
A otimização de desempenho começa com a identificação das principais métricas, geralmente relacionadas à latência e à taxa de transferência. A adição de monitoramento para capturar e acompanhar essas métricas expõe pontos fracos no aplicativo. Com as métricas, é possível otimizar as métricas de performance.
Além disso, muitas ferramentas de monitoramento permitem configurar alertas para suas métricas, para que você seja notificado quando um determinado limite for atingido. Por exemplo, você pode configurar um alerta para receber notificações quando a porcentagem de solicitações com falhas aumentar mais de x% dos níveis normais. As ferramentas de monitoramento podem ajudar a identificar como é a performance normal e identificar picos incomuns na latência, quantidades de erros e outras métricas importantes. A capacidade de monitorar essas métricas é especialmente importante durante períodos críticos para a empresa ou depois que um novo código é enviado para a produção.
Identificar métricas de latência
Mantenha a interface o mais responsiva possível, já que os usuários esperam padrões ainda mais altos dos apps para dispositivos móveis. A latência também precisa ser medida e monitorada para serviços de back-end, principalmente porque ela pode causar problemas de throughput se não for verificada.
As métricas sugeridas para acompanhar incluem:
- Duração da solicitação
- Solicitar duração na granularidade do subsistema (como chamadas de API)
- Duração do job
Identificar métricas de throughput
A capacidade é uma medida do número total de solicitações atendidas em um determinado período. A taxa de transferência pode ser afetada pela latência dos subsistemas. Portanto, talvez seja necessário otimizar a latência para melhorar a taxa de transferência.
Confira algumas métricas sugeridas para acompanhar:
- Consultas por segundo
- Tamanho dos dados transferidos por segundo
- Número de operações de E/S por segundo
- Utilização de recursos, como CPU ou uso de memória
- Tamanho do backlog de processamento, como pub/sub ou número de linhas
Não apenas a média
Um erro comum na medição de desempenho é olhar apenas para a média (média). Embora isso seja útil, não fornece insights sobre a distribuição de latência. Uma métrica melhor para acompanhar é a porcentagem de desempenho, por exemplo, a 50ª/75ª/90ª/99ª de uma métrica.
Geralmente, a otimização pode ser feita em duas etapas. Primeiro, otimize para a latência do percentil 90. Em seguida, considere o percentil 99, também conhecido como latência de cauda: a pequena parte das solicitações que leva muito mais tempo para ser concluída.
Monitoramento do servidor para resultados detalhados
Em geral, o perfil do lado do servidor é preferido para rastrear métricas. O lado do servidor geralmente é muito mais fácil de instrumentar, permite o acesso a dados mais granulares e é menos sujeito a perturbações devido a problemas de conectividade.
Monitoramento do navegador para visibilidade de ponta a ponta
O perfil do navegador pode fornecer mais insights sobre a experiência do usuário final. Ele pode mostrar quais páginas têm solicitações lentas, que podem ser correlacionadas ao monitoramento do lado do servidor para uma análise mais detalhada.
O Google Analytics oferece monitoramento pronto para uso de tempos de carregamento de página no relatório de tempos de página. Isso oferece várias visualizações úteis para entender a experiência do usuário no seu site, em particular:
- Tempos de carregamento da página
- Tempos de carregamento de redirecionamento
- Tempos de resposta do servidor
Monitoramento na nuvem
Há muitas ferramentas que podem ser usadas para capturar e monitorar as métricas de desempenho do aplicativo. Por exemplo, é possível usar o Google Cloud Logging para registrar métricas de desempenho no projeto do Google Cloud e configurar painéis no Google Cloud Monitoring para monitorar e segmentar as métricas registradas.
Consulte o guia de geração de registros para conferir um exemplo de geração de registros no Google Cloud Logging usando um interceptor personalizado na biblioteca de cliente do Python. Com esses dados disponíveis no Google Cloud, você pode criar métricas com base nos dados registrados para ter visibilidade do seu aplicativo com o Google Cloud Monitoring. Siga o guia de métricas com base em registros definidas pelo usuário para criar métricas usando os registros enviados ao Google Cloud Logging.
