Questa sezione esplora le seguenti tre domande:
- Qual è la differenza tra dataset bilanciati per classe e dataset sbilanciati per classe?
- Perché l'addestramento di un set di dati sbilanciato è difficile?
- Come si possono superare i problemi di addestramento di set di dati sbilanciati?
Set di dati bilanciati per classe e set di dati sbilanciati per classe
Prendi in considerazione un set di dati contenente un'etichetta categorica il cui valore è la classe positiva o la classe negativa. In un set di dati bilanciato per classe, il numero di classi positive e classi negative è circa uguale. Ad esempio, un set di dati contenente 235 classi positive e 247 classi negative è un set di dati bilanciato.
In un set di dati con classi sbilanciate, un'etichetta è notevolmente più comune dell'altra. Nel mondo reale, i set di dati con classi sbilanciate sono molto più comuni di quelli con classi bilanciate. Ad esempio, in un set di dati di transazioni con carta di credito, gli acquisti fraudolenti potrebbero costituire meno dello 0,1% degli esempi. Analogamente, in un set di dati per la diagnosi medica, il numero di pazienti con un virus raro potrebbe essere inferiore allo 0,01% del totale degli esempi. In un set di dati con classi sbilanciate:
- L'etichetta più comune è chiamata classe maggioritaria.
- L'etichetta meno comune è chiamata classe di minoranza.
La difficoltà di addestrare set di dati con forte sbilanciamento di classe
L'addestramento mira a creare un modello che distingua correttamente la classe positiva da quella negativa. A questo scopo, i batch devono avere un numero sufficiente di classi positive e negative. Questo non è un problema quando l'addestramento viene eseguito su un set di dati con uno sbilanciamento di classe moderato, poiché anche piccoli batch contengono in genere esempi sufficienti sia della classe positiva che di quella negativa. Tuttavia, un set di dati con un forte sbilanciamento di classe potrebbe non contenere esempi di classe minoritaria sufficienti per un addestramento adeguato.
Ad esempio, considera il set di dati con classi sbilanciate illustrato nella Figura 6 in cui:
- 200 etichette appartengono alla classe maggioritaria.
- 2 etichette appartengono alla classe di minoranza.
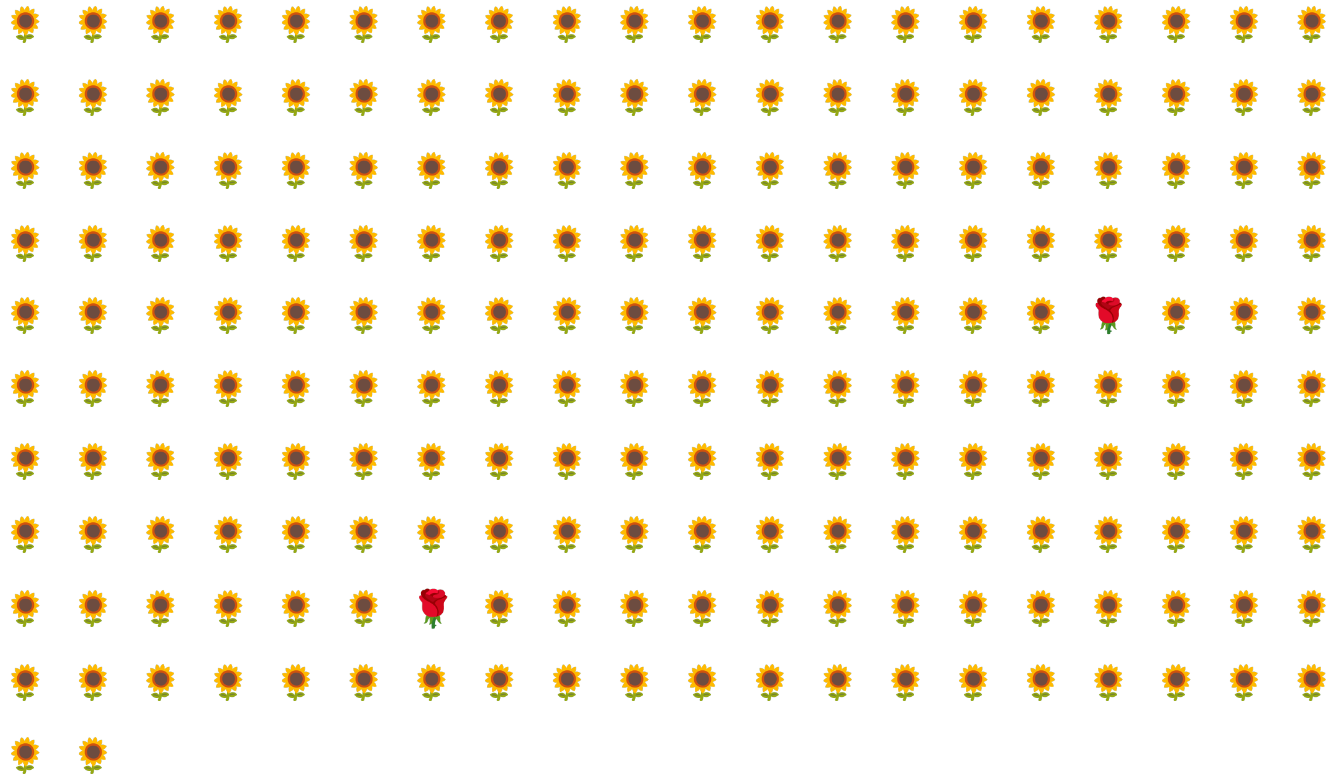
Se la dimensione del batch è 20, la maggior parte dei batch non conterrà esempi della classe minoritaria. Se la dimensione del batch è 100, ogni batch conterrà in media un solo esempio di classe minoritaria, il che è insufficiente per un addestramento adeguato. Anche una dimensione del batch molto più grande produrrà una proporzione così sbilanciata che il modello potrebbe non essere addestrato correttamente.
Addestramento di un set di dati con classi sbilanciate
Durante l'addestramento, un modello deve apprendere due cose:
- L'aspetto di ogni classe, ovvero quali valori delle caratteristiche corrispondono a quale classe.
