miércoles, 22 de abril de 2009
Los editores web nos preguntan a menudo cómo aumentar la visibilidad en la web. Gran parte de esto tiene que ver con la optimización para motores de búsqueda, es decir, asegurarse de que su contenido aparece en todos los motores de búsqueda.
Sin embargo, hay algunos casos en los que los editores necesitan comunicar más información a los motores de búsqueda, como por ejemplo qué contenido no quieren que aparezca en los resultados de búsqueda. Y con este fin se utiliza el protocolo de exclusión de robots [inglés] , que permite a los editores controlar la manera en la que los motores de búsqueda acceden a su sitio: ya sea controlando la visibilidad del contenido de su sitio (a través de robots.txt) o a nivel mucho más detallado, para páginas específicas (a través de meta etiquetas).
Desde que se introdujo a principios de los años 90, el protocolo de exclusión de robots se ha convertido en el estándar para que los editores web especifiquen qué partes de su web quieren mantener públicas y qué partes quieren mantener privadas. Hoy en día, millones de editores lo utilizan para comunicarse con los motores de búsqueda de manera fácil y eficiente. Su fuerza reside en su flexibilidad para evolucionar en paralelo con la web, su aplicación universal por parte de los principales robots y motores de búsqueda, así como en la forma en la que funciona para cualquier editor, sin importar si se trata de un editor grande o pequeño.
Aunque prácticamente todos los motores de búsqueda siguen el protocolo de exclusión de robots, nunca hemos llegado a poner juntas y en detalle las diferentes interpretaciones para las etiquetas. Durante los últimos años, hemos trabajado con Microsoft y Yahoo! para sacar adelante normas como Sitemaps [inglés] y para ofrecer herramientas adicionales a los webmasters. Desde el anuncio inicial, hemos ofrecido y seguiremos ofreciendo nuevas mejoras basadas en los comentarios de la comunidad.
Hoy, con el mismo propósito de hacer más sencilla la vida a los webmasters, publicamos documentación detallada sobre la mejora del protocolo de exclusión de robots. Esto hará que todos los webmasters lo apliquen de manera similar y también servirá de ayuda a los editores el hecho de conocer cómo los tres principales proveedores de búsqueda tratan las directivas para el protocolo de exclusión de robots, haciendo así que éste sea más intuitivo y fácil de usar para todos aquellos que publican en la web.
Entonces, sin más demora...
Directivas comunes del protocolo de exclusión de robots
La siguiente lista contiene las principales funciones del protocolo de exclusión llevadas a cabo por Google, Microsoft y Yahoo!. Con cada función, se indica qué hace y cómo se debe comunicar.
Cada una de estas directivas se puede especificar para que se aplique a todos los rastreadores o a algunos de ellos en concreto, apuntando a un agente de usuario específico, que es su modo de identificación. Cada uno de nuestros rastreadores también admite la autenticación por DNS inversa para verificar la identidad del rastreador.
1. 1. Directivas de Robots.txt
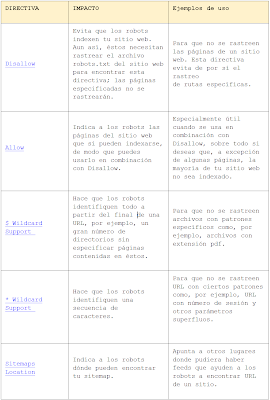
2. 2. Meta directivas HTML
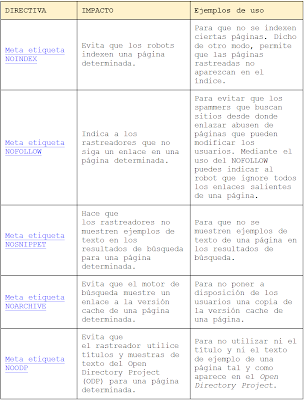
Estas directrices se aplican a todo tipo de contenidos. Las puedes poner tanto en el código HTML de una página como en el encabezado HTTP para contenidos que no son HTML, tales como PDF, vídeo, etc, usando la etiqueta X-Robots. Aquí tienes más información: Artículo sobre la etiqueta X-Robots [inglés] o en nuestra serie de entradas [inglés] sobre el uso de robots y las meta etiquetas.
Otras directivas del protocolo de exclusión de robots
Microsoft, Google y Yahoo! utilizan las directivas que hemos mencionado, pero puede que éstas no sean válidas para otros motores de búsqueda. Además, existen las siguientes directivas que sólo ofrece Google:
UNAVAILABLE_AFTER Meta Tag - Indica al robot cuando debe caducar una página [inglés] , es decir, la fecha tras la cual no debe aparecer en los resultados de búsqueda.
NOIMAGEINDEX Meta Tag - Indica al rastreador que no indexe las imágenes de una página determinada en los resultados de búsqueda.
NOTRANSLATE Meta Tag - Indica al rastreador que no traduzca el contenido de una página a otros idiomas [inglés] para los resultados de búsqueda.
De cara al futuro, tenemos previsto seguir trabajando para que, cada vez que surjan nuevas directivas de protocolo de exclusión de robots, los webmasters puedan usarlas con facilidad. ¡Así que no olvides visitarnos con frecuencia!