Como alternativa, use as bibliotecas de cliente do Monitoring para definir métricas no código e enviá-las diretamente para o Monitoring, separadamente dos registros.
Exemplo de métricas com base em registros
Suponha que você queira monitorar o valor is_fault para entender melhor as taxas de erro
no seu aplicativo. É possível extrair o valor is_fault dos registros
para uma nova métrica de contador, ErrorCount.
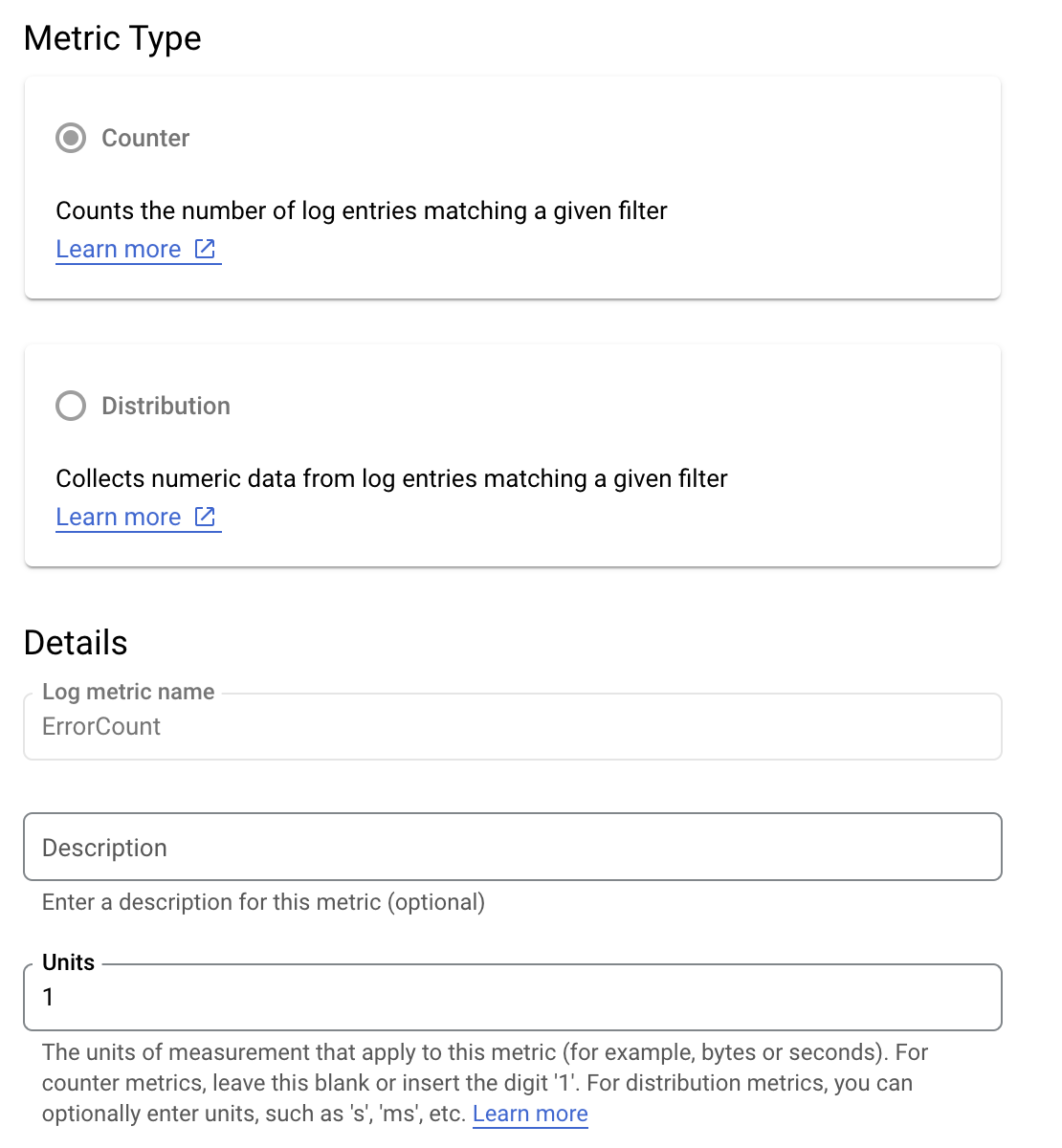
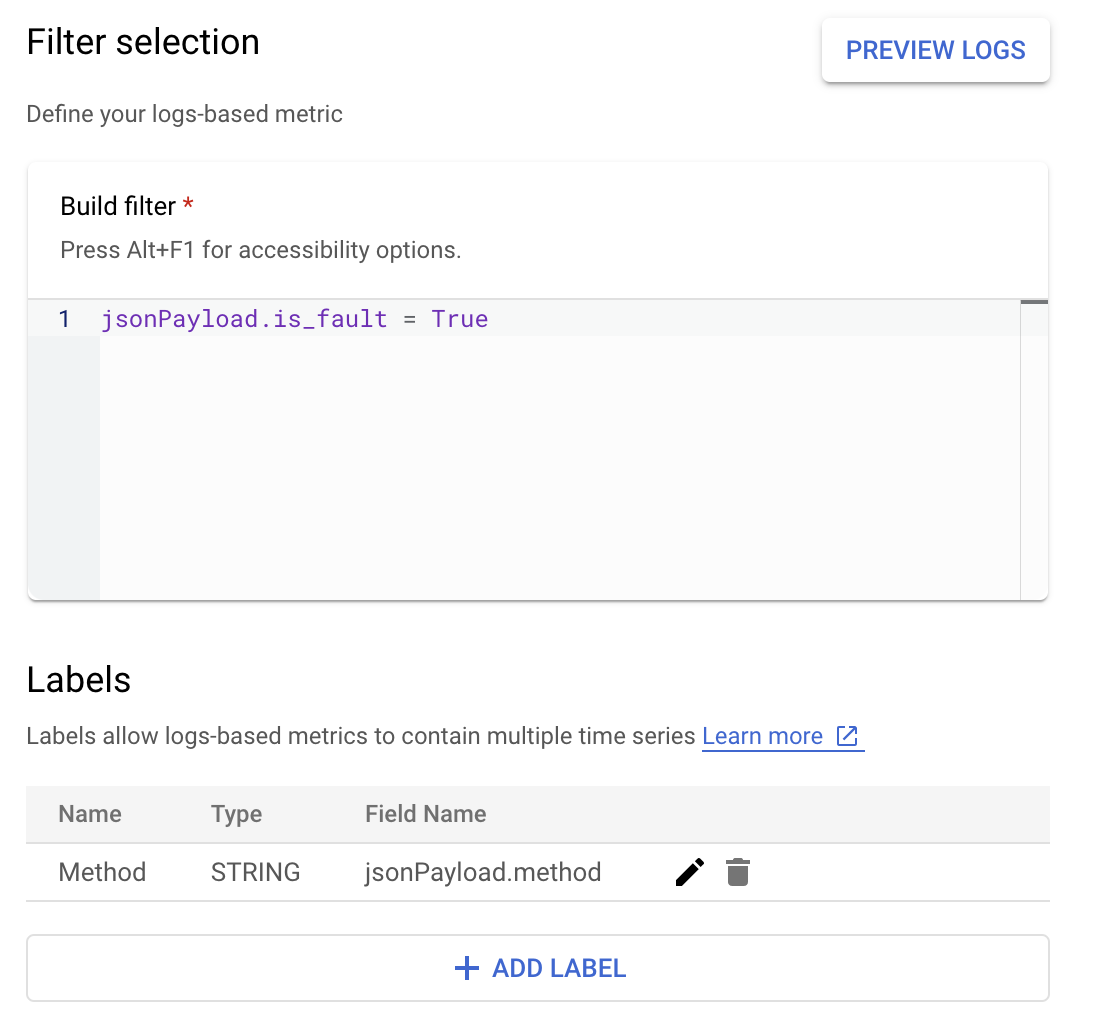
No Cloud Logging, os rótulos permitem agrupar as métricas em categorias
com base em outros dados nos registros. É possível configurar um rótulo para o campo method
enviado ao Cloud Logging para analisar como a contagem de erros é
dividida pelo método da API Google Ads.
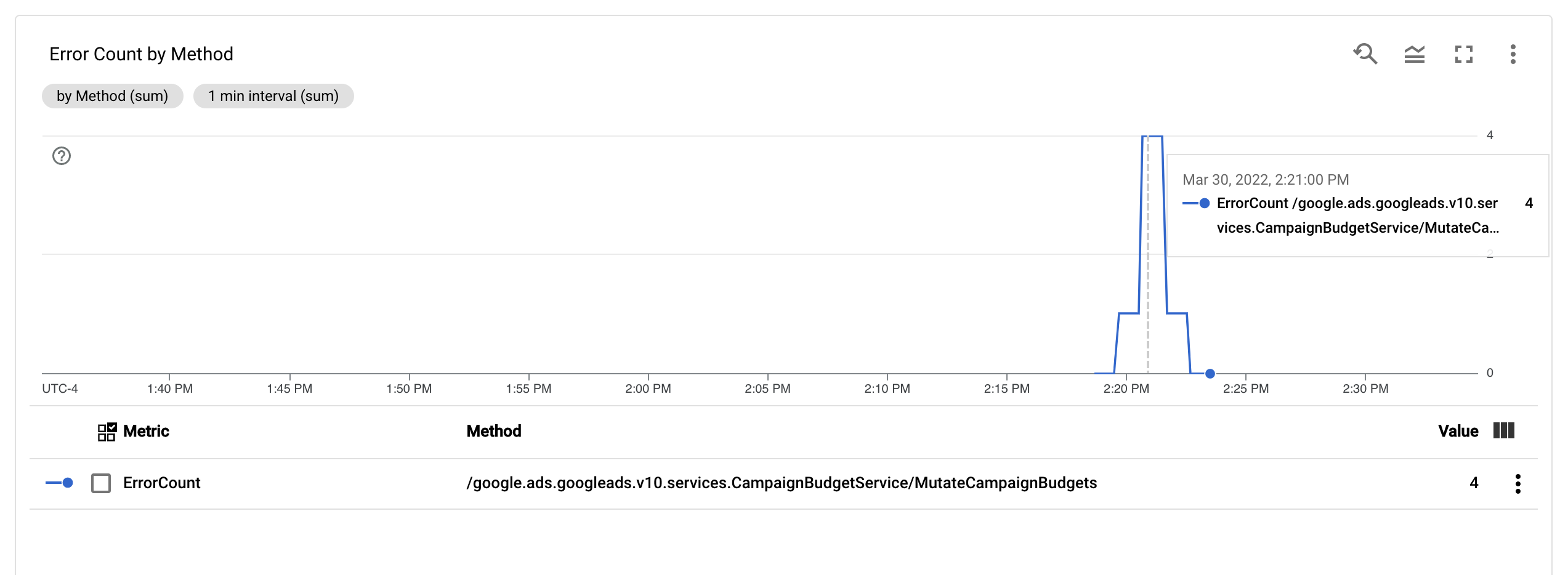
Com a métrica ErrorCount e o rótulo Method configurados, é possível criar
um novo
gráfico em
um painel de monitoramento para monitorar ErrorCount, agrupado por Method.
Alertas
No Cloud Monitoring e em outras ferramentas, é possível configurar políticas de alerta que especificam quando e como os alertas serão acionados pelas métricas. Para instruções sobre como configurar alertas do Cloud Monitoring, siga o guia de alertas.