
Оптимизация производительности начинается с определения ключевых показателей, обычно связанных с задержкой и пропускной способностью. Добавление мониторинга для сбора и отслеживания этих показателей выявляет слабые места приложения. С помощью метрик можно провести оптимизацию для улучшения показателей производительности.
Кроме того, многие инструменты мониторинга позволяют настраивать оповещения для ваших показателей, чтобы вы получали уведомление при достижении определенного порога. Например, вы можете настроить оповещение, которое будет уведомлять вас, когда процент неудачных запросов увеличивается более чем на x % от нормального уровня. Инструменты мониторинга могут помочь вам определить, как выглядит нормальная производительность, а также выявить необычные пики задержки, количества ошибок и других ключевых показателей. Возможность отслеживать эти показатели особенно важна в критические для бизнеса сроки или после того, как новый код был запущен в производство.
Определение показателей задержки
Убедитесь, что ваш пользовательский интерфейс максимально отзывчив, учитывая, что пользователи ожидают от мобильных приложений еще более высоких стандартов. Задержку также следует измерять и отслеживать для серверных служб, особенно потому, что она может привести к проблемам с пропускной способностью, если ее не контролировать.
Рекомендуемые показатели для отслеживания включают следующее:
- Продолжительность запроса
- Длительность запроса на уровне детализации подсистемы (например, вызовы API)
- Продолжительность работы
Определение показателей пропускной способности
Пропускная способность — это мера общего количества запросов, обслуженных за определенный период времени. На пропускную способность может влиять задержка подсистем, поэтому вам может потребоваться оптимизировать задержку, чтобы улучшить пропускную способность.
Вот некоторые рекомендуемые показатели для отслеживания:
- Запросов в секунду
- Размер данных, передаваемых в секунду
- Количество операций ввода-вывода в секунду
- Использование ресурсов, например использование ЦП или памяти.
- Размер очереди обработки, например pub/sub или количество потоков.
Не только среднее
Распространенной ошибкой при измерении производительности является рассмотрение только среднего (усредненного) случая. Хотя это полезно, оно не дает понимания распределения задержки. Лучше всего отслеживать процентили производительности, например 50-й/75-й/90-й/99-й процентиль для метрики.
Как правило, оптимизацию можно выполнить в два этапа. Во-первых, оптимизируйте задержку до 90-го процентиля. Затем рассмотрим 99-й процентиль, также известный как хвостовая задержка: небольшая часть запросов, выполнение которых занимает гораздо больше времени.
Мониторинг на стороне сервера для получения подробных результатов
Для отслеживания показателей обычно предпочтительнее профилирование на стороне сервера. Серверную часть обычно гораздо проще инструментировать, она обеспечивает доступ к более детальным данным и менее подвержена помехам из-за проблем с подключением.
Мониторинг браузера для сквозной видимости
Профилирование браузера может предоставить дополнительную информацию об опыте конечного пользователя. Он может показать, какие страницы имеют медленные запросы, что затем можно сопоставить с мониторингом на стороне сервера для дальнейшего анализа.
Google Analytics обеспечивает готовый мониторинг времени загрузки страниц в отчете о времени загрузки страниц . Это обеспечивает несколько полезных представлений для понимания взаимодействия пользователей с вашим сайтом, в частности:
- Время загрузки страницы
- Перенаправить время загрузки
- Время ответа сервера
Мониторинг в облаке
Существует множество инструментов, которые можно использовать для сбора и мониторинга показателей производительности вашего приложения. Например, вы можете использовать Google Cloud Logging для регистрации показателей производительности в вашем проекте Google Cloud , а затем настроить информационные панели в Google Cloud Monitoring для мониторинга и сегментации зарегистрированных показателей.
Ознакомьтесь с руководством по ведению журнала, где приведен пример ведения журнала в Google Cloud Logging из пользовательского перехватчика в клиентской библиотеке Python. Имея эти данные, доступные в Google Cloud, вы можете создавать метрики на основе зарегистрированных данных, чтобы обеспечить видимость вашего приложения с помощью Google Cloud Monitoring. Следуйте руководству по пользовательским метрикам на основе журналов, чтобы создавать метрики с использованием журналов, отправленных в Google Cloud Logging.
