2014年5月28日水曜日
ウェブマスター ツールの Fetch as Google 機能
を使用すると、Googlebot がどのようにページを取得しているかを確認できます。ここで表示されるサーバー ヘッダーや HTMLは、技術的問題やハッキングの影響を診断するのに役立ちますが、その理解が難しい場合もあるでしょう。「このコードの意味は何?」、「本当に自分のブラウザで見ているのと同じページなんだろうか?」「今日の昼ごはんはどこで食べよう?」...。昼ごはんをどこで食べるかについてはお助けできませんが、他の問題を解決するために、このたび Google はウェブマスター ツールを拡張し、Google がページをどのようにレンダリングしているかを確認できるようにしました。
レンダリングされたページを表示する
Googlebot は、ページをレンダリングする際、そのページに関係するすべての外部ファイルをできるだけ見つけて取得しようとします。その際、画像、CSS、JavaScript ファイルだけでなく、CSS や JavaScript によって間接的に埋め込まれるファイルも取得した上で、Googlebot のページ認識のプレビュー画像を描画することになります。
Fetch as Google 機能
は、
ウェブマスター ツール
の [クロール] セクションにあります。[取得してレンダリング] をクリックして URL を送信して処理が完了するのを待ちます(ページによっては少し時間がかかる場合があります)。処理が完了したら、表示された行をクリックして結果を確認します。
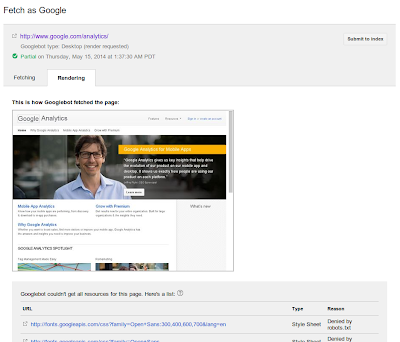
robots.txt によってブロックされたリソースの取り扱い
Googlebot は、すべてのファイルを
robots.txt の指示
に従って取得します。クロールを許可していないファイルがある場合(または、Googlebot のクロールが許可されていないサードパーティ サーバーからファイルを埋め込んでいる場合)、そのファイルはレンダリング時に利用できません。同じように、サーバーが応答しない場合やエラーが返された場合も、それらのファイルを利用することはできません(こうした問題の詳細は、ウェブマスター ツールの [
クロール エラー
] セクションで確認できます)。こうした問題が発生した場合は、プレビュー画像の下に詳細が表示されます。
サイトに表示されるコンテンツやそのレイアウトに大きく影響する埋め込みリソースについては、Googlebot がアクセスできるかどうかを確認しておくことをおすすめします。Fetch as Google が使いやすくなるだけでなく、Googlebot がそれらのコンテンツを見つけてインデックスに登録することが可能になります。サイトに表示されるコンテンツやそのレイアウトにあまり影響しない一部のコンテンツ タイプ(ソーシャル メディア ボタン、フォント、ウェブサイト分析スクリプトなど)は、クロールできない状態のままでも構いません。詳しくは、以前ブログに投稿した「
ウェブページをより深く理解するようになりました
」という記事をご覧ください。
今回のアップデートによって問題の診断が容易になり、誤ってクロールがブロックされていたコンテンツが発見され、クロールされるようになることを願っております。ご不明な点やご意見などありましたら、
ウェブマスター ヘルプ フォーラム
までお寄せください。