
本文档将讨论如何使用 JSON 定义代码块中的输入、字段(包括标签)和连接。如果您不熟悉这些术语,请先参阅块的结构,然后再继续。
您还可以在 JavaScript 中定义输入、字段和连接。
概览
在 JSON 中,您可以使用一个或多个消息字符串(message0、message1 等)及其对应的实参数组(args0、args1 等)来描述块的结构。消息字符串包含文本(会转换为标签)和插值令牌(%1、%2 等),用于标记连接和非标签字段的位置。实参数组描述了如何处理插值令牌。
例如,以下代码块:

由以下 JSON 定义:
JSON
{
"message0": "set %1 to %2",
"args0": [
{
"type": "field_variable",
"name": "VAR",
"variable": "item",
"variableTypes": [""]
},
{
"type": "input_value",
"name": "VALUE"
}
]
}
第一个插值令牌 (%1) 表示一个变量字段 (type: "field_variable")。它由 args0 数组中的第一个对象描述。第二个令牌 (%2) 表示值输入 (type: "input_value") 末尾的输入连接。它由 args0 数组中的第二个对象描述。
消息和输入
当插值令牌标记连接时,实际上是标记包含连接的输入的结尾。这是因为值和语句输入中的连接是在输入结束时呈现的。输入包含上一个输入之后到当前 token 之间的所有字段(包括标签)。以下部分显示了示例消息以及根据这些消息创建的输入。
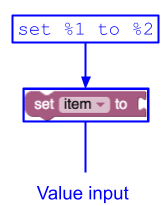
示例 1
JSON
{
"message0": "set %1 to %2",
"args0": [
{"type": "field_variable", ...} // token %1
{"type": "input_value", ...} // token %2
],
}
这会创建一个包含三个字段的单值输入:一个标签 ("set")、一个变量字段和另一个标签 ("to")。
示例 2
JSON
{
"message0": "%1 + %2",
"args0": [
{"type": "input_value", ...} // token %1
{"type": "input_value", ...} // token %2
],
}
这会创建两个值输入。第一个没有字段,第二个有一个字段 ("+")。
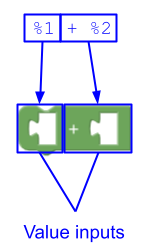
示例 3
JSON
{
"message0": "%1 + %2 %3",
"args0": [
{"type": "input_value", ...} // token %1
{"type": "input_end_row", ...} // token %2
{"type": "input_value", ...} // token %3
],
}
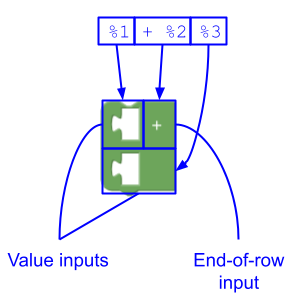
这会创建:
- 没有字段的值输入,
- 带有标签字段 (
"+") 的行尾输入,这会导致后续的值输入呈现在新行中,以及 - 没有字段的值输入。
消息末尾的虚拟输入
如果您的 message 字符串以文本或字段结尾,则无需为包含它们的虚拟输入添加插值令牌,Blockly 会为您添加。例如,您不应像这样定义 lists_isEmpty 块:
JSON
{
"message0": "%1 is empty %2",
"args0": [
{"type": "input_value", ...} // token %1
{"type": "input_dummy", ...} // token %2
],
}
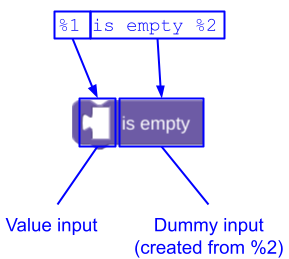
您可以让 Blockly 添加虚拟输入并按如下方式定义它:
JSON
{
"message0": "%1 is empty",
"args0": [
{"type": "input_value", ...} // token %1
],
}
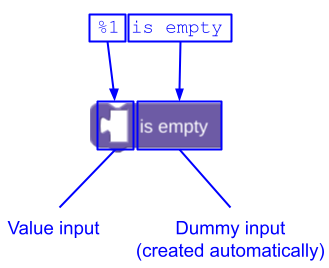
自动添加尾随虚拟输入可让翻译人员更改 message,而无需修改描述插值令牌的实参。如需了解详情,请参阅插值令牌顺序。
implicitAlign
在极少数情况下,自动创建的尾随虚拟输入需要与 "RIGHT" 或 "CENTRE" 对齐。如果未指定,则默认值为 "LEFT"。
在下面的示例中,message0 为 "send email to %1 subject %2 secure %3",Blockly 会自动为第三行添加一个虚拟输入。将 implicitAlign0 设置为 "RIGHT" 会强制此行靠右对齐。

implicitAlign 适用于未在 JSON 块定义中明确定义的所有输入,包括替换换行符 ('\n') 的行尾输入。此外,还有一个已弃用的属性 lastDummyAlign0,其行为与 implicitAlign0 相同。
为 RTL(阿拉伯语和希伯来语)设计块时,左侧和右侧会反转。因此,"RIGHT" 会将字段靠左对齐。
多条消息
有些块自然而然地分为两个或更多个单独的部分。假设有以下包含两行的重复块:

