2014年5月28日星期三
原文:
Rendering pages with Fetch as Google
作者: Shimi Salant, 网站站长工具小组
作者: Shimi Salant, 网站站长工具小组
利用
网站站长工具中的Google抓取方式功能
,网站站长可查看Googlebot在尝试抓取其网页时会获得的结果。所显示的服务器标头和HTML有助于诊断技术问题以及黑客攻击的负面影响,但有时会使仔细检查响应变得非常困难:
求助!所有这些代码都意味着什么?这确实是我在浏览器中看到的网页吗?我们去哪儿吃午饭?
对于最后这个问题,我们爱莫能助;但为了帮助您解决前两个问题,我们最近对此工具进行了扩展,以便其同时显示Googlebot呈现网页的方式。
查看呈现的网页
为了呈现网页,Googlebot将尝试找到并抓取所有涉及到的外部文件。这些文件通常包括图片、CSS和JavaScript文件,以及可能通过CSS或JavaScript间接嵌入的其他文件。然后,Googlebot将使用这些文件呈现一个预览图片,以便显示Googlebot看到的网页。
您可以在
Google网站站长工具
的“抓取”部分中找到
Google抓取方式功能
。通过“抓取并呈现”功能提交网址后,请等待系统对其进行处理(对于某些网页,此过程可能需要一些时间)。等处理完后,您只需点击响应行即可查看结果。
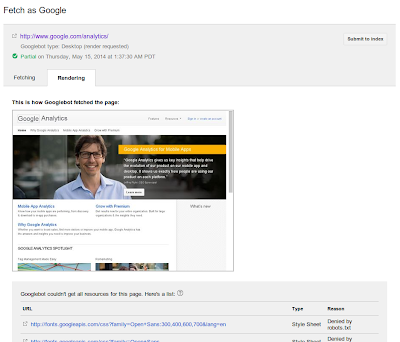
处理通过robots.txt阻止抓取的资源
Googlebot抓取的所有文件都是按照
robots.txt指令
抓取的。如果您禁止Googlebot抓取其中的某些文件(或者如果这些文件是通过禁止Googlebot抓取这些文件的第三方服务器嵌入的),那么我们将无法在呈现的视图中显示这些文件。同样,如果服务器返回错误或无法响应,我们将无法使用这些文件(您可以在网站站长工具的
抓取错误
部分找到类似问题)。如果我们遇到任何此类问题,都会将其显示在预览图片的下方。
我们建议您确保Googlebot可以访问任何有益于呈现网站可见内容或版式的嵌入资源。这可让您更轻松地使用Google抓取方式,并使Googlebot能够找到相应内容并将其编入索引。某些类型的内容(例如社交媒体按钮、字体或网站分析脚本)对于呈现网站可见内容或版式并无帮助,因此您可以禁止Googlebot抓取这些内容。有关详情,请查看我们之前发布的有关
Google在采取什么方式来更好地了解网页
的博文。
我们希望此次更新能够帮助您更轻松地诊断这些类型的问题,并能让能更轻松地发现被意外阻止抓取的内容。如有任何意见或疑问,您可以在此处告诉我们,也可以在
网站站长帮助论坛
中发帖。