вторник, 17 октября 2017 г.
Уровень подготовки веб-мастера: средний или высокий
Если вы добавите на свою веб-старницу ссылку rel=canonical , то это даст поисковым системам сигнал индексировать выбранную вами версию, а не другие схожие страницы . Эту функцию поддерживают многие поисковые системы, в том числе Yahoo! , Bing и Google. Ссылка rel=canonical объединяет свойства индексации всех аналогичных страниц (например, ссылки на сайт), а также указывает на то, какой именно URL должен отображаться в результатах поиска. Однако работать с этим атрибутом бывает непросто, поскольку не всегда очевидно, где допущена ошибка.
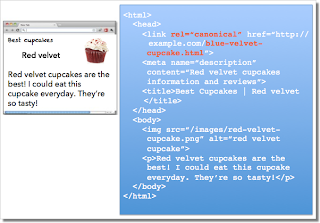 На картинке слева у веб-мастера в браузере открыта страница "Кексы с клубникой", а справа поисковые системы распознают URL страницы "Кексы с черникой", для которой случайно добавлен атрибут rel=canonical.
На картинке слева у веб-мастера в браузере открыта страница "Кексы с клубникой", а справа поисковые системы распознают URL страницы "Кексы с черникой", для которой случайно добавлен атрибут rel=canonical.
Рекомендации по использованию атрибута rel=canonical:
Допустим, у вас есть статья, которая занимает несколько страниц:
 Нужный контент (например, "печенье полезнее" и "чем овощи") теряется, если добавить атрибут rel=canonical, который ведет с последующих страниц на страницу 1.
Нужный контент (например, "печенье полезнее" и "чем овощи") теряется, если добавить атрибут rel=canonical, который ведет с последующих страниц на страницу 1.
Если ваш материал разбит на несколько страниц , мы рекомендуем добавить на них ссылки rel=canonical, ведущие на страницу с полной версией статьи , или воспользоваться разметкой rel="prev" и rel="next" .
 Атрибуты rel=canonical на отдельных страницах, указывающие на статью целиком
Атрибуты rel=canonical на отдельных страницах, указывающие на статью целиком
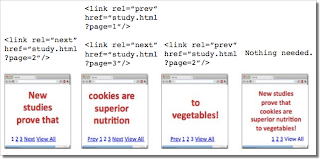 Если нельзя добавить ссылки на страницу с полной версией статьи, воспользуйтесь разметкой rel="prev" и rel="next".
Если нельзя добавить ссылки на страницу с полной версией статьи, воспользуйтесь разметкой rel="prev" и rel="next".
Ошибка 2. Оформление абсолютного URL как относительного
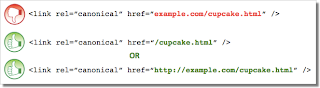
Тег <link>, как и многие другие теги HTML, поддерживает как относительные, так и абсолютные URL. Относительный URL содержит путь, связанный только с текущей страницей. Например, images/cupcake.png означает "перейти из текущего каталога в подкаталог images, а затем открыть файл cupcake.png". Абсолютный URL содержит полный путь, включая протокол (например, https://). Если задан URL <link rel=canonical href="example.com/cupcake.html" /> (это относительный URL, поскольку нет элемента "https://"), система решит, что канонический URL выглядит как https://example.com/example.com/cupcake.html . Но очевидно, что это ошибка. В таких случаях наши алгоритмы могут игнорировать атрибуты rel=canonical. А это значит, что ваши усилия не увенчаются успехом.
Ошибка 3. Лишние или случайно добавленные атрибуты rel=canonical
Иногда мы обнаруживаем атрибуты rel=canonical, которые, вероятно, были добавлены случайно. Как правило, проблема не в опечатках, а в том, что веб-мастер торопится и копирует шаблон страницы, забывая изменить цель атрибута. В результате созданные страницы ссылаются на шаблон сайта.
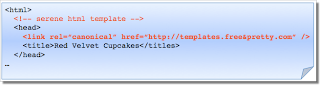 Если вы используете шаблоны, внимательно проверяйте атрибуты rel=canonical.
Если вы используете шаблоны, внимательно проверяйте атрибуты rel=canonical.