如果使用一条消息来描述此块,则 message0 属性将为 "repeat %1 times %2 do %3",其中 %2 表示行尾输入。对于翻译人员来说,此字符串很难处理,因为很难解释 %2 替换的含义。在某些语言中,甚至可能不需要 %2 行尾输入。并且可能存在多个块希望共享第二行的文本。更好的方法是使用多个 message 和 args 属性:
JSON
{
"message0": "repeat %1 times",
"args0": [
{"type": "input_value", ...} // token %1 in message0
],
"message1": "do %1",
"args1": [
{"type": "input_statement", ...} // token %1 in message1
],
}
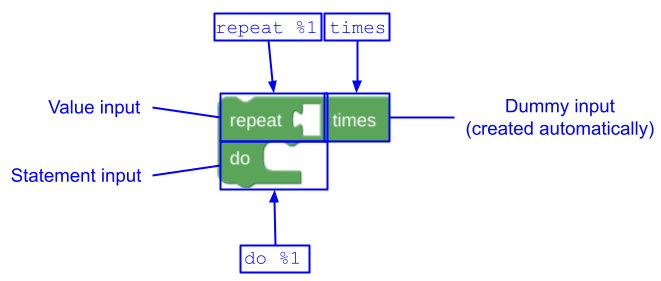
JSON 格式中可以定义任意数量的 message、args 和 implicitAlign 属性,从 0 开始,按顺序递增。请注意,Block Factory 无法将消息拆分为多个部分,但手动拆分非常简单。
插值令牌顺序
在本地化块时,您可能需要更改消息中插值令牌的顺序。对于字序与英语不同的语言,这一点尤为重要。例如,我们从由消息 "set %1 to %2" 定义的块开始:
现在,假设有一种语言,其中 "set %1 to %2" 需要反转才能变成 "put %2 in %1"。更改消息(包括插值令牌的顺序)并保持实参数组不变,会产生以下代码块:

Blockly 自动更改了字段的顺序,创建了虚拟输入,并从外部输入切换到了内部输入。
能够更改消息中插值令牌的顺序,从而简化本地化流程。如需了解详情,请参阅 JSON 消息插值。
文字处理
插值令牌两侧的文本会进行空格修剪。
使用字符 % 的文本(例如,在表示百分比时)应使用 %%,以免被解读为插值令牌。
Blockly 还会自动将消息字符串中的任何换行符 (\n) 替换为行尾输入。
JSON
{
"message0": "set %1\nto %2",
"args0": [
{"type": "field_variable", ...}, // token %1
{"type": "input_value", ...}, // token %2
]
}
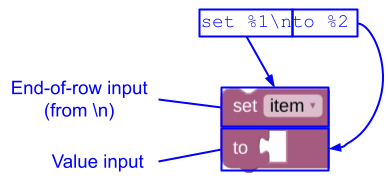
实参数组
每个消息字符串都与一个相同数量的 args 数组配对。例如,message0 与 args0 搭配使用。插值令牌(%1、%2 等)是指 args 数组的项,并且必须与 args0 数组完全匹配:不得重复,不得遗漏。令牌编号是指实参数组中项的顺序;它们不一定按顺序出现在消息字符串中。
实参数组中的每个对象都有一个 type 字符串。其余参数因类型而异:
您还可以定义自己的自定义字段和自定义输入,并将它们作为实参传递。
替代字段
每个对象还可以包含 alt 字段。如果 Blockly 无法识别对象的 type,则会改用 alt 对象。例如,如果向 Blockly 添加了一个名为 field_time 的新字段,使用此字段的块可以使用 alt 为旧版 Blockly 定义 field_input 回退:
JSON
{
"message0": "sound alarm at %1",
"args0": [
{
"type": "field_time",
"name": "TEMPO",
"hour": 9,
"minutes": 0,
"alt":
{
"type": "field_input",
"name": "TEMPOTEXT",
"text": "9:00"
}
}
]
}
alt 对象可以有自己的 alt 对象,从而实现链式调用。最终,如果 Blockly 无法在 args0 数组中创建对象(在尝试任何 alt 对象之后),则会直接跳过该对象。