
L'optimisation des performances commence par l'identification des métriques clés, généralement liées à la latence et au débit. L'ajout d'une surveillance pour capturer et suivre ces métriques met en évidence les points faibles de l'application. Avec les métriques, vous pouvez optimiser les métriques de performances.
De plus, de nombreux outils de surveillance vous permettent de configurer des alertes pour vos métriques afin d'être averti lorsque vous atteignez un certain seuil. Par exemple, vous pouvez configurer une alerte pour être averti lorsque le pourcentage de requêtes ayant échoué augmente de plus de x% par rapport aux niveaux normaux. Les outils de surveillance peuvent vous aider à identifier les performances normales et les pics inhabituels de latence, des quantités d'erreurs et d'autres métriques clés. La possibilité de surveiller ces métriques est particulièrement importante pendant les périodes critiques pour l'entreprise ou après le déploiement en production d'un nouveau code.
Identifier les métriques de latence
Assurez-vous que votre UI est aussi réactive que possible, en sachant que les utilisateurs attendent des applications mobiles des normes encore plus élevées. La latence doit également être mesurée et suivie pour les services de backend, en particulier, car elle peut entraîner des problèmes de débit si elle n'est pas contrôlée.
Voici quelques métriques suggérées à suivre:
- Durée de la requête
- Durée de la requête au niveau de la granularité du sous-système (par exemple, les appels d'API)
- Durée du job
Identifier les métriques de débit
Le débit correspond au nombre total de requêtes traitées sur une période donnée. Le débit peut être affecté par la latence des sous-systèmes. Vous devrez peut-être optimiser la latence pour améliorer le débit.
Voici quelques suggestions de métriques à suivre:
- Requêtes par seconde
- Taille des données transférées par seconde
- Nombre d'opérations d'E/S par seconde
- Utilisation des ressources, comme l'utilisation du processeur ou de la mémoire
- Taille de la file d'attente de traitement, comme Pub/Sub ou le nombre de threads
et non pas seulement la moyenne ;
Une erreur courante lors de la mesure des performances consiste à ne regarder que la moyenne. Bien que cela soit utile, cela ne fournit pas d'informations sur la distribution de la latence. Il est préférable de suivre les percentiles de performances, par exemple le 50e/75e/90e/99e percentile pour une métrique.
En général, l'optimisation peut se faire en deux étapes. Commencez par optimiser pour la latence du 90e percentile. Ensuite, examinez le 99e centile, également appelé latence de queue: la petite partie des requêtes qui prennent beaucoup plus de temps à être traitées.
Surveillance côté serveur pour des résultats détaillés
Le profilage côté serveur est généralement préférable pour suivre les métriques. Le côté serveur est généralement beaucoup plus facile à instrumenter, permet d'accéder à des données plus précises et est moins sujet aux perturbations liées à des problèmes de connectivité.
Surveillance des navigateurs pour une visibilité de bout en bout
Le profilage du navigateur peut fournir des insights supplémentaires sur l'expérience utilisateur finale. Il peut indiquer les pages qui génèrent des requêtes lentes, que vous pouvez ensuite mettre en corrélation avec la surveillance côté serveur pour une analyse plus approfondie.
Google Analytics fournit une surveillance prête à l'emploi des temps de chargement des pages dans le rapport "Temps de chargement des pages". Vous disposez ainsi de plusieurs vues utiles pour comprendre l'expérience utilisateur sur votre site, en particulier:
- Temps de chargement des pages
- Temps de chargement des redirections
- Délais de réponse du serveur
Surveillance dans le cloud
De nombreux outils vous permettent de capturer et de surveiller les métriques de performances de votre application. Par exemple, vous pouvez utiliser Google Cloud Logging pour consigner les métriques de performances dans votre projet Google Cloud, puis configurer des tableaux de bord dans Google Cloud Monitoring pour surveiller et segmenter les métriques enregistrées.