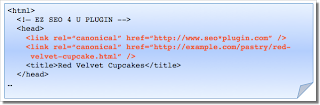
Ошибка 4. Категория или целевая страница содержит ссылку rel=canonical, которая ведет на страницу статьи
Допустим, у вас есть сайт о десертах. На нем используются такие категории материалов, как "выпечка" и "мороженое". Каждый день в этих разделах публикуются уникальные статьи. Например, на целевой странице, посвященной выпечке, речь может идти о кексах с клубникой. Поскольку в исходном разделе размещен примерно тот же контент, что и в статье о кексах, вы решаете добавить ссылку rel=canonical, которая ведет с главной страницы раздела на соответствующую статью.
Если мы примем эту ссылку, то главная страница раздела "выпечка" не будет отображаться в результатах поиска. Почему это происходит? Атрибут rel=canonical сообщает поисковым системам, что нужно отображать указанный URL вместо адреса страницы-дубликата. Если вы хотите, чтобы пользователи могли найти и основной раздел, и новую статью, то лучше добавить ссылку rel=canonical только на страницу категории, указав ее же URL, или вовсе не пользоваться этой функцией.
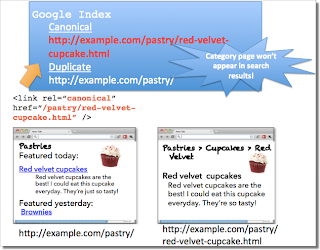 Помните, что эта функция влияет на то, какой URL будет отображаться в результатах поиска. Не используйте атрибуты rel=canonical для перенаправления с целевой страницы или с главной страницы раздела на определенную статью.
Помните, что эта функция влияет на то, какой URL будет отображаться в результатах поиска. Не используйте атрибуты rel=canonical для перенаправления с целевой страницы или с главной страницы раздела на определенную статью.
Ошибка 5. Атрибут rel=canonical в разделе <body>
Тег со ссылкой rel=canonical следует добавлять только в раздел <head> HTML-документа. Кроме того, мы рекомендуем размещать его в начале этого раздела, чтобы избежать проблем с синтаксисом HTML. Атрибуты rel=canonical внутри тега <body> не учитываются системой.
Эту ошибку легко исправить. Просто убедитесь, что ссылки rel=canonical расположены в разделе <head> и как можно ближе к началу кода.

Атрибуты rel=canonical должны быть размещены в разделе <head>, а не <body>.
Заключение
Чтобы правильно настроить атрибут rel=canonical, выполните следующие действия:
Дата публикации на английском: 08 апреля 2013
Если вы добавите на свою веб-старницу ссылку rel=canonical , то это даст поисковым системам сигнал индексировать выбранную вами версию, а не другие схожие страницы . Эту функцию поддерживают многие поисковые системы, в том числе Yahoo! , Bing и Google. Ссылка rel=canonical объединяет свойства индексации всех аналогичных страниц (например, ссылки на сайт), а также указывает на то, какой именно URL должен отображаться в результатах поиска. Однако работать с этим атрибутом бывает непросто, поскольку не всегда очевидно, где допущена ошибка.
Рекомендации по использованию атрибута rel=canonical:
- Контент на основной странице должен по большей части соответствовать дубликату.
- Убедитесь, что цель rel=canonical существует (что это не ошибка или “ soft 404 ”)
- Проверьте, не содержит ли цель rel=canonical метатега noindex для роботов.
- Убедитесь, что добавили атрибут rel=canonical именно на ту страницу, URL которой должен отражаться в результатах поиска, а не на ее дубликат.
- Добавьте ссылку rel=canonical в раздел <head> или в заголовок HTTP.
- Убедитесь, что на страницу добавлено не более одного атрибута rel=canonical. Если атрибутов несколько, то все они будут игнорироваться.
Представьте, что вы не знаете языка, на котором написан текст. Если бы вы разместили дубликат рядом с основной страницей и сравнили их, насколько бы совпало их содержание? Если для того, чтобы счесть два текста одинаковыми, необходимо знать язык (то есть совпадает только тема, но не конкретные фразы и слова), поисковые системы могут не распознать их сходства.
Допустим, у вас есть статья, которая занимает несколько страниц:
- example.com/article?story=cupcake-news&page=1
- example.com/article?story=cupcake-news&page=2
- и т. д.
