viernes, 6 de noviembre de 2009
Estamos entusiasmados de poder proponer un nuevo estándar para poder hacer rastreables los sitios web basados en AJAX. Esto beneficiará a webmasters y usuarios, por hacer que contenidos ricos e interactivos basados en AJAX estén disponibles de manera universal a través de los resultados de búsqueda o de cualquier motor de búsqueda que participe. Creemos que hacer disponible este contenido para rastreo e indexación puede mejorar de manera significativa la web.
Si bien las páginas web basadas en AJAX son populares entre los usuarios, los motores de búsqueda tradicionales no son capaces de acceder a este tipo de contenido. La última vez que revisamos, casi el 70% de los sitios web que conocemos utilizaban JavaScript de alguna manera. Por supuesto, la mayoría de ese JavaScript no es AJAX, pero cuanto mejor se pueda rastrear e indexar AJAX, más desarrolladores podrán añadir características más completas a sus sitios web y seguir apareciendo en los motores de búsqueda.
Algunos de los objetivos que queremos alcanzar con esta propuesta son:
- Realizar cambios mínimos que son necesarios conforme crece la web.
- Visualización de un mismo contenido por parte de usuarios y motores de búsqueda (no encubrimiento o cloaking).
- Posibilidad por parte de los motores de búsqueda de enviar a los usuarios directamente a la URL de AJAX (no a una copia estática).
- Verificación de sitios web en AJAX por parte de los propietarios de una forma correcta, de manera que el rastreador tenga acceso a todo el contenido.
Así es como los motores de búsqueda rastrean e indexan AJAX de acuerdo con nuestra propuesta inicial:
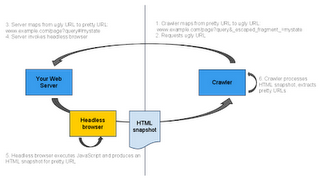
- Modificar ligeramente los fragmentos de URL para obtener páginas AJAX con estado: Las páginas en AJAX con estado muestran el mismo contenido cada vez que se accede a éste directamente. Se trata de páginas que podrían aparecer en los resultados de búsqueda. En lugar de una URL como https://example.com/page?query#state , nos gustaría añadir una marca para poder reconocer estas URL: https://example.com/page?query#[FRAGMENTTOKEN]state . Basándonos en una revisión de las URL que actualmente hay en la web, se propone utilizar "!" (Un signo de exclamación) para marcarlas. La URL propuesta que podría mostrarse en los resultados de búsqueda sería entonces: https://example.com/page?query#!state .
- Utilizar un navegador sin interfaz gráfica que produzca una instantánea en HTML en el servidor web: El navegador sin interfaz gráfica se utiliza para acceder a la página AJAX y genera el código HTML basado en el estado final del navegador. Sólo las URL especialmente etiquetadas se pasan al navegador sin interfaz gráfica para que se procesen. Al hacer esto, por parte del servidor, el propietario del sitio web controla el código HTML que se genera y se puede verificar fácilmente que el JavaScript se está ejecutando correctamente. Un ejemplo de navegadores de este tipo es HtmlUnit , un navegador de código abierto para programas Java sin interfaz gráfica.
- Permitir que los rastreadores de los motores de búsqueda accedan a estas URL omitiendo el estado: Como los fragmentos de URL no se envían con las solicitudes a los servidores, es necesario modificar ligeramente la dirección URL utilizada para acceder a la página. Al mismo tiempo, esto indica al servidor que utilice el navegador sin interfaz gráfica para generar código HTML en lugar de devolver una página con JavaScript. Otras URL existentes (como las que utilizan los usuarios) se procesan con normalidad, evitando el navegador sin interfaz gráfica. Proponemos omitir la información de estado y agregarla a los parámetros de consulta con un símbolo. Utilizando el ejemplo anterior, una URL sería https://example.com/page?query&[QUERYTOKEN]=estado . Basándonos en nuestro análisis actual de las URL en la web, proponemos utilizar "_escaped_fragment_" como fragmento. La dirección URL propuesta sería entonces https://example.com/page?query&_escaped_fragment_=state .
- Mostrar la URL original a los usuarios en los resultados de búsqueda: Para mejorar la experiencia del usuario, tiene sentido enviar a los usuarios directamente a las páginas en AJAX. Esto se puede lograr mostrando la URL original (como https://example.com/page?query#!state de nuestro ejemplo anterior) en los resultados de búsqueda. Los motores de búsqueda pueden comprobar que el texto indexable devuelto a Googlebot es el mismo o un fragmento de texto que se devuelve a los usuarios.
En resumen, a partir de una URL con estado como
https://example.com/dictionary.html#AJAX
, podría estar disponible tanto para los rastreadores como para los usuarios
https://example.com/dictionary.html#!AJAX
, que podría ser rastreado como
https://example.com/dictionary.html?_escaped_fragment_=AJAX
, que a su vez se mostraría a los usuarios y sería accesible como
https://example.com/dictionary.html#!AJAX
Ver la presentación
[inglés]
Actualmente estamos trabajando en una propuesta y un prototipo de aplicación. Se agradecerán todos los comentarios que nos hagáis. No dudéis en añadir
vuestras opiniones
en la sección de comentarios a continuación, o en nuestro
Foro para webmasters
. ¡Gracias por vuestro interés en hacer una web basada en AJAX accesible y útil a través de los motores de búsqueda!