Consultez le guide de journalisation pour obtenir un exemple de journalisation dans Google Cloud Logging à partir d'un intercepteur personnalisé dans la bibliothèque cliente Python. Une fois ces données disponibles dans Google Cloud, vous pouvez créer des métriques sur les données journalisées pour obtenir une visibilité sur votre application via Google Cloud Monitoring. Suivez le guide sur les métriques basées sur les journaux définies par l'utilisateur pour créer des métriques à l'aide des journaux envoyés à Google Cloud Logging.
Vous pouvez également utiliser les bibliothèques du client Monitoring pour définir des métriques dans votre code et les envoyer directement à Monitoring, séparément des journaux.
Exemple de métriques basées sur les journaux
Supposons que vous souhaitiez surveiller la valeur is_fault pour mieux comprendre les taux d'erreur dans votre application. Vous pouvez extraire la valeur is_fault des journaux dans une nouvelle métrique de compteur, ErrorCount.
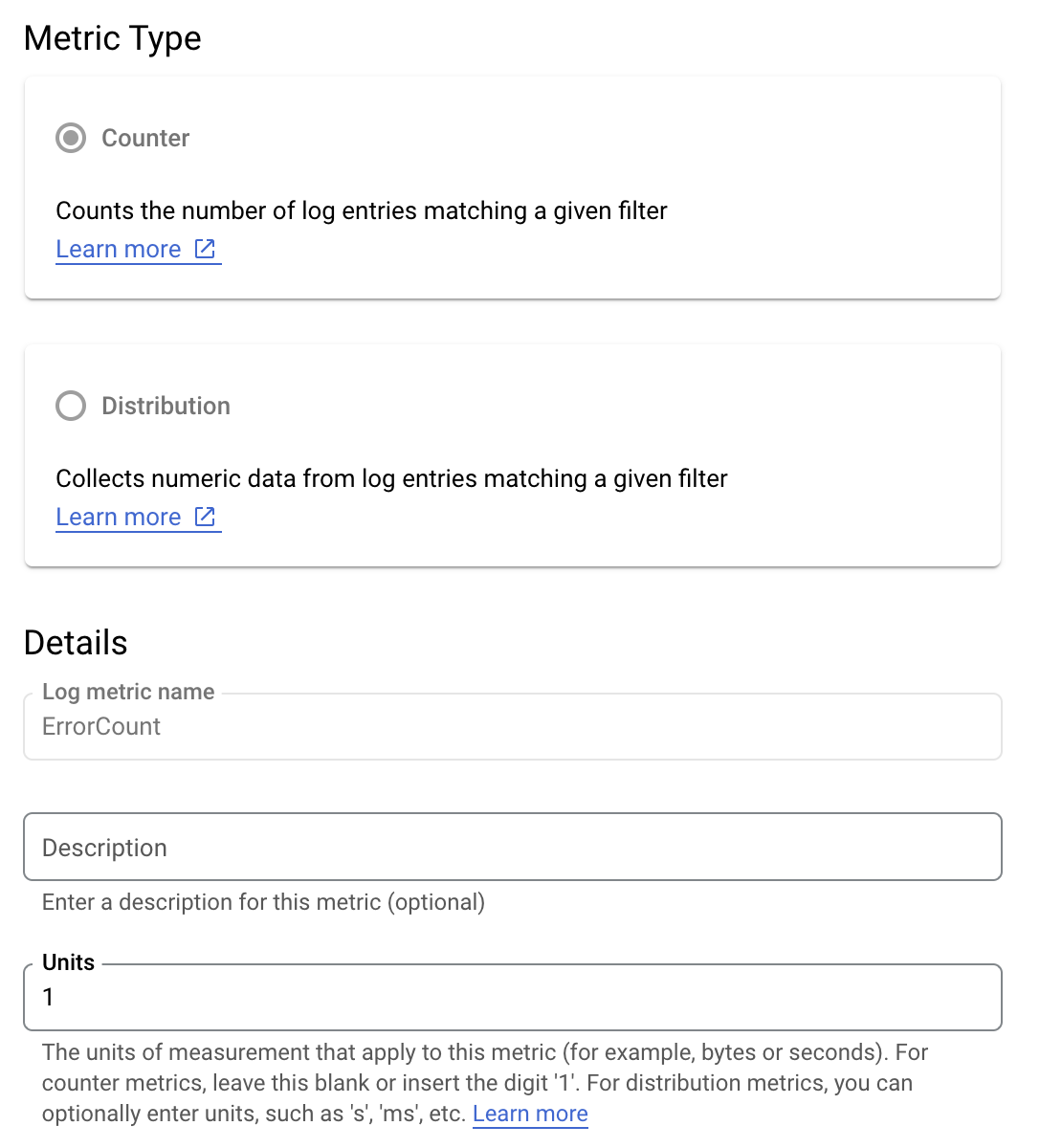
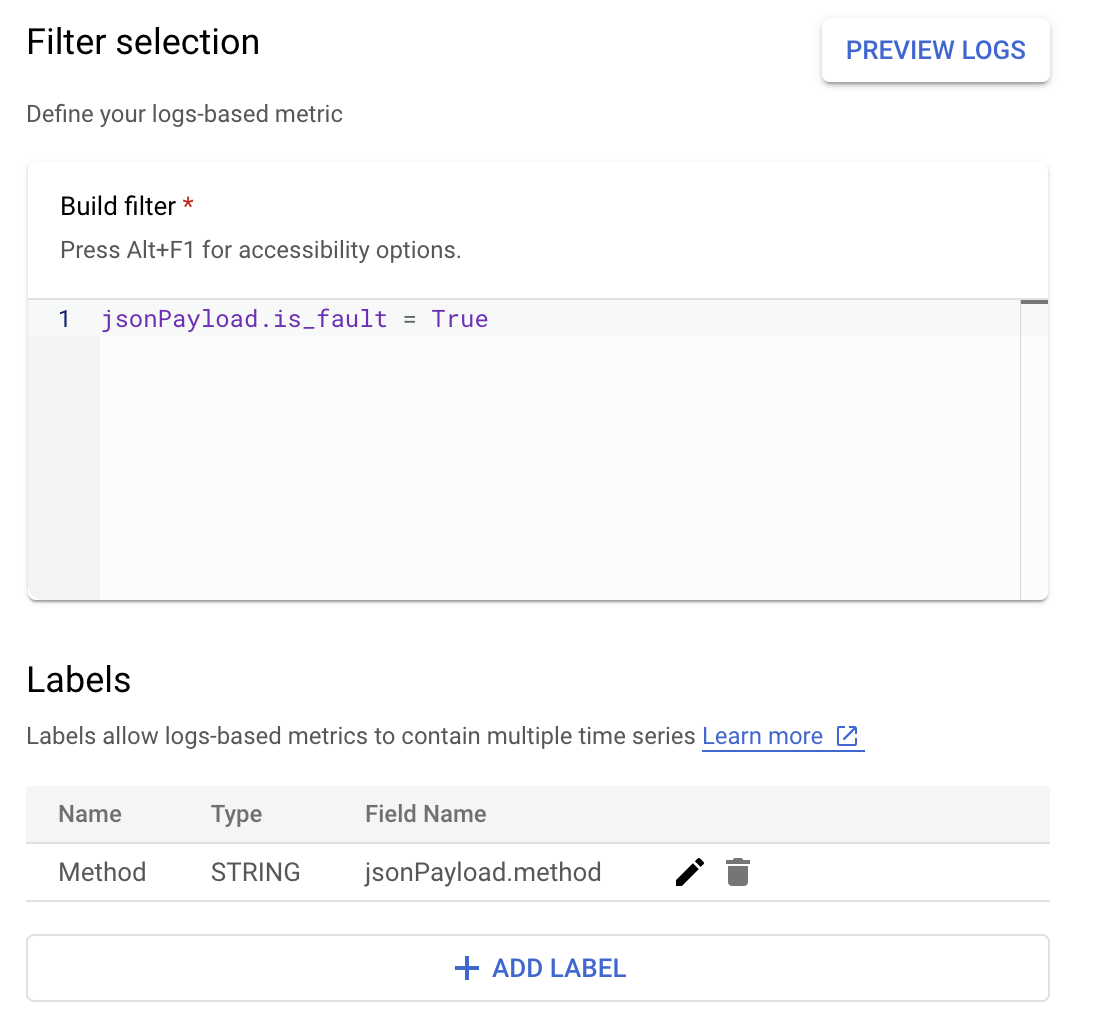
Dans Cloud Logging, les libellés vous permettent de regrouper vos métriques en catégories en fonction d'autres données des journaux. Vous pouvez configurer un libellé pour le champ method envoyé à Cloud Logging afin d'examiner la répartition du nombre d'erreurs par méthode de l'API Google Ads.