Если ваш материал разбит на несколько страниц , мы рекомендуем добавить на них ссылки rel=canonical, ведущие на страницу с полной версией статьи , или воспользоваться разметкой rel="prev" и rel="next" .
Ошибка 2. Оформление абсолютного URL как относительного

Тег <link>, как и многие другие теги HTML, поддерживает как относительные, так и абсолютные URL. Относительный URL содержит путь, связанный только с текущей страницей. Например, images/cupcake.png означает "перейти из текущего каталога в подкаталог images, а затем открыть файл cupcake.png". Абсолютный URL содержит полный путь, включая протокол (например, https://). Если задан URL <link rel=canonical href="example.com/cupcake.html" /> (это относительный URL, поскольку нет элемента "https://"), система решит, что канонический URL выглядит как https://example.com/example.com/cupcake.html . Но очевидно, что это ошибка. В таких случаях наши алгоритмы могут игнорировать атрибуты rel=canonical. А это значит, что ваши усилия не увенчаются успехом.
Ошибка 3. Лишние или случайно добавленные атрибуты rel=canonical
Иногда мы обнаруживаем атрибуты rel=canonical, которые, вероятно, были добавлены случайно. Как правило, проблема не в опечатках, а в том, что веб-мастер торопится и копирует шаблон страницы, забывая изменить цель атрибута. В результате созданные страницы ссылаются на шаблон сайта.
Бывает и так, что на страницах обнаруживается несколько ссылок rel=canonical с разными URL. Это может быть связано с плагинами для поисковой оптимизации, которые по умолчанию добавляют ссылку rel=canonical, а веб-мастер и не подозревает об этом. Если атрибутов rel=canonical несколько, то система Google обычно игнорирует их все.
В обоих описанных случаях необходимо проверить исходный код страницы и исправить ошибки. Обязательно просмотрите раздел <head> целиком, так как ссылки rel=canonical могут идти не подряд.
Просмотрите исходный код, чтобы проверить работу плагинов.
Ошибка 4. Категория или целевая страница содержит ссылку rel=canonical, которая ведет на страницу статьи
Допустим, у вас есть сайт о десертах. На нем используются такие категории материалов, как "выпечка" и "мороженое". Каждый день в этих разделах публикуются уникальные статьи. Например, на целевой странице, посвященной выпечке, речь может идти о кексах с клубникой. Поскольку в исходном разделе размещен примерно тот же контент, что и в статье о кексах, вы решаете добавить ссылку rel=canonical, которая ведет с главной страницы раздела на соответствующую статью.
Если мы примем эту ссылку, то главная страница раздела "выпечка" не будет отображаться в результатах поиска. Почему это происходит? Атрибут rel=canonical сообщает поисковым системам, что нужно отображать указанный URL вместо адреса страницы-дубликата. Если вы хотите, чтобы пользователи могли найти и основной раздел, и новую статью, то лучше добавить ссылку rel=canonical только на страницу категории, указав ее же URL, или вовсе не пользоваться этой функцией.
Ошибка 5. Атрибут rel=canonical в разделе <body>
Тег со ссылкой rel=canonical следует добавлять только в раздел <head> HTML-документа. Кроме того, мы рекомендуем размещать его в начале этого раздела, чтобы избежать проблем с синтаксисом HTML. Атрибуты rel=canonical внутри тега <body> не учитываются системой.
Эту ошибку легко исправить. Просто убедитесь, что ссылки rel=canonical расположены в разделе <head> и как можно ближе к началу кода.

Атрибуты rel=canonical должны быть размещены в разделе <head>, а не <body>.
Заключение
Чтобы правильно настроить атрибут rel=canonical, выполните следующие действия:
- Проверьте, совпадают ли в целом текстовые материалы на основной и дублирующей страницах.
- Убедитесь, что атрибут rel=canonical задан только один раз и расположен в разделе <head>.
- Убедитесь, что ссылка rel=canonical ведет на существующую страницу с контентом (то есть не на страницу ошибки 404 или, что ещё хуже, програмной ошибки 404).
- Не настраивайте перенаправление rel=canonical с целевых страниц или главных страниц разделов на опубликованные статьи, поскольку при этом в результатах поиска будут отображаться только URL этих статей.
Дата публикации на английском: 08 апреля 2013