Nadmiernie dopasowany oznacza, że model tak dobrze pasuje (zapamiętuje) do zbioru danych treningowych, że nie jest w stanie trafnie prognozować na podstawie nowych danych. Nadmiernie dopasowany model jest podobny do wynalazku, który dobrze sprawdza się w laboratorium, ale jest bezużyteczny w rzeczywistym świecie.
Na rysunku 11 wyobraź sobie, że każdy kształt geometryczny reprezentuje położenie drzewa w kwadratowym lesie. Niebieskie diamenty oznaczają zdrowe drzewa, a pomarańczowe koła – chore.

Wyobraź sobie dowolne kształty – linie, krzywe, owalne kształty...cokolwiek – aby odróżnić zdrowe drzewa od chorych. Następnie rozwiń następny wiersz, aby sprawdzić jedną z możliwych separacji.
Rozwiń, aby zobaczyć jedno z możliwych rozwiązań (ryc. 12).

Złożone kształty pokazane na rysunku 12 zostały pogrupowane według wszystkich drzew z wyjątkiem dwóch. Jeśli potraktujemy kształty jako model, to jest to fantastyczny model.
A może jednak? Prawdziwie doskonały model skutecznie przypisuje nowe przykłady do kategorii. Ilustracja 13 pokazuje, co się dzieje, gdy ten sam model prognozuje na podstawie nowych przykładów ze zbioru testowego:

Złożony model na rysunku 12 dobrze poradził sobie ze zbiorem treningowym, ale nie z zestawem testowym. To typowy przypadek nadmiernego dopasowania modelu do danych w zbiorze treningowym.
Dopasowanie, nadmierne dopasowanie i niedopasowanie
Model musi dobrze prognozować na podstawie nowych danych. Oznacza to, że chcesz utworzyć model, który „pasuje” do nowych danych.
Jak widzisz, model nadmiernie dopasowany świetnie prognozuje na zbiorze treningowym, ale słabo na nowych danych. Niedopasowany model nie jest w stanie nawet dobrze prognozować na podstawie danych treningowych. Jeśli model nadmiernie dopasowany jest jak produkt, który dobrze sprawdza się w laboratorium, ale słabo w rzeczywistych warunkach, to model niedopasowany jest jak produkt, który nie sprawdza się nawet w laboratorium.