- La frequenza di ogni classe, ovvero la distribuzione relativa delle classi.
L'addestramento standard unisce questi due obiettivi. Al contrario, la seguente tecnica in due passaggi chiamata sottocampionamento e ponderazione della classe maggioritaria separa questi due obiettivi, consentendo al modello di raggiungere entrambi.
Passaggio 1: esegui il sottocampionamento della classe maggioritaria
Sottocampionamento indica l'addestramento su una percentuale sproporzionatamente bassa di esempi della classe maggioritaria. ovvero forzi artificialmente un set di dati con classi sbilanciate a diventare un po' più bilanciato omettendo molti degli esempi della classe maggioritaria dall'addestramento. Il sottocampionamento aumenta notevolmente la probabilità che ogni batch contenga un numero sufficiente di esempi della classe minoritaria per addestrare il modello in modo corretto ed efficiente.
Ad esempio, il set di dati sbilanciato per classe mostrato nella Figura 6 è costituito da esempi di classe di maggioranza al 99% e di classe di minoranza all'1%. Il sottocampionamento della classe maggioritaria di un fattore 25 crea artificialmente un set di addestramento più bilanciato (80% di classe maggioritaria e 20% di classe minoritaria), come suggerito nella Figura 7:

Passaggio 2: aumenta il peso della classe sottocampionata
Il sottocampionamento introduce un bias di previsione mostrando al modello un mondo artificiale in cui le classi sono più bilanciate rispetto al mondo reale. Per correggere questo bias, devi "aumentare" le classi maggioritarie del fattore in base al quale hai eseguito il sottocampionamento. L'assegnazione di un peso maggiore significa trattare la perdita su un esempio di classe maggioritaria in modo più severo rispetto alla perdita su un esempio di classe minoritaria.
Ad esempio, abbiamo sottocampionato la classe maggioritaria di un fattore pari a 25, quindi dobbiamo aumentare il peso della classe maggioritaria di un fattore pari a 25. ovvero, quando il modello prevede erroneamente la classe maggioritaria, considera la perdita come se fossero 25 errori (moltiplica la perdita normale per 25).

Quanto devi sottocampionare e sovrappesare per ribilanciare il set di dati? Per determinare la risposta, devi sperimentare diversi fattori di sottocampionamento e ponderazione, proprio come faresti con altri iperparametri.
Vantaggi di questa tecnica
Il sottocampionamento e l'assegnazione di un peso maggiore alla classe maggioritaria offrono i seguenti vantaggi:
- Modello migliore:il modello risultante "conosce" entrambi i seguenti elementi:
- La connessione tra caratteristiche ed etichette
- La vera distribuzione delle classi
- Convergenza più rapida: durante l'addestramento, il modello vede più spesso la classe minoritaria, il che lo aiuta a convergere più rapidamente.