Información adicional
Puedes encontrar más información acerca de robots.txt en https://www.robotstxt.org/ [inglés] y en el Centro de Asistencia para Webmasters de Google , que contiene una gran cantidad de información útil, que incluye:
Para ver lo que nuestros colegas dicen al respecto, también puedes visitar los blogs de Yahoo! [inglés] y Microsoft [inglés] .
Sin embargo, hay algunos casos en los que los editores necesitan comunicar más información a los motores de búsqueda, como por ejemplo qué contenido no quieren que aparezca en los resultados de búsqueda. Y con este fin se utiliza el protocolo de exclusión de robots [inglés] , que permite a los editores controlar la manera en la que los motores de búsqueda acceden a su sitio: ya sea controlando la visibilidad del contenido de su sitio (a través de robots.txt) o a nivel mucho más detallado, para páginas específicas (a través de meta etiquetas).
Desde que se introdujo a principios de los años 90, el protocolo de exclusión de robots se ha convertido en el estándar para que los editores web especifiquen qué partes de su web quieren mantener públicas y qué partes quieren mantener privadas. Hoy en día, millones de editores lo utilizan para comunicarse con los motores de búsqueda de manera fácil y eficiente. Su fuerza reside en su flexibilidad para evolucionar en paralelo con la web, su aplicación universal por parte de los principales robots y motores de búsqueda, así como en la forma en la que funciona para cualquier editor, sin importar si se trata de un editor grande o pequeño.
Aunque prácticamente todos los motores de búsqueda siguen el protocolo de exclusión de robots, nunca hemos llegado a poner juntas y en detalle las diferentes interpretaciones para las etiquetas. Durante los últimos años, hemos trabajado con Microsoft y Yahoo! para sacar adelante normas como Sitemaps [inglés] y para ofrecer herramientas adicionales a los webmasters. Desde el anuncio inicial, hemos ofrecido y seguiremos ofreciendo nuevas mejoras basadas en los comentarios de la comunidad.
Hoy, con el mismo propósito de hacer más sencilla la vida a los webmasters, publicamos documentación detallada sobre la mejora del protocolo de exclusión de robots. Esto hará que todos los webmasters lo apliquen de manera similar y también servirá de ayuda a los editores el hecho de conocer cómo los tres principales proveedores de búsqueda tratan las directivas para el protocolo de exclusión de robots, haciendo así que éste sea más intuitivo y fácil de usar para todos aquellos que publican en la web.
Entonces, sin más demora...
Directivas comunes del protocolo de exclusión de robots
La siguiente lista contiene las principales funciones del protocolo de exclusión llevadas a cabo por Google, Microsoft y Yahoo!. Con cada función, se indica qué hace y cómo se debe comunicar.
Cada una de estas directivas se puede especificar para que se aplique a todos los rastreadores o a algunos de ellos en concreto, apuntando a un agente de usuario específico, que es su modo de identificación. Cada uno de nuestros rastreadores también admite la autenticación por DNS inversa para verificar la identidad del rastreador.
1. 1. Directivas de Robots.txt
2. 2. Meta directivas HTML
Estas directrices se aplican a todo tipo de contenidos. Las puedes poner tanto en el código HTML de una página como en el encabezado HTTP para contenidos que no son HTML, tales como PDF, vídeo, etc, usando la etiqueta X-Robots. Aquí tienes más información: Artículo sobre la etiqueta X-Robots [inglés] o en nuestra serie de entradas [inglés] sobre el uso de robots y las meta etiquetas.
Otras directivas del protocolo de exclusión de robots
Microsoft, Google y Yahoo! utilizan las directivas que hemos mencionado, pero puede que éstas no sean válidas para otros motores de búsqueda. Además, existen las siguientes directivas que sólo ofrece Google:
UNAVAILABLE_AFTER Meta Tag - Indica al robot cuando debe caducar una página [inglés] , es decir, la fecha tras la cual no debe aparecer en los resultados de búsqueda.
NOIMAGEINDEX Meta Tag - Indica al rastreador que no indexe las imágenes de una página determinada en los resultados de búsqueda.
NOTRANSLATE Meta Tag - Indica al rastreador que no traduzca el contenido de una página a otros idiomas [inglés] para los resultados de búsqueda.
De cara al futuro, tenemos previsto seguir trabajando para que, cada vez que surjan nuevas directivas de protocolo de exclusión de robots, los webmasters puedan usarlas con facilidad. ¡Así que no olvides visitarnos con frecuencia!
Información adicional
Puedes encontrar más información acerca de robots.txt en https://www.robotstxt.org/ [inglés] y en el Centro de Asistencia para Webmasters de Google , que contiene una gran cantidad de información útil, que incluye:
- Cómo crear un archivo robots.txt
- Las descripciones de los agentes de usuario que Google utiliza
- Cómo utilizar la identificación de patrones
-
Con qué frecuencia se rastrea el archivo robots.txt
- Uso de archivos robots.txt [inglés]
- Todo sobre Googlebot [inglés]
Para ver lo que nuestros colegas dicen al respecto, también puedes visitar los blogs de Yahoo! [inglés] y Microsoft [inglés] .