Uogólnienie jest przeciwieństwem nadmiernego dopasowania. Oznacza to, że model, który dobrze się generalizuje, dobrze prognozuje na podstawie nowych danych. Twoim celem jest utworzenie modelu, który dobrze się generalizuje na nowych danych.
Wykrywanie nadmiernego dopasowania
Te krzywe pomogą Ci wykryć nadmierne dopasowanie:
- krzywe utraty
- krzywe uogólniające
Krzywa strat przedstawia straty modelu w zależności od liczby iteracji treningu. Wykres, który pokazuje co najmniej 2 krzywe strat, nazywa się krzywą generalizacji. Na poniższej krzywej generalizacji widać 2 krzywe strat:
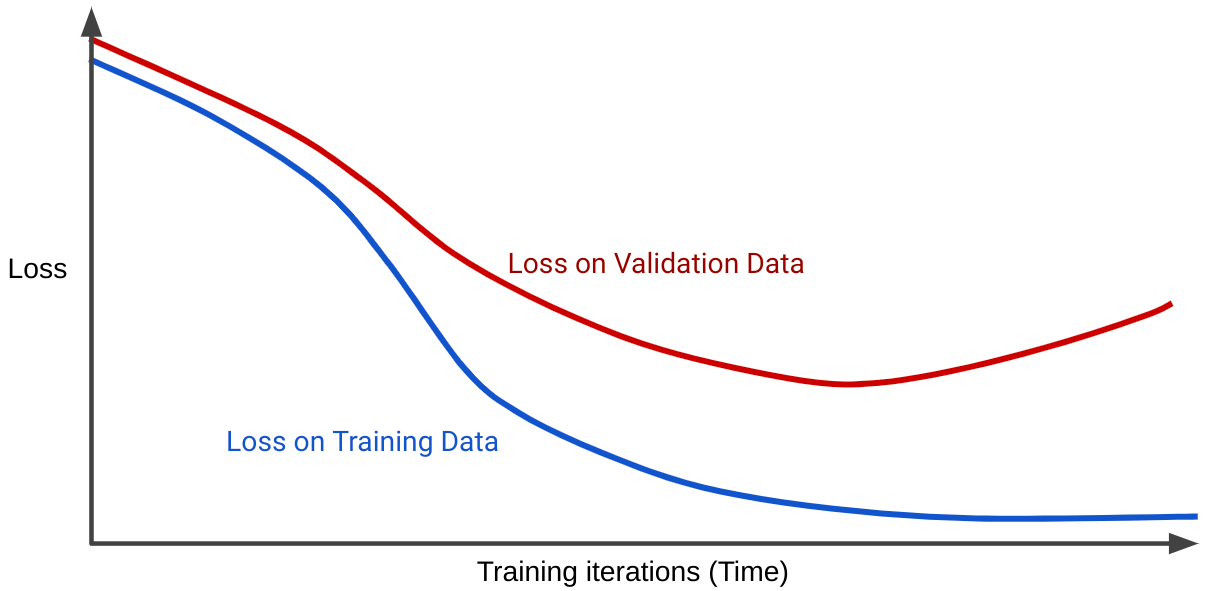
Zwróć uwagę, że obie krzywe strat początkowo zachowują się podobnie, a potem się rozchodzą. Oznacza to, że po określonej liczbie iteracji straty maleją lub pozostają na stałym poziomie (zbiegają się) w przypadku zbioru treningowego, ale rosną w przypadku zbioru walidacyjnego. To sugeruje nadmierne dopasowanie.
Natomiast krzywa uogólniania dla dobrze dopasowanego modelu zawiera 2 krzywe strat o podobnym kształcie.
Co powoduje nadmierne dopasowanie?
Ogólnie rzecz biorąc, przetrenowanie jest spowodowane jednym lub większą liczbą tych problemów:
- Zbiór treningowy nie odzwierciedla wystarczająco dobrze danych rzeczywistych (ani zbioru walidacyjnego, ani zbioru testowego).
- Model jest zbyt złożony.
Warunki uogólniania
Model trenuje na zbiorze treningowym, ale prawdziwy test jego wartości polega na sprawdzeniu, jak dobrze prognozuje on nowe przykłady, zwłaszcza na podstawie rzeczywistych danych. Podczas tworzenia modelu zbiór testowy pełni funkcję zastępczą dla danych rzeczywistych. Trenowanie modelu, który dobrze generalizuje, wymaga spełnienia tych warunków dotyczących zbioru danych:
- Przykłady muszą być rozłożone niezależnie i identycznie, co jest wymyślnym sposobem na powiedzenie, że przykłady nie mogą na siebie wpływać.
- Zbiór danych jest statyczny, co oznacza, że nie zmienia się znacząco w czasie.
- Partycje zbioru danych mają ten sam rozkład. Oznacza to, że przykłady w zbiorze treningowym są statystycznie podobne do przykładów w zbiorze walidacyjnym, zbiorze testowym i danych rzeczywistych.
Poznaj te warunki, wykonując podane niżej ćwiczenia.
Ćwiczenia: sprawdź swoją wiedzę

Wyzwanie
Tworzysz model, który przewiduje idealną datę zakupu biletu na pociąg dla pasażerów na danej trasie. Model może na przykład zalecać użytkownikom zakup biletu 8 lipca na pociąg, który odjeżdża 23 lipca. Cena jest aktualizowana co godzinę na podstawie różnych czynników, ale przede wszystkim bieżącej liczby dostępnych miejsc. Czyli:
- Jeśli jest dużo wolnych miejsc, ceny biletów są zwykle niskie.
- Jeśli jest niewiele miejsc, ceny biletów są zwykle wysokie.
Odpowiedź: model rzeczywistego świata ma problemy z pętlą sprzężenia zwrotnego.
Załóżmy na przykład, że model zaleca użytkownikom kupowanie biletów 8 lipca. Niektórzy pasażerowie, którzy korzystają z rekomendacji modelu, kupują bilety 8 lipca o 8:30 rano. O godzinie 9:00 przewoźnik podnosi ceny, ponieważ jest mniej dostępnych miejsc. Pasażerowie korzystający z rekomendacji modelu mają zmienione ceny. Wieczorem ceny biletów mogą być znacznie wyższe niż rano.