비닝 (버케팅이라고도 함)은
특성 추출
서로 다른 숫자 하위 범위를 빈 또는
버킷.
대부분의 경우 비닝은 숫자 데이터를 범주형 데이터로 변환합니다.
예를 들어 다음과 같은 특성을 고려해 보세요.
최저값이 15이고 X
가장 높은 값은 425입니다 비닝을 사용하면 X을
다음과 같은 5개의 구간이 있습니다.
- 구간 1: 15~34
- 구간 2: 35~117
- 구간 3: 118~279
- 구간 4: 280~392
- 구간 5: 393 ~ 425
구간 1은 15~34 범위에 속하므로 X의 모든 값은 15~34입니다.
구간 1에 있습니다. 이러한 구간에서 학습된 모델은
X 값을 17 및 29로 변경합니다.
특성 벡터는 5개의 구간은 다음과 같습니다.
| 구간 번호 | 범위 | 특성 벡터 |
|---|---|---|
| 1 | 15-34 | [1.0, 0.0, 0.0, 0.0, 0.0] |
| 2 | 35-117 | [0.0, 1.0, 0.0, 0.0, 0.0] |
| 3 | 118-279 | [0.0, 0.0, 1.0, 0.0, 0.0] |
| 4 | 280-392 | [0.0, 0.0, 0.0, 1.0, 0.0] |
| 5 | 393-425 | [0.0, 0.0, 0.0, 0.0, 1.0] |
X가 데이터 세트의 단일 열이지만 비닝을 사용하면 모델이
X를 다섯 개의 개별 특성으로 취급합니다. 따라서 모델은
각 구간에
별도의 가중치를 부여합니다
비닝은 확장의 좋은 대안입니다. 또는 클리핑을 선택하면 다음 조건이 충족됩니다.
- 특성과 특성 간의 전반적인 선형 관계입니다. label이 약하거나 존재하지 않습니다.
- 특성 값이 클러스터링되는 경우
비닝은 인코더-디코더 모델의 모델이 이전 예에서는 값 37과 115를 동일하게 취급합니다. 하지만 특성이 선형보다 클럽으로 보이면 비닝을 사용하는 것이 데이터를 나타냅니다.
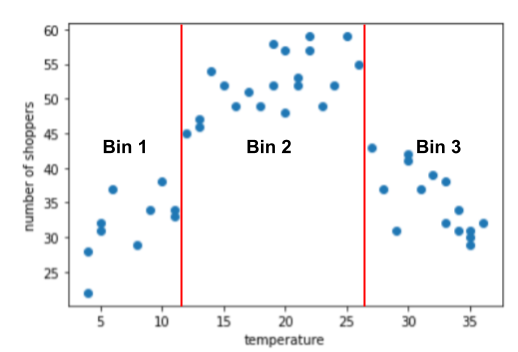
비닝의 예: 쇼핑객 수와 온도 비교
입력 문장의 수를 예측하는 모델을 만든다고 그날 바깥 온도로 쇼핑객을 사로잡을 수 있습니다. 이 플롯은 쇼핑객 수와 온도 비교:

이 그래프는 당연히 2월 초에 쇼핑객 수가 가장 많았을 때 온도가 가장 편안했습니다.
특성을 원시 값으로 나타낼 수 있는데, 특성 벡터에서 35.0이 됩니다. 이게 좋은 생각인가요?
학습 중에 선형 회귀 모델은 각 모델의 단일 가중치를 학습합니다. 기능을 사용할 수 있습니다. 따라서 강도를 단일 특성으로 표현하는 경우 온도가 35.0이면 5배 (또는 평균 기온의 1/5)가 영향을 주지 않습니다. 하지만 플롯은 라벨과 라벨 사이의 선형 관계를 표시할 수 있습니다. 특성값입니다
그래프는 다음 하위 범위에 있는 세 개의 클러스터를 제안합니다.
- 구간 1은 온도 범위 4~11입니다.
- 구간 2는 온도 범위 12~26입니다.
- 구간 3은 온도 범위 27~36입니다.
 </ph>
</ph>
모델은 각 구간에 대해 별도의 가중치를 학습합니다.
세 개 이상의 구간을 만들 수도 있지만 이는 다음과 같은 이유로 인해 좋지 않을 때가 많습니다.
- 모델은 오직 빈과 라벨 사이의 연관성을 학습할 수 해당 상자에는 충분한 예시가 있습니다. 주어진 예에서 3개의 구간은 각각 최소 10개의 예시가 포함되어 학습에 충분할 수 있습니다. 33개의 칸이 따로 있어 빈에는 모델이 학습하기에 충분한 예시가 포함되지 않습니다.
- 각 온도에 대한 별도의 구간을 사용하면 별도의 온도 기능 33개 그러나 일반적으로는 가능한 한 최소화 모델의 특성 수를 측정합니다.
연습문제: 학습 내용 점검하기
다음 도표는 각 0.2도의 주택 가격 중앙값을 신화 속 국가 프리도니아의 위도:

그래픽은 주택 값과 위도 사이의 비선형 패턴을 보여줍니다. 따라서 위도를 부동 소수점 값으로 표현하는 것은 예측을 할 수 있습니다 위도를 버케팅하는 것이 무엇인가요?
- 41.0~41.8
- 42.0~42.6
- 42.8~43.4
- 43.6~44.8
분위수 버케팅
분위수 버케팅은 버케팅 경계를 만들어서 숫자가 정확하거나 거의 같아야 합니다. 분위수 버케팅 대부분 이상점을 숨깁니다.
분위수 버킷팅으로 해결할 수 있는 문제를 설명하기 위해 다음 그림과 같이 간격이 동일한 각 버킷이 10개 버킷 중 정확히 10,000달러에 해당하는 범위를 나타냅니다. 0에서 10,000 사이의 버킷에는 수십 개의 예시가 포함된 것을 볼 수 있습니다. 50,000에서 60,000까지의 버킷에는 5개의 예시만 포함되어 있습니다. 결과적으로 이 모델은 0~10, 000개의 범위에서 학습하기에 충분한 예시를 갖고 있으며, 50,000~60,000개의 버킷에 대해 학습할 만큼 예시가 충분하지 않습니다

반대로 다음 그림은 분위수 버케팅을 사용하여 자동차 가격을 나눕니다. 각 버킷에 거의 같은 수의 예가 있는 구간으로 나눕니다. 일부 구간은 좁은 가격 범위를 포함하는 반면 다른 빈은 매우 광범위한 가격 범위를 포괄합니다
