完全なコンテキストは 1 つの文のみであるとします。次の文を考えてみましょう。
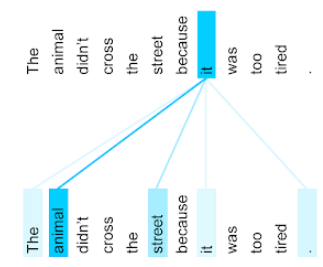
The animal didn't cross the street because it was too tired.
上記の文には 11 個の単語が含まれています。11 個の単語それぞれが、他の 10 個の単語に注目し、それらの単語が自分にとってどれほど重要であるかを考えています。たとえば、この文には代名詞の「it」が含まれています。代名詞は曖昧になりがちです。代名詞の it は通常、直前の名詞または名詞句を指しますが、例文では、it は直前の名詞である動物と通りのどちらを指していますか?
セルフアテンション メカニズムは、代名詞「it」に対する近くの各単語の関連性を判断します。図 3 は結果を示しています。線が青いほど、その単語が代名詞 it にとって重要であることを示しています。つまり、代名詞 it にとって animal は street よりも重要です。
逆に、文の最後の単語が次のように変化したとします。
The animal didn't cross the street because it was too wide.
この文では、セルフ アテンションにより、代名詞「it」に対して「animal」よりも「street」の方が関連性が高いと評価されることが期待されます。
セルフアテンション メカニズムには双方向のものがあります。これは、注目している単語の前と後のトークンの関連性スコアを計算することを意味します。たとえば、図 3 では、it の両側の単語が調べられています。双方向セルフアテンション メカニズムは、注目している単語の両側の単語からコンテキストを収集できます。一方、単方向のセルフアテンション機構は、注目している単語の片側の単語からのみコンテキストを収集できます。双方向自己注意は、シーケンス全体の表現を生成する場合に特に役立ちます。一方、シーケンスをトークンごとに生成するアプリケーションでは、単方向自己注意が必要です。このため、エンコーダは双方向の自己注意を使用し、デコーダは一方向の自己注意を使用します。
マルチヘッド マルチレイヤ セルフアテンションとは
通常、各セルフ アテンション レイヤは複数のセルフ アテンション ヘッドで構成されます。レイヤの出力は、さまざまなヘッドの出力の数学的演算(加重平均やドット積など)です。
各ヘッドのパラメータはランダムな値に初期化されるため、異なるヘッドは、注目されている各単語と近くの単語の間の異なる関係を学習できます。たとえば、前のセクションで説明したセルフ アテンション ヘッドは、代名詞「it」がどの名詞を指しているかを判断することに重点を置いていました。ただし、同じレイヤ内の他のセルフアテンション ヘッドは、各単語と他のすべての単語との文法的な関連性を学習したり、他の相互作用を学習したりする可能性があります。
完全な Transformer モデルでは、複数のセルフアテンション レイヤが相互にスタックされています。前のレイヤの出力が次のレイヤの入力になります。このスタッキングにより、モデルはテキストのより複雑で抽象的な理解を段階的に構築できます。初期のレイヤでは基本的な構文に重点が置かれる一方、より深いレイヤではその情報が統合され、入力全体にわたる感情、コンテキスト、テーマリンクなどのより微妙なコンセプトを把握できます。
Transformer が非常に大きいのはなぜですか?
Transformer には、数千億から数兆のパラメータが含まれています。このコースでは、一般的に、パラメータ数の多いモデルよりもパラメータ数の少ないモデルを構築することが推奨されています。パラメータの数が少ないモデルは、パラメータの数が多いモデルよりも、予測に必要なリソースが少なくなります。ただし、研究によると、パラメータが多い Transformer は、パラメータが少ない Transformer よりも一貫して優れたパフォーマンスを発揮します。
では、LLM はどのようにテキストを生成するのでしょうか?
研究者が LLM をトレーニングして欠落した単語を予測する方法を見て、あまり感心しなかったかもしれません。結局のところ、1 つか 2 つの単語を予測することは、さまざまなテキスト、メール、オーサリング ソフトウェアに組み込まれているオートコンプリート機能と本質的に同じです。LLM が裁定取引に関する文や段落、俳句をどのように生成するのか疑問に思われるかもしれません。
実際、LLM は基本的に、数千ものトークンを自動的に予測(補完)できる予測入力メカニズムです。たとえば、次のような文とマスクされた文があるとします。
My dog, Max, knows how to perform many traditional dog tricks. ___ (masked sentence)
LLM は、マスクされた文の確率を生成できます。たとえば、次のような確率です。
| 確率 | 単語 |
|---|---|
| 3.1% | たとえば、座る、待つ、寝返りをするなどの動作ができます。 |
| 2.9% | たとえば、お座り、待て、ゴロンをします。 |
十分に大規模な LLM は、段落やエッセイ全体の確率を生成できます。LLM に対するユーザーの質問は、「与えられた」文の後に架空のマスクが続くものと考えることができます。次に例を示します。
User's question: What is the easiest trick to teach a dog? LLM's response: ___
LLM は、さまざまな回答の候補の確率を生成します。
別の例として、大量の数学の「文章問題」でトレーニングされた LLM は、高度な数学的推論を行っているように見えます。ただし、これらの LLM は基本的に、文章題のプロンプトを自動補完しているだけです。
LLM のメリット
LLM は、さまざまなターゲット ユーザー向けに、明確でわかりやすいテキストを生成できます。LLM は、明示的にトレーニングされたタスクについて予測を行うことができます。一部の研究者は、LLM は明示的にトレーニングされていない入力についても予測できると主張していますが、他の研究者はこの主張を否定しています。
LLM の問題点
LLM のトレーニングには、次のような多くの問題が伴います。
- 膨大なトレーニング セットを収集する。
- 数か月を要し、膨大なコンピューティング リソースと電力を消費します。
- 並列処理の課題を解決します。
LLM を使用して予測を推論すると、次の問題が発生します。
- LLM はハルシネーションを起こすことが多く、予測に誤りが含まれることがよくあります。
- LLM は、大量のコンピューティング リソースと電力を消費します。通常、大規模なデータセットで LLM をトレーニングすると、推論に必要なリソースの量が減りますが、トレーニング セットが大きくなると、トレーニング リソースが増加します。
- すべての ML モデルと同様に、LLM にもさまざまなバイアスが生じる可能性があります。