Kết hợp (còn gọi là phân giỏ) là một
kỹ thuật trích xuất tính năng
kỹ thuật nhóm các nhóm số con khác nhau vào các thùng hoặc
bộ chứa.
Trong nhiều trường hợp, tính năng kết hợp sẽ biến dữ liệu số thành dữ liệu phân loại.
Ví dụ: hãy cân nhắc một tính năng
có tên X có giá trị thấp nhất là 15 và
giá trị cao nhất là 425. Bằng cách sử dụng tính năng kết hợp, bạn có thể biểu thị X bằng
năm thùng sau:
- Thùng 1: từ 15 đến 34
- Thùng 2: 35 đến 117
- Thùng 3: 118 đến 279
- Thùng 4: 280 đến 392
- Thùng 5: 393 đến 425
Thùng 1 kéo dài trong khoảng từ 15 đến 34, vì vậy, mọi giá trị của X từ 15 đến 34
kết thúc vào Thùng 1. Một mô hình được huấn luyện trên những thùng rác này sẽ phản ứng không khác gì
vào các giá trị X là 17 và 29 vì cả hai giá trị đều nằm trong Thùng 1.
Vectơ tính năng biểu thị 5 thùng như sau:
| Số thùng | Phạm vi | Vectơ đối tượng |
|---|---|---|
| 1 | 15-34 | [1.0, 0.0, 0.0, 0.0, 0.0] |
| 2 | 35-117 | [0,0, 1,0, 0,0, 0,0, 0,0] |
| 3 | 118-279 | [0,0, 0,0, 1,0, 0,0, 0,0] |
| 4 | 280-392 | [0,0, 0,0, 0,0, 1,0, 0,0] |
| 5 | 393-425 | [0,0, 0,0, 0,0, 0,0, 1,0] |
Mặc dù X là một cột duy nhất trong tập dữ liệu, nhưng việc gộp nhóm sẽ khiến mô hình
để coi X là 5 tính năng riêng biệt. Do đó, mô hình này sẽ học
trọng lượng riêng cho mỗi thùng.
Kết hợp chặt chẽ là một giải pháp thay thế phù hợp cho việc điều chỉnh theo tỷ lệ hoặc cắt đoạn khi một trong hai các điều kiện sau:
- Mối quan hệ tuyến tính tổng thể giữa tính năng và nhãn yếu hoặc không tồn tại.
- Khi các giá trị tính năng được nhóm lại.
Việc kết hợp có thể gây khác thường vì mô hình trong ví dụ trước xử lý các giá trị 37 và 115 giống nhau. Nhưng khi một đối tượng có vẻ nóng hổi hơn so với đường thẳng, kết hợp là một cách tốt hơn nhiều để biểu thị dữ liệu.
Ví dụ về kết hợp: số lượng người mua sắm so với nhiệt độ
Giả sử bạn đang tạo một mô hình dự đoán số lượng người mua sắm theo nhiệt độ bên ngoài vào ngày đó. Sau đây là cốt truyện của so với số lượng người mua sắm:

