Dienstag, 27. Mai 2014
Über die
Funktion "Abruf wie durch Google" in den Webmaster-Tools
können Webmaster nachvollziehen, wie der Googlebot ihre Seiten abruft. Die Serverheader und der HTML-Code, die angezeigt werden, helfen bei der Diagnose von technischen Problemen und Nebeneffekten von Hackerangriffen. Manchmal erschweren sie aber auch das Überprüfen der Antwort:
Hilfe!
Was bedeutet all dieser Code?
Ist das wirklich dieselbe Seite, die ich in meinem Browser sehe?
Wo wollen wir Mittag essen?
Bei der letzten Frage können wir zwar nicht helfen, aber für die übrigen haben wir dieses Tool kürzlich so erweitert, dass ihr sehen könnt, wie der Googlebot die Seite rendern würde.
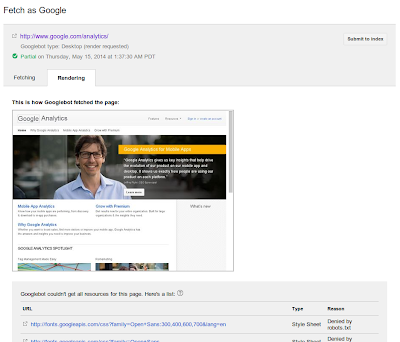
Umgang mit von robots.txt blockierten Ressourcen
Wir hoffen, dass euch dieses Update die Diagnose solcher Probleme erleichtert und bei der Erkennung von Inhalten hilft, deren Crawling versehentlich blockiert wurde. Wenn ihr Kommentare oder Fragen habt, könnt ihr diese hier oder im Forum für Webmaster posten.
Post von Shimi Salant, Webmaster Tools team
(Veröffentlicht von Johannes Mehlem , Search Quality Team)
Gerenderte Seite ansehen
Zum Rendern der Seite sucht der Googlebot nach allen zugehörigen externen Dateien und versucht, sie ebenfalls abzurufen. Bei diesen Dateien handelt es sich oft um Bilder, CSS- und JavaScript-Dateien sowie sonstige Dateien, die indirekt über den CSS- oder JavaScript-Code eingebettet sein können. Anschließend wird mit ihrer Hilfe ein Vorschaubild gerendert, das die Sicht des Googlebots auf die Seite wiedergibt.
Ihr findet die
Funktion "Abruf wie durch Google"
im Abschnitt "Crawling" der
Google Webmaster-Tools
. Wartet nach dem Senden einer URL mittels "Abrufen und rendern" auf deren Verarbeitung. Dies kann bei manchen Seiten einen Moment dauern. Sobald die Seite verarbeitet wurde, klickt ihr auf die Antwortzeile, um euch die Ergebnisse anzusehen.
Umgang mit von robots.txt blockierten Ressourcen
Der Googlebot richtet sich bei allen Dateien, die er abruft, nach den
Anweisungen in der robots.txt-Datei
. Wenn ihr das Crawling einiger dieser Dateien nicht gestattet oder wenn sie über einen Server eines Drittanbieters eingebettet werden, der das Crawling durch den Googlebot unterbindet, können wir euch die Dateien nicht in der gerenderten Ansicht zeigen. Wir können sie ebenfalls nicht verwenden, wenn der Server nicht antwortet oder Fehler zurückgibt. Solche Probleme sind in den Webmaster-Tools im Abschnitt
Crawling-Fehler
aufgeführt. Wenn wir auf eines dieser Probleme stoßen, weisen wir unterhalb des Vorschaubilds darauf hin.
Wir empfehlen euch daher, dafür zu sorgen, dass der Googlebot auf alle eingebetteten Ressourcen zugreifen kann, die für die sichtbaren Inhalte oder das Layout eurer Website wichtig sind. Zum einen erleichtert euch das die Verwendung von "Abruf wie durch Google", zum anderen kann der Googlebot dann diese Inhalte finden und indexieren. Einige Inhaltstypen – z. B. Schaltflächen sozialer Medien, Schriftarten oder Skripts zur Websiteanalyse – sind für die sichtbaren Inhalte oder das Layout oft weniger bedeutsam und ihr Crawling kann daher weiterhin untersagt bleiben. Weitere Informationen findet ihr im vorherigen Blogpost zum
neuen Verfahren von Google zur besseren Analyse des Webs
.
Wir hoffen, dass euch dieses Update die Diagnose solcher Probleme erleichtert und bei der Erkennung von Inhalten hilft, deren Crawling versehentlich blockiert wurde. Wenn ihr Kommentare oder Fragen habt, könnt ihr diese hier oder im Forum für Webmaster posten.
(Veröffentlicht von Johannes Mehlem , Search Quality Team)