Альтернативно вы можете использовать клиентские библиотеки мониторинга, чтобы определять метрики в своем коде и отправлять их непосредственно в мониторинг, отдельно от журналов.
Пример показателей на основе журнала
Предположим, вы хотите отслеживать значение is_fault , чтобы лучше понимать частоту ошибок в вашем приложении. Вы можете извлечь значение is_fault из журналов в новую метрику счетчика ErrorCount .
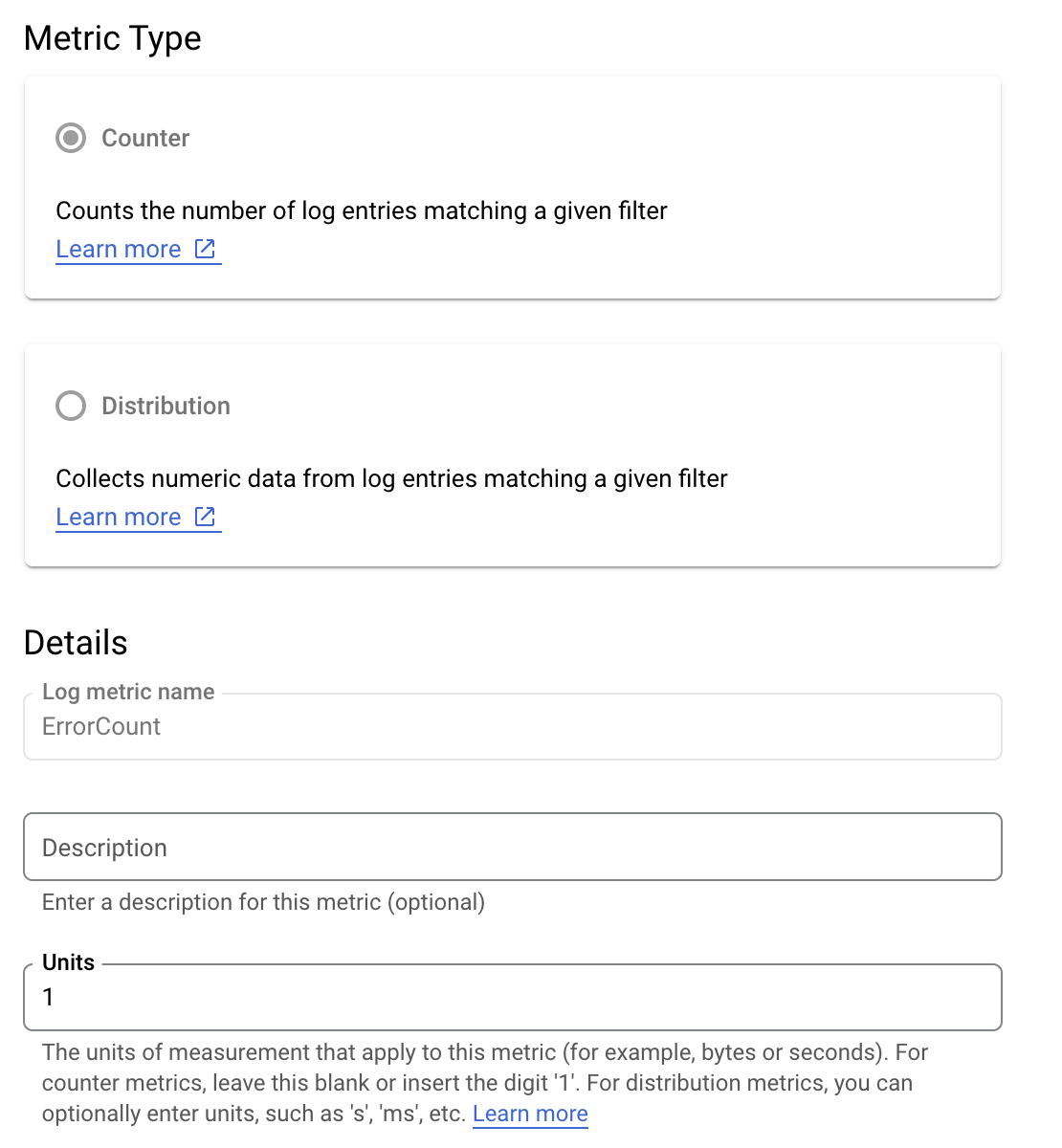

В Cloud Logging метки позволяют группировать показатели по категориям на основе других данных в журналах. Вы можете настроить метку для поля method , отправляемого в Cloud Logging, чтобы посмотреть, как количество ошибок разбивается методом API Google Рекламы.
Настроив метрику ErrorCount и метку Method , вы можете создать новую диаграмму на панели мониторинга для мониторинга ErrorCount , сгруппированной по Method .
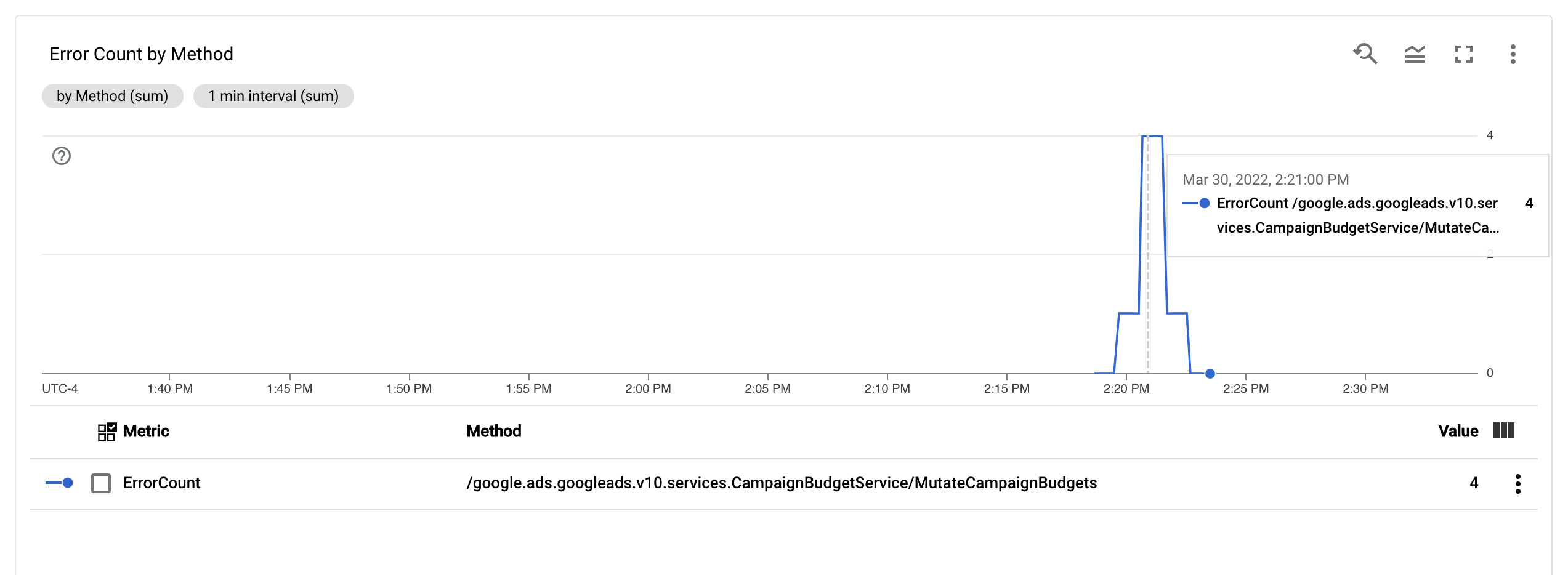
Оповещения
В Cloud Monitoring и других инструментах можно настроить политики оповещений, которые определяют, когда и как оповещения должны запускаться по вашим метрикам. Инструкции по настройке оповещений Cloud Monitoring см. в руководстве по оповещениям .