Không có gì ngạc nhiên khi cốt truyện này cho thấy rằng số lượng người mua sắm đạt mức cao nhất khi nhiệt độ dễ chịu nhất.
Bạn có thể biểu thị đối tượng dưới dạng giá trị thô: nhiệt độ 35,0 ở tập dữ liệu sẽ là 35.0 trong vectơ đối tượng. Đó có phải là ý tưởng hay nhất không?
Trong quá trình huấn luyện, mô hình hồi quy tuyến tính sẽ học một trọng số duy nhất cho mỗi của chúng tôi. Do đó, nếu nhiệt độ được biểu thị dưới dạng một đối tượng đơn lẻ, thì ở nhiệt độ 35,0 sẽ có mức ảnh hưởng gấp 5 lần (hoặc 1/5 ảnh hưởng lớn nhất) trong thông tin dự đoán khi nhiệt độ là 7,0. Tuy nhiên, cốt truyện không thực sự chỉ ra bất kỳ mối quan hệ tuyến tính nào giữa nhãn và giá trị tính năng.
Biểu đồ đề xuất 3 cụm trong các dải con sau:
- Thùng 1 là khoảng nhiệt độ 4-11.
- Thùng 2 là khoảng nhiệt độ 12-26.
- Thùng 3 là khoảng nhiệt độ 27-36.
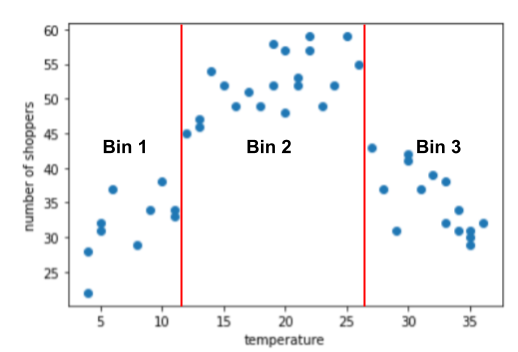
Mô hình này sẽ học các trọng số riêng biệt cho từng thùng.
Mặc dù có thể tạo nhiều hơn ba thùng, thậm chí là một thùng riêng cho mỗi chỉ số nhiệt độ, đây thường là một ý tưởng không hay vì những lý do sau:
- Mô hình chỉ có thể học mối liên kết giữa một thùng và nhãn nếu có có đủ ví dụ trong thùng đó. Trong ví dụ đã cho, mỗi thùng trong số 3 thùng chứa ít nhất 10 ví dụ, có thể đủ để huấn luyện. Với 33 thùng riêng biệt, sẽ không có thùng nào chứa đủ ví dụ để mô hình huấn luyện.
- Một thùng riêng cho từng nhiệt độ sẽ dẫn đến 33 tính năng điều chỉnh nhiệt độ riêng biệt. Tuy nhiên, thông thường, bạn nên giảm thiểu số lượng tính năng trong một mô hình.
Bài tập: Kiểm tra kiến thức
Biểu đồ sau đây thể hiện giá nhà trung bình theo mỗi 0,2 độ vĩ độ của quốc gia Freedonia trong thần thoại:

Hình ảnh cho thấy một mẫu phi tuyến tính giữa giá trị nhà và vĩ độ, vì vậy, việc biểu diễn vĩ độ dưới dạng giá trị dấu phẩy động của nó sẽ không thể giúp ích cho một mô hình đưa ra các dự đoán khả thi. Vĩ độ phân tán có lẽ sẽ tốt hơn ý tưởng?
- 41,0 đến 41,8
- 42,0 đến 42,6
- 42,8 đến 43,4
- 43,6 đến 44,8
Nhóm phân vị
Phân giỏ theo nhóm tạo ra các ranh giới phân giỏ sao cho số ví dụ trong mỗi nhóm chính xác hoặc gần bằng nhau. Phân giỏ phân vị hầu như che giấu những điểm ngoại lai.
Để minh hoạ vấn đề giải quyết bộ chứa phân vị, hãy xem xét các nhóm có cách đều nhau như minh hoạ trong hình sau, trong đó mỗi nhóm trên 10 thùng tương ứng với chính xác 10.000 đô la. Lưu ý rằng nhóm từ 0 đến 10.000 chứa hàng tá ví dụ nhưng nhóm từ 50.000 đến 60.000 chỉ chứa 5 ví dụ. Do đó, mô hình này có đủ số ví dụ để huấn luyện từ 0 đến 10.000 nhưng không đủ ví dụ để huấn luyện cho nhóm 50.000 đến 60.000.

Ngược lại, hình sau đây sử dụng bộ chứa số phân vị để chia giá ô tô vào các thùng với cùng số lượng ví dụ trong mỗi nhóm. Lưu ý rằng một số mức giá có giới hạn giá thấp trong khi các mức giá khác bao gồm khoảng giá rất rộng.