Une fois la métrique ErrorCount et le libellé Method configurés, vous pouvez créer un graphique dans un tableau de bord Monitoring pour surveiller ErrorCount, regroupé par Method.
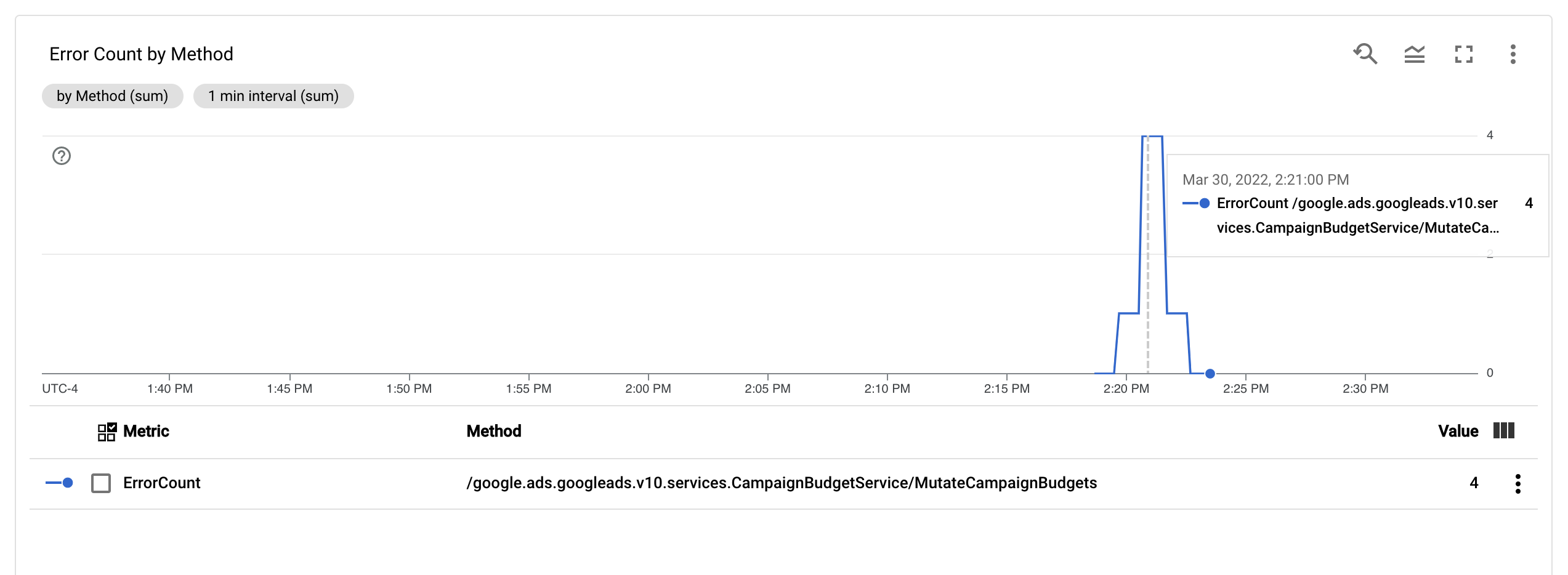
Alertes
Dans Cloud Monitoring et d'autres outils, vous pouvez configurer des règles d'alerte qui spécifient quand et comment les alertes doivent être déclenchées par vos métriques. Pour savoir comment configurer des alertes Cloud Monitoring, consultez le guide des alertes.