
Optymalizacja skuteczności zaczyna się od określenia kluczowych wskaźników, zwykle związanych z opóźnieniem i przepustowością. Dodanie monitorowania w celu rejestrowania i śledzenia tych danych ujawnia słabe punkty aplikacji. W przypadku danych można prowadzić optymalizację w celu poprawy wskaźników skuteczności.
Ponadto wiele narzędzi monitorujących umożliwia konfigurowanie alertów dotyczących danych, dzięki czemu otrzymujesz powiadomienia, gdy osiągnięty zostanie określony próg. Możesz na przykład skonfigurować alert, który będzie Cię powiadamiał, gdy odsetek nieudanych żądań wzrośnie o więcej niż x% w porównaniu z normalnym poziomem. Narzędzia monitorujące mogą pomóc Ci określić, jak wygląda normalna wydajność, oraz wykrywać nietypowe skoki opóźnień, liczby błędów i innych kluczowych danych. Możliwość monitorowania tych danych jest szczególnie ważna w krytycznych momentach dla firmy lub po przeniesieniu nowego kodu do środowiska produkcyjnego.
Identyfikowanie wskaźników czasu oczekiwania
Zadbaj o to, aby interfejs był jak najbardziej responsywny. Pamiętaj, że użytkownicy oczekują jeszcze wyższych standardów od aplikacji mobilnych. Opóźnienia powinny być również mierzone i śledzone w przypadku usług backendowych, ponieważ mogą one powodować problemy z przepustowością, jeśli nie zostaną rozwiązane.
Zalecane wskaźniki do śledzenia:
- Czas trwania żądania
- Czas trwania żądania na poziomie szczegółowości podsystemu (np. wywołania interfejsu API)
- Czas trwania zadania
Określanie danych dotyczących przepustowości
Przepustowość to miara łącznej liczby żądań obsłużonych w danym przedziale czasu. Przepustowość może być zależna od opóźnień w subsystemach, dlatego może być konieczne zoptymalizowanie opóźnień w celu zwiększenia przepustowości.
Oto kilka sugerowanych danych do śledzenia:
- Zapytania na sekundę
- Wielkość danych przesyłanych na sekundę
- Liczba operacji wejścia/wyjścia na sekundę
- wykorzystanie zasobów, takich jak procesor lub pamięć;
- Rozmiar kolejki zadań do przetworzenia, np. kolejka pub/sub lub liczba wątków
Nie tylko średnia
Typowym błędem popełnianym przy pomiarze skuteczności jest uwzględnianie tylko średniej (średniej) wartości. Chociaż jest to przydatne, nie dostarcza informacji o rozkładzie opóźnień. Lepszym wskaźnikiem do śledzenia jest skuteczność w procentach, np. 50./75./90./99. procentile.
Optymalizację można przeprowadzić na 2 sposoby. Najpierw zoptymalizuj opóźnienie na poziomie 90 proc. Następnie weź pod uwagę 99. procentyl, czyli opóźnienie na końcu kolejki: niewielką część żądań, które zajmują znacznie więcej czasu.
Monitorowanie po stronie serwera w celu uzyskania szczegółowych wyników
Profilowanie po stronie serwera jest zwykle preferowane w przypadku śledzenia danych. Serwer jest zwykle łatwiejszy do zaprogramowania, umożliwia dostęp do bardziej szczegółowych danych i jest mniej podatny na zakłócenia wynikające z problemów z połączeniem.
Monitorowanie przeglądarki w celu zapewnienia pełnej widoczności
Profilowanie przeglądarki może dostarczyć dodatkowych informacji o wygodzie użytkowników. Może ona pokazywać, które strony mają powolne żądania, co umożliwia ich powiązanie z monitorowaniem po stronie serwera na potrzeby dalszej analizy.
Google Analytics zapewnia gotowe rozwiązanie do monitorowania czasu wczytywania stron w raporcie Czasy wczytywania stron. Dostępne są 2 przydatne widoki, które ułatwiają poznanie wrażeń użytkowników Twojej witryny. Są to:
- Czas wczytywania stron
- Czas wczytywania przekierowania
- Czas odpowiedzi serwera
Monitorowanie w chmurze
Istnieje wiele narzędzi, których możesz używać do rejestrowania i monitorowania danych o wydajności aplikacji. Możesz na przykład użyć Google Cloud Logging do rejestrowania danych o wydajności w projekcie Google Cloud, a następnie skonfigurować panele w Google Cloud Monitoring, aby monitorować i dzielić na segmenty zapisane dane.
Aby zobaczyć przykład logowania do Google Cloud Logging z niestandardowego przechwytu w bibliotece klienta Pythona, zapoznaj się z przewodnikiem po logowaniu. Dzięki tym danym dostępnym w Google Cloud możesz tworzyć dane na podstawie logów, aby uzyskać wgląd w swoją aplikację za pomocą Google Cloud Monitoring. Aby tworzyć wskaźniki za pomocą logów wysyłanych do Google Cloud Logging, postępuj zgodnie z tą instrukcją dotyczącą zdefiniowanych przez użytkownika wskaźników opartych na logach.
Możesz też użyć bibliotek klienta Monitoring, aby definiować dane w kodzie i wysyłać je bezpośrednio do Monitoringu, niezależnie od dzienników.
Przykład wskaźników opartych na logach
Załóżmy, że chcesz monitorować wartość is_fault, aby lepiej poznać współczynniki błędów w aplikacji. Wartość is_fault możesz wyodrębnić z logów i przekazać do nowego wskaźnika licznika, ErrorCount.
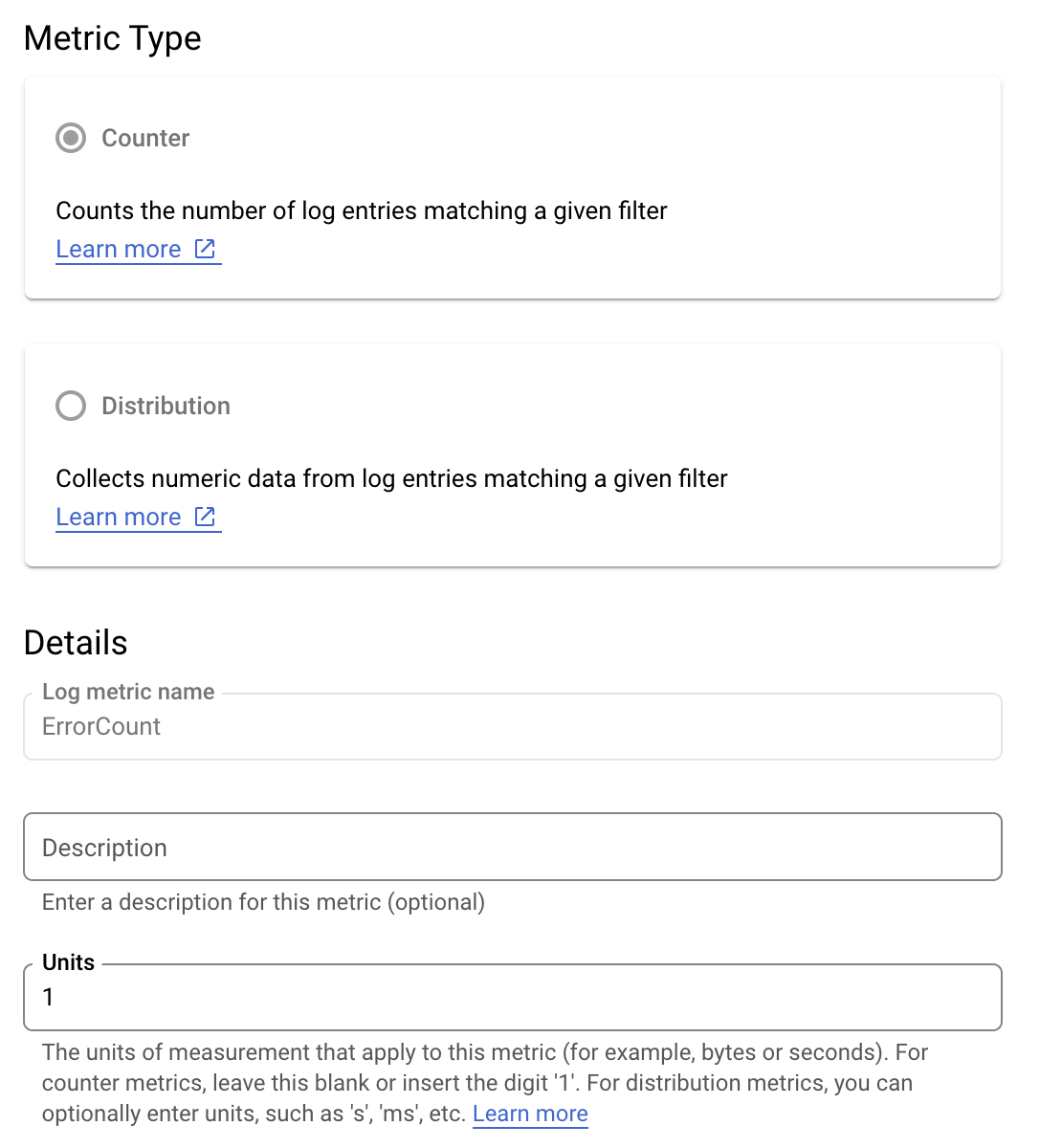
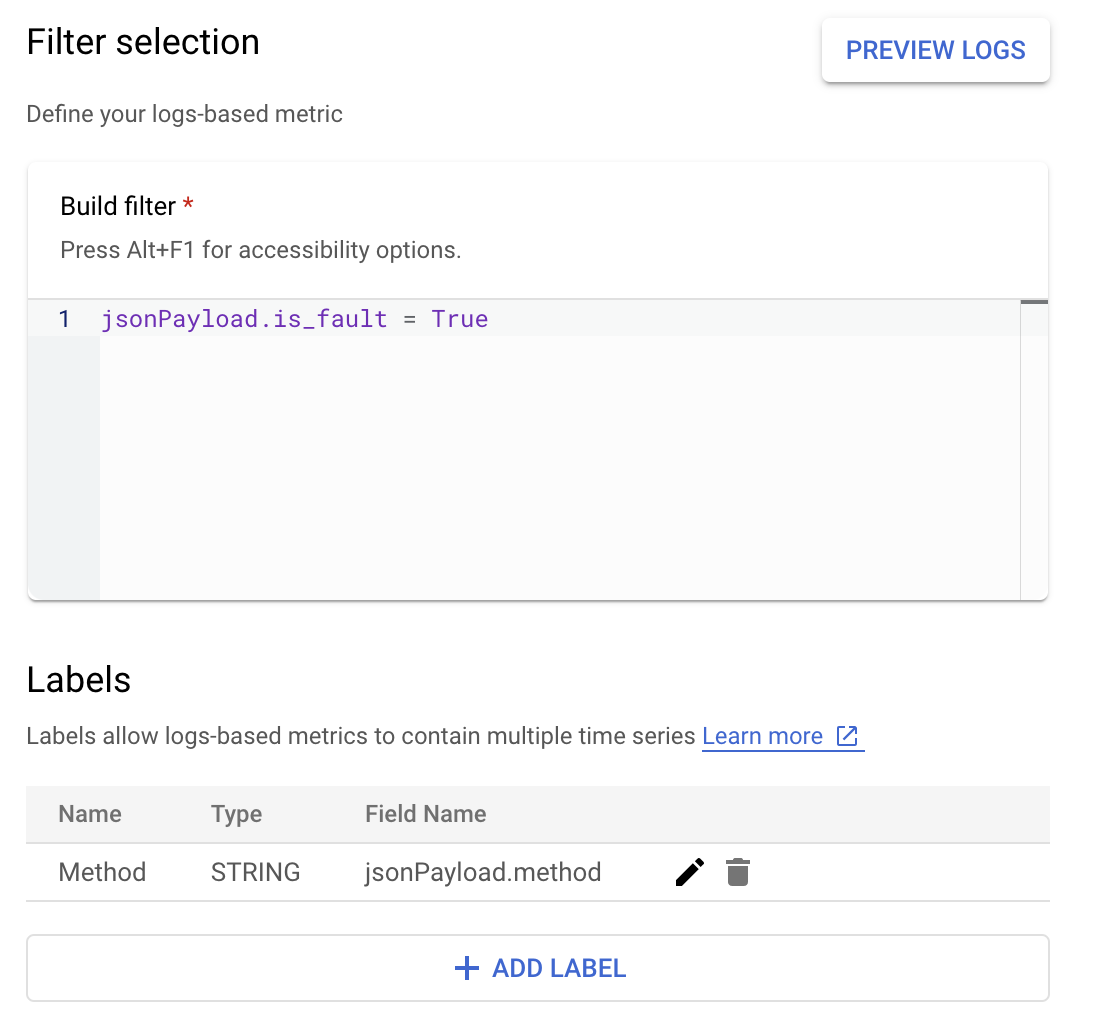
W Cloud Logging etykiety umożliwiają grupowanie danych w kategorie na podstawie innych danych w logach. Możesz skonfigurować etykietę dla pola method przesyłanego do Cloud Logging, aby sprawdzić, jak liczba błędów jest rozbijana według metody interfejsu Google Ads API.
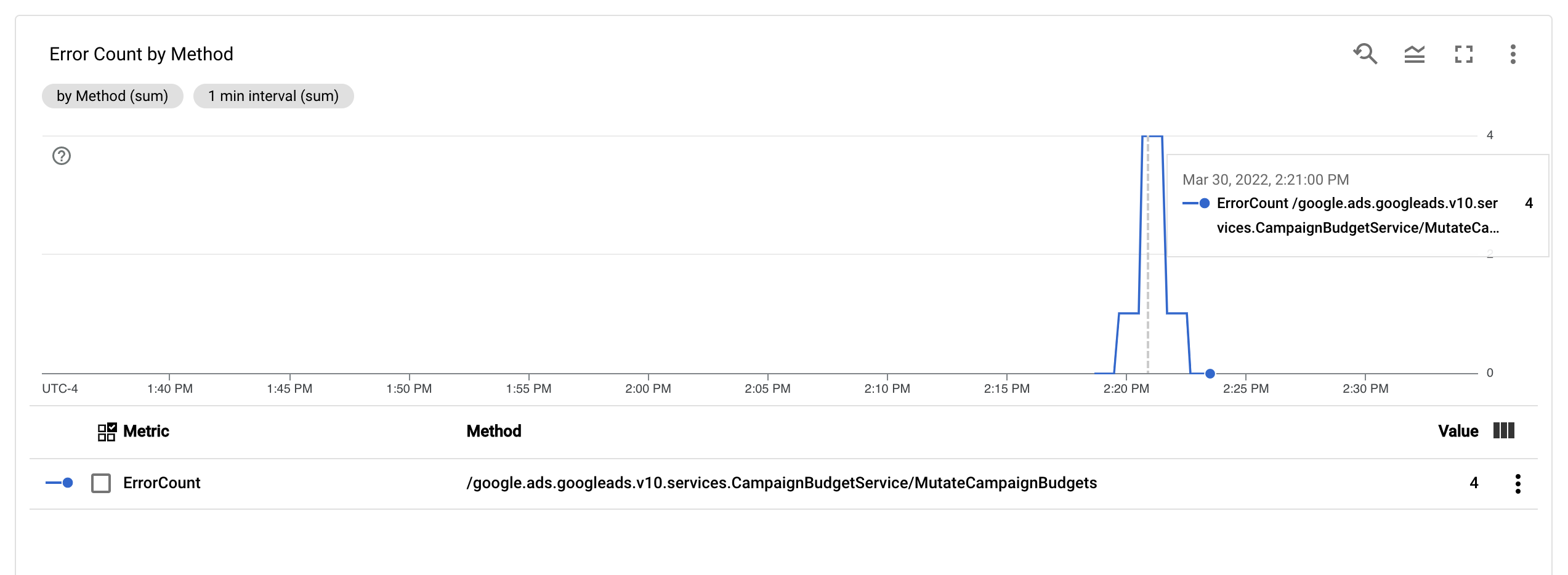
Po skonfigurowaniu danych ErrorCount i etykiety Method możesz utworzyć nowy wykres na panelu Monitorowanie, aby śledzić dane ErrorCount pogrupowane według Method.
Alerty
W Cloud Monitoring i innych narzędziach możesz konfigurować zasady alertów, które określają, kiedy i jak mają być wywoływane przez Twoje dane. Instrukcje konfigurowania alertów Cloud Monitoring znajdziesz w przewodniku